










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkActa Médica Costarricense
On-line version ISSN 0001-6002Print version ISSN 0001-6012
Acta méd. costarric vol.49 n.2 San José Apr. 2007
¿Hay diferencias significativas entre tratamientos? Primera parte
Jorge Camacho-Sandoval
Los investigadores en ciencias de la salud se hacen preguntas como: ¿Se deben las diferencias entre muestras al efecto de los tratamientos?, ¿se deben las diferencias al criterio de clasificación de los grupos, por ejemplo al sexo, grupo edad o etnia?, o simplemente, ¿se deben las diferencias a que las muestras están compuestas por individuos distintos?, dicho de otra manera, ¿se deben las diferencias al azar o son estadísticamente significativas?
Como se mencionó en la nota estadística anterior1 cuando se estudian muestras lo más frecuente es encontrar diferencias entre éstas, aunque hayan recibido el mismo tratamiento. Eso ocurre debido a que los individuos que componen cada muestra son diferentes, al menos parcialmente.
El problema básico es entonces, determinar si las diferencias observadas entre muestras son debidas al azar o, por el contrario, se pueden atribuir a los tratamientos o criterios de clasificación. Dos de las herramientas que la estadística ofrece para resolver ese problema son la estimación por intervalos y las pruebas de hipótesis.2
El caso más simple sería cuando se quiere comparar un grupo o muestra con un valor de referencia. Veamos un ejemplo: Se evalúa el consumo energético en una muestra de 11 mujeres, se obtuvo un consumo promedio de 6753.6 Kjulios y una desviación estándar de 1142.1 Kjulios. Se desea determinar si el consumo energético en la población de mujeres de donde procede la muestra difiere del consumo recomendado por la OMS, que es de 7725 Kjulios.
Una posibilidad es realizar una prueba de hipótesis, que consta de 4 elementos, a saber: la hipótesis nula (H0),la hipótesis alternativa (H1), un estadístico de prueba y la regla de decisión.
La H0 es,en general, que no existe diferencia significativa, es decir, que la diferencia observada se debe al azar. La H1 es lo contrario, es decir, supone que la diferencia observada es significativa. No se hace referencia ni a la dirección ni a la magnitud de la diferencia, lo que indica que haremos una prueba de dos colas, es decir, se supone que la diferencia puede ser positiva o negativa. En general, esta es la mejor forma de hacer la prueba.
El estadístico de prueba tiene que tener dos características básicas, primero, debe ser obtenido a partir de los datos de la muestra y segundo se debe conocer su distribución de probabilidad. En el caso de promedios, diferencias entre promedios, proporciones y diferencias entre proporciones, si la variable se distribuye normalmente o si el tamaño de muestra es 30 ó superior, los estimadores siguen la distribución normal, la famosa campana de Gauss. Con muestras pequeñas, esos indicadores siguen otra distribución, la de t de Student. Como la distribución de t se aproxima a la distribución normal al crecer el tamaño de muestra, se puede usar, para los casos mencionados, la distribución de t; la forma general de un estadístico de prueba s:
Estadístico prueba= Valor observado del estimador - Valor del estimado según H0
Error estándar del estimador
El criterio de decisión es probabilístico. Si la probabilidad del estadístico de prueba es pequeña, suponiendo que la H0 es cierta, menor que un valor arbitrario establecido previamente por el investigador, entonces se rechaza la H0 y se acepta como válida la H1.
En el caso del ejemplo mencionado, los componentes de la prueba de hipótesis son:
H0: La diferencia poblacional entre el valor del estimador (6753.6 Kjulios) y el valor recomendado por la OMS (7725 Kjulios) no es significativa, se debe al azar.
H1: La diferencia poblacional entre el valor del estimador (6753.6 Kjulios) y el valor recomendado por la OMS (7725 Kjulios) es significativa.
Estadístico de prueba:

Regla de decisión: Si la probabilidad de t es inferior al 5% (0.05), rechazo la H0; en los demás casos, no se rechaza H0. ¿Cómo obtener la probabilidad del estadístico de prueba? Se puede utilizar la función DISTR.T de la hoja de cálculo Excel, introduciendo la siguiente información en el cuadro de diálogo correspondiente (Figura 1):
X: valor del estadístico, en este caso, 2.82
Grados de libertad: tamaño de muestra – 1 =11 – 1 =10
Colas: 2
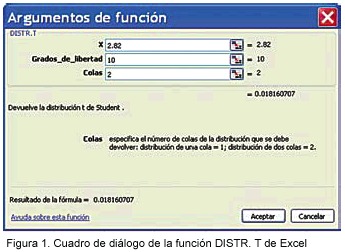
La probabilidad del estadístico de prueba es 0.01816, es decir, inferior a 0.05, por lo que aplicando la regla de decisión, se rechaza H0 y se acepta H1 como válida y se concluye que, a nivel de la población, la diferencia entre el consumo energético de mujeres y el consumo recomendado por la OMS es significativa.
Una forma alternativa de abordar el problema es estimar un intervalo de confianza para el promedio, esto es, un rango de valores dentro del cual se supone, con un nivel de confianza o probabilidad predeterminado, que se encuentra el promedio de la población de la cual procede la muestra. Si el valor de referencia se encuentra dentro de ese intervalo, se concluye que la diferencia entre el promedio poblacional y el valor de referencia se debe al azar. Si por el contrario, el valor de referencia no se encuentra dentro del intervalo de confianza, se concluye que la diferencia entre ambos valores es significativa.
La estructura general de un intervalo de confianza es la siguiente:

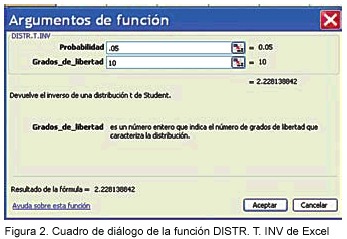
En el ejemplo mencionado se tiene un tamaño de muestra n =11, por lo tanto, se debe usar la distribución de t. Para ello es preciso buscar el valor correspondiente a 10 grados de libertad, es decir, n -1, y un nivel de confianza determinado. Ese valor se obtiene usando la función DISTR.T.INV de Excel; la información se introduce en la caja de diálogo (Figura 2), como sigue:
Probabilidad: 1 –Nivel de confianza deseado, por ejemplo, 1 -0.95 =0.05
Grados de libertad: tamaño de muestra – 1 =11 – 1 =10
El valor resultante es: 2.228
En el ejemplo, el intervalo de confianza para el estimado del promedio poblacional será:

Es decir, el promedio poblacional se encuentra, con un 95% de confianza, entre 5986.37 y 7520.82 Kjulios. Como el intervalo no contiene el valor recomendado por la OMS de 7725 Kjulios, se concluye que el consumo promedio de las mujeres en la población es significativamente menor al recomendado por la OMS. En la próxima nota, se extenderán estas técnicas a la comparación de dos grupos.
Referencias
1. Camacho J. Investigación, poblaciones y muestra. Act Med Costarric, 49:11-12. [ Links ]
2. Zar, J. H. Biostastical análisis. 4th ed. New Jersey: Prentice Hall, 1999. [ Links ]
Profesor, Maestría en Epidemiología, Posgrado en Ciencias Veterinarias, UNA.
Correspondencia:
Correo lectrónico: jcamacho@ice.co.cr

