











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkConfiabilidad y consistencia interna desde la Teoría Clásica de los Tests
En el marco de la construcción y la adaptación de instrumentos, la validez y la confiabilidad constituyen las principales propiedades psicométricas desde la Teoría Clásica de los Tests (TCT) (Mikulic, 2007). La TCT plantea la existencia de una puntuación empírica obtenida mediante la administración de un test, que se compone por una puntuación verdadera y el error de medida (Muñiz, 2010). La idea subyacente consiste en que, al administrar un test infinitas veces, el promedio del error de medida sería cero y se obtendría una puntuación verdadera. De manera que una técnica confiable es aquella que maximiza la puntuación verdadera de manera consistente y precisa (Mikulic, 2007).
Desde la óptica de la TCT, la confiabilidad refiere al grado en el que una repetición hipotética de la misma medida daría los mismos resultados (Muñiz, 2010). El coeficiente de confiabilidad es definido como la razón de la varianza de la puntuación verdadera y la varianza de la puntuación observada al ser la puntuación observada la suma de la puntuación verdadera y la varianza del error (Lord & Novick, 1968).
De manera que la confiabilidad pretende acercar a una prueba a una puntuación libre de errores. En este sentido, la variabilidad que pudiera haber en el error como consecuencia de la influencia de cualquier variable, cambiaría el valor del coeficiente de confiabilidad (Dunn et al., 2014). Por lo tanto, la confiabilidad no estaría únicamente asociada a la prueba que se esté estudiando, sino también a la muestra y el contexto de administración (Dunn et al., 2014; Thurstone, 1928).
La confiabilidad puede definirse, también, como la correlación entre una prueba y otra prueba igual, por lo que su cálculo requeriría de una segunda prueba (Revelle & Zinbarg, 2009). La realización de distintas administraciones implica una serie de complicaciones logísticas y costos, que ha originado la elaboración de alternativas para analizar la estructura interna de un instrumento mediante una sola administración (McNeish, 2018; Revelle & Zinbarg, 2009). Ello ha generado la formulación de concepciones propias de la consistencia interna (McDonald, 1981; Raykov & Marcoulides, 2019; Sijtsma & van der Ark, 2015). Sin embargo, la consistencia interna frecuentemente se encuentran ligadas al coeficiente alfa.
Según Revelle (1979), la consistencia interna puede definirse como el grado en que todos los elementos o reactivos de una prueba miden el mismo constructo. Sin embargo, se ha considerado innecesaria la distinción de la consistencia interna de manera distinta de la confiabilidad (Raykov & Marcoulides, 2019), al igual que a la concepción de distintos tipos de confiabilidad (Raykov, 2012).
El alfa, el omega y coeficientes alternativos para estimar la confiabilidad
El coeficiente alfa fue propuesto, por primera vez, por Guttman (1945) y popularizado por Cronbach (1951). Históricamente, ha sido el más utilizado para analizar la confiabilidad, por su facilidad para comunicarlo, su estimación mediante una sola aplicación de una prueba y por su presencia en distintos softwares estadísticos (Viladrich et al., 2017).
Sin embargo, el cálculo del alfa exige la presencia de supuestos cuyo cumplimiento resulta complejo en situaciones reales: la tau-equivalencia, la unidimensionalidad y la ausencia de errores correlacionados (McNeish, 2018; Raykov, 1998). Sin embargo, en tanto estos supuestos se cumplan, el coeficiente alfa es recomendado (Raykov & Marcoulides, 2019; Savalei et al., 2019). A su vez, en caso de incumplirse la tau-equivalencia, el coeficiente alfa puede aproximarse al mayor límite inferior de confiabilidad (Cronbach, 1951; Trizano-Hermosilla & Alvarado, 2016; Sijtsma, 2009).
Revelle y Zinbarg (2009) han sugerido al coeficiente omega total (McDonald, 1999) como un estimador alternativo del mayor límite inferior de confiabilidad correspondiente a modelos congenéricos.
También, el omega total requiere unidimensionalidad y ausencia de errores correlacionados (Domínguez Lara, 2016; Savalei et al., 2019), aunque suele ser más estable por calcularse a partir de cargas factoriales (Ventura-León, 2018). Flora (2020) y Trizano-Hermosilla y Alvarado (2016) han recomendado reportar el omega jerárquico, que permite calcular la proporción de la varianza de los elementos de la escala en relación con el factor general para determinar el grado en que los puntajes sumados de los ítems están saturados por el factor general (Green & Yang, 2015). De manera que el omega jerárquico resulta más adecuado cuando el modelo subyacente a los datos es bifactorial o con un factor de segundo orden (Flora, 2020). Sin embargo, para instrumentos que tienen una estructura establecida con varias dimensiones, que no están fuertemente correlacionadas, se recomienda el cálculo del alfa o el omega total para cada dimensión (Savalei et al., 2019).
En cuanto a la relación entre omega total y alfa, los valores suelen ser ligeramente más elevados en el omega (Revelle & Zinbarg, 2009), aunque no suele haber grandes diferencias en la práctica (Deng & Chang, 2017). Incluso, ambos coeficientes comparten la característica de que la adición de ítems provocaría el aumento del valor del coeficiente de confiabilidad. (Cortina, 1993; Hair et al., 2014).
Es decir, que antes de elegir un coeficiente de confiabilidad deberán examinarse la dimensionalidad del instrumento y el ajuste de los modelos congenéricos y tau equivalente a los datos. Al comprender que el modelo tau equivalente implica la restricción o la similitud de las cargas factoriales en el contexto de un análisis factorial y que el modelo congenérico permite que los valores varíen libremente (Dunn et al., 2014; Viladrich et al., 2017)
Otro de los coeficientes recomendados (McNeish, 2018), cuando el modelo congenérico exhibe un ajuste adecuado, es el H (Hancock & Mueller, 2001). El coeficiente H se calcula en el contexto de análisis factoriales confirmatorios y se distingue de otros coeficientes, fundamentalmente, porque utiliza las puntuaciones ponderadas de la escala, en lugar de las no ponderadas (Aguirre-Urreta et al., 2019;
McNeish, 2018; Savalei et al., 2019). Este coeficiente se ofrece como medida complementaria para la estimación de la confiabilidad del constructo y puede interpretarse como el porcentaje de la variabilidad de la variable latente explicada por los indicadores (Domínguez-Lara, 2016; Hancock & Mueller, 2001).
El coeficiente H presenta la ventaja de poder calcularse inclusive en modelos multidimensionales. Sin embargo, como sucede con el alfa y el omega, su valor aumenta con la adición de reactivos (Domínguez Lara, 2016). Además, presenta sesgos en la estimación de la confiabilidad en distintas condiciones muestrales (Aguirre-Urreta et al., 2019).
McNeish (2018), Sijtsma (2009) y Trizano-Hermosilla y Alvarado (2016) han indicado el cálculo del coeficiente greatest lower bound (GBL, Jackson & Agunwamba, 1977). El GLB se desprende de la noción de confiabilidad derivada de la TCT y estima la dimensionalidad mínima de la puntuación real bajo el supuesto de que la matriz de covarianza observada es la verdadera (Savalei et al., 2019). Dada la dificultad para realizar su cálculo, se han propuesto dos procedimientos: el cálculo mediante el análisis factorial de rangos mínimos (Trizano-Hermosilla & Alvarado, 2016) y el llamado GLB algebraico (Moltner & Revelle, 2015). Es preciso mencionar que, así como el alfa y el omega, este coeficiente posee limitaciones, porque se ha reportado que el coeficiente puede ofrecer valores sesgados cuando las muestras no son lo suficientemente grandes (Sijtsma, 2009).
Revelle y Zinbarg (2009) han sugerido cálculo del coeficiente beta (Revelle, 1979), que permite estimar la confiabilidad de la peor mitad de un instrumento mediante la realización de análisis de conglomerados jerárquicos. Es decir, que los ítems se agrupan de tal manera que es posible hallar la peor mitad del instrumento.
Otra alternativa propuesta ha sido el coeficiente theta (Armor, 1973), que se calcula a partir del análisis de componentes principales con el objetivo de estimar la varianza de las variables observables (Domínguez-Lara, 2012; Elosua & Zumbo, 2008).
Estimación de la confiabilidad ordinal a partir de matrices de correlaciones policóricas
Por lo general, el cálculo de coeficientes de confiablidad requiere matrices de correlaciones o covarianzas. En caso de que los ítems fueran continuos, puede trabajarse con matrices de correlaciones o covarianzas de Pearson. Cuando los datos son ordinales o dicotómicos, se debe trabajar con matrices de correlaciones policóricas (MCP) o tetracóricas, respectivamente (Elosua & Zumbo, 2008; Gadermann et al., 2012; Jöreskog, 1994; Viladrich et al., 2017).
Las MCP permiten estimar la relación lineal entre dos variables latentes continuas que subyacen a dos variables observables o reactivos ordinales (Flora & Curran, 2004). Miden la asociación bivariada entre dos variables con escala ordinal al explicar su naturaleza no lineal (Flora, 2020). La lógica detrás de la aplicación de MCP yace en que el escalamiento ordinal permite tratar como discretas variables latentes continuas (Zumbo & Kroc, 2019). Mientras que las estimaciones de la confiablidad se realizan tomando en cuenta las relaciones de cada ítem de una escala con su variable latente, independientemente del número de categorías (Elosua & Zumbo, 2008).
La utilización de MCP se basa en que el tratamiento de datos como si fueran continuos cuando no cumplen este supuesto, pueden llevar a infraestimaciones de la confiabilidad (Gadermann et al., 2012; Zumbo et al., 2007). Sin embargo, conforme la cantidad de opciones de respuesta para los ítems van aumentando, los datos pueden tratarse como continuos con resultados similares (Rhemtulla et al., 2012).
De manera que antes de realizar cálculos de confiabilidad deben considerarse la dimensionalidad del instrumento, el ajuste a modelos congenéricos o tau-equivalentes y las diferencias que pudieran surgir como resultado del número de opciones de respuestas.
Softwares gratuitos para el cálculo de coeficientes ordinales de confiabilidad
La utilización de matrices de correlaciones de Pearson ha sido el procedimiento predilecto para la estimación de la confiabilidad en casos de datos ordinales, posiblemente, por la facilidad de su cálculo mediante los softwares más difundidos (Gadermann et al., 2012). Sin embargo, en los últimos años, distintos softwares han ido incorporando la posibilidad de estimar MCP y coeficientes ordinales de confiabilidad.
Entre los softwares gratuitos, el Factor (Lorenzo-Seva & Ferrando, 2020) es un programa especializado en los análisis factoriales exploratorios que ofrece gran flexibilidad. Incluye distintos procedimientos para el suavizado de las matrices, la posibilidad de calcular matrices policóricas, tetracóricas y de Pearson, y diversos métodos de extracción y rotación. Asimismo, permite el cálculo de los coeficientes omega y GLB para estimar la confiabilidad. Es posible descargar la última versión del Factor por medio del siguiente enlace: https://psico.fcep.urv.cat/utilitats/factor/Download.html
A su vez, existen distintos módulos compatibles con Excel que posibilitan el cálculo de índices de confiabilidad. Si bien el Excel no es un programa gratuito, existen alternativas no aranceladas. En cuanto a los módulos, Domínguez-Lara (2012, 2018) ofrece módulos para obtener los coeficientes alfa y theta, que pueden ser solicitados de manera gratuita vía mail. Domínguez-Lara (2016) y McNeish (2018) han propuesto herramientas para el cálculo del coeficiente H. En el primer caso, la planilla puede ser solicitada vía mail al autor. En el segundo, la planilla además permite obtener el omega y puede ser descargada de https://sites.google.com/site/danielmmcneish/acdemic-work/reliability
Otro de los softwares que permite el cálculo de coeficientes ordinales de confiabilidad es el R (R Development Core Team, 2020). R es un lenguaje de programación cuya flexibilidad radica en la posibilidad de customizarlo de acuerdo con las necesidades mediante la descarga de paquetes que incluyen distintos contenidos. Estos paquetes pueden ser confeccionados por usuarios de todo el mundo, quienes lo comparten en la comunidad que utiliza R. Puede descargarse la última versión de R de http://www.r-project.org/
Entre los paquetes que posibilitan la obtención de coeficientes ordinales de confiabilidad, pueden citarse psych (Revelle, 2011), GPArotation (Bernaards & Jennrich, 2005), MBESS (Kelley & Lai, 2012), Rcmdr (Fox & Bouchet-Valat, 2019), lavaan (Rosseel, 2012) o semTools (Jorgensen et al., 2020)
La presente investigación
Existen distintos artículos que incluyen guías, recomendaciones y tutoriales para realizar cálculos de coeficientes de confiabilidad en R. Por ejemplo, Dunn et al. (2014), Flora (2020) y Gaderman et al. (2012), McNeish (2018), Savalei et al. (2019), Ventura-León (2018) y Viladrich et al. (2017). Sin embargo, no se han hallado guías que indiquen el paso a paso para R escritas en español. Asimismo, la utilización del R puede resultar compleja para investigadores no familiarizados con la programación. Una alternativa posible, para este último inconveniente, consiste en la utilización de Rstudio (Racine, 2011).
Rstudio es una interfaz diseñaba con la finalidad de simplificar el uso de los comandos de R, que incluye un menú de fácil empleo para los usuarios. Por lo tanto, la presente investigación presenta una guía en español para el cálculo de coeficientes ordinales de confiabilidad con R/Rstudio. Puntualmente, apunta a estudiantes e investigadores no familiarizados con R.
Se ofrece un ejemplo de la importancia de calcular coeficientes ordinales con datos reales. Al considerar el estudio de la dimensionalidad de los instrumentos, el ajuste a modelo congenérico o al tau equivalente y posibles diferencias mediante el cálculo de coeficientes mediante de correlaciones y covarianzas de Pearson, y MCP.
Procedimiento para calcular coeficientes ordinales de confiabilidad en R/Rstudio
Se debe descargar R de http://www.r-project.org/. En esa dirección, además de links de descarga, es posible hallar información y novedades sobre R. Para descargar R, es preciso clickear en CRAN mirror y seleccionar el link que corresponda según la cercanía geográfica. Se abrirá una ventana donde el usuario podrá descargar versiones de R para Windows, OS X o Linux, bajo el subtítulo Download and Install R. Luego de clicar en el enlace, según el sistema operativo que se esté usando, aparecerá una nueva pestaña. Por ejemplo, si se seleccionó Download R for Windows. La página siguiente tendrá como título R for Windows. Allí, se debe clickear install R for the first time, que redirigirá a un link que permite descargar la última versión de R. A continuación, se debe descargar, abrir el instalador e instalar el R.
Nótese que durante la instalación se permite seleccionar versiones de 32 o 64 bits de R.
Una vez instalado R, se puede descargar R/Rstudio mediante el siguiente enlace, que permite elegir versiones pagas o gratuitas: https://rstudio.com/products/rstudio/download/. En este tutorial, se seleccionará el link de descarga de la versión gratuita. Luego, corresponde descargar e instalar R/Rstudio.
Con R/Rstudio ya instalado, es posible importar bases de datos de otros softwares, así como descargar los paquetes necesarios para estimar la confiabilidad ordinal. Para descargar los paquetes, se debe seleccionar Tools en el menú de R/Rstudio, y la opción install packages. Allí, se deben escribir, respetando espacios, mayúsculas y minúsculas, los nombres de los paquetes por descargar, separados por comas o espacios. En este caso, se ingresa: psych GPArotation Rcmdr lavaan semTools y clickear en install.
Una vez que los paquetes hayan sido instalados, R/Rstudio informará su correcta instalación, así como la carpeta de ubicación.
Ya instalados los paquetes, es posible utilizarlos. Para ello, se debe hacer que los paquetes sean partes del entorno del software, cada vez que se inicie R/Rstudio. Se debe ingresar el comando library en la consola de R/Rstudio, seguido del nombre del paquete a usar entre paréntesis. Por ejemplo, library(psych) permite el uso del paquete psych mediante su integración al entorno. Es preciso mencionar que R/Rstudio presenta una función de autocompletar, luego de cada comando ejecutado en la consola. Facilita, por ejemplo, la inclusión de paquetes en el entorno.
R/Rstudio permite importar bases de datos de EXCEL, SPSS, SAS y Stata, así como documentos de texto. Para ello, se debe clickear File en el menú de R/Rstudio, a continuación, Import Dataset, elegir el programa que corresponda y seleccionar la base de datos por trabajar. R/Rstudio ofrece la posibilidad de visualizar la base de datos arriba de la consola, una vez importada.
Cuando se cuente con la base de datos dentro del entorno, es posible seleccionar ítems para armar un conjunto de datos. Para ello, se debe escribir el nombre del nuevo conjunto de datos seguido de <-data.frame y los ítems que lo conformarán.. Por ejemplo, itemsERQ<-data.frame(ERQ,ERQ2,ERQ3,ERQ4,ERQ5,ERQ6,ERQ7,ERQ8,ERQ9). En caso de trabajar con varios conjuntos de datos, se puede seleccionar uno mediante el comando attach y el nombre de conjunto entre paréntesis. Por ejemplo, attach(itemsERQ).
Para examinar la dimensionalidad de un instrumento, se puede recurrir a las funciones de los paquetes lavaan y semTools, que permiten gran flexibilidad para el trabajo con ecuaciones estructurales. O bien, puede recurrirse a la relación de análisis factoriales exploratorios (AFE) con los paquetes psych y GPArotation. En el último caso, la función fa distintos algoritmos que permiten la realización de AFE y se encuentran desarrolladas en Revelle (2021). En el presente ejemplo, se utilizarán los paquetes lavaan y semTools para recurrir al análisis factorial confirmatorio (AFC). Si bien las funciones del paquete lavaan pueden encontrarse descriptas en Rosseel (2020) y exceden a los propósitos de la presente investigación. Con este paquete, pueden especificarse modelos unidimensionales y multidimensionales y examinar su ajuste. Por ejemplo:
modelo.ERQ <- ’supresión =~ ERQ2 + ERQ5 + ERQ8
reevaluación =~ ERQ1 + ERQ3 + ERQ6 + ERQ9
Luego, con la función cfa se puede evaluar el ajuste, se selecciona el modelo por examinar y el conjunto de datos correspondiente. Indica la naturaleza ordinal de los ítems mediante la función ordered.
Por ejemplo: ajuste <- cfa(modeloERQ, data=itemsERQ, ordered = c(‘ERQ1’,’ERQ2’, ‘ERQ3’,’ERQ4’, ‘ERQ5’,’ERQ6’,’ERQ7’, ‘ERQ8’,’ERQ9’)). De esta manera, lavaan realiza las estimaciones, por defecto, mediante MCP y el método de estimación de mínimos cuadrados ponderados diagonales (DWLS).
A continuación, la función summary permite visualizar un resumen del ajuste del modelo que incluye índices de bondad de ajuste, cargas estandarizadas y valores de error. La forma en que se computa este resumen es escribiendo summary en la consola, con el nombre del ajuste solicitado por el usuario y las medidas de ajuste entre paréntesis. Por ejemplo: summary (ajuste, fit.measures=TRUE).
A continuación, se debe evaluar el ajuste de los datos a los modelos congenérico y tau equivalente para seleccionar el coeficiente de confiabilidad a utilizar. Para ello, puede examinarse la similitud entre las cargas estandarizadas de los ítems (McNeish, 2018). Al seguir el ejemplo de McNeish (2018), un modelo tau equivalente podría exhibir cargas estandarizadas con valores como .711; .714; .716; .709; y .721. Si las cargas estandarizadas varían, se trata de un modelo congenérico.
El paso siguiente consiste en calcular y guardar las MCP. Para ello, se utilizará el comando poly choric. Para calcular una MCP se debe escribir en la consola polychoric seguido del nombre del conjunto de datos con el que se está trabajando, entre paréntesis. Por ejemplo: polychoric (itemsERQ). Para guardar la MCP, se debe ingresar el nombre que se desea que tenga, como podría ser MCPitemsERQ, junto con el comando polychoric. Por ejemplo: MCPitemsERQ <-polychoric(itemsERQ). De manera que ya pueden calcularse los coeficientes ordinales de la MCP guardada.
Se pueden seleccionar distintos coeficientes de confiabilidad que pueden ser calculados mediante psych y GPArotation, que se resumen en la tabla 1. Nótese que, luego de insertar el nombre de la MCP, se debe ingresar el comando $rho. Este comando implica que únicamente la matriz se utiliza para los cálculos, independientemente de otra información guardada junto con la matriz (Gadermann et al., 2012).
Es preciso mencionar que el paquete psych incluye funciones que exceden al objetivo de la presente investigación y pueden ser consultadas en Revelle (2020).
Tabla 1 Funciones y coeficientes calculables mediante los paquetes psych y GPArotation
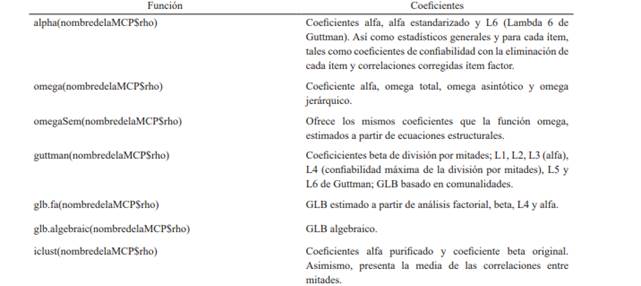
Nota. El texto entre paréntesis hace referencia al nombre en que el usuario guardó la matriz de correlaciones policóricas.
Como puede observarse, los paquetes psych y GPArotation ofrecen la posibilidad de calcular distintos coeficientes ordinales a partir de MCP. A continuación, se ofrece un ejemplo de la importancia del cálculo de coeficientes ordinales mediante comparaciones de estimaciones partir de matrices de correlaciones y covarianzas de Pearson, y MCP.
Diseño
Se realizó un estudio observacional de tipo transversal, porque se realizó una medición única (Manterola et al., 2019).
Participantes
Se recogió una muestra de 266 participantes de 18 a 63 años (M = 31.91; DE = 11.50). En cuanto al género, el 60.5% de los participantes reportó mujer; el 37.5% varón; el 1.5% otro y el 0.5% prefirió no decirlo. El 44% de los participantes informó trabajar en relación de dependencia; el 29%, como monotributista; el 20% se dedica al estudio; el 5% se encuentra desocupado y el 2%, jubilado. En relación con el nivel de instrucción alcanzado, el 40% expresó poseer universitario incompleto o en curso; el 24.5 %, universitario completo; el 9%, terciario incompleto o en curso; el 9%, secundario completo; el 8%, posgrado; el 8%, terciario completo; el 1%, secundario incompleto y el 0.5%, primario incompleto.
Instrumentos
Inventario de Ansiedad de Beck (BAI; Beck et al, 1988; adaptación argentina: Vizioli & Pagano, 2020). Es un instrumento autoadministrable de 21 ítems, que miden síntomas característicos de la ansiedad. La puntuación de los reactivos se realiza sobre una escala Likert de 4 opciones (0 a 3). El Inventario presenta adecuadas propiedades psicométricas para la población argentina, con evidencias de validez de constructo a través de AFC, y una confiabilidad de alfa ordinal = .93, y omega ordinal = .95.
Cuestionario de Regulación Emocional (ERQ; Gross & John, 2003; adaptación argentina: Pagano & Vizioli, en prensa). Cuestionario autoadministrable que consta de 9 ítems, 6 de los cuales evalúan la reevaluación cognitiva y 3 la supresión expresiva, a los que se responden mediante una escala Likert de 7 puntos, que va de 1 = totalmente en desacuerdo a 7 = totalmente de acuerdo. El cuestionario presenta adecuadas propiedades psicométricas para la población argentina con evidencias de validez de constructo a través de AFC, que indican una estructura que mide dos factores independientes. Presenta adecuadas evidencias de confiabilidad mediante alfa ordinal = .81 y omega ordinal = .87 para la reevaluación cognitiva y de alfa ordinal = .72 y omega ordinal = .79 para la supresión expresiva.
Procedimiento
Se realizó la recolección de datos mediante plataformas virtuales. En la administración se incluyeron un consentimiento informado y los instrumentos. El consentimiento informado explicaba la naturaleza voluntaria, anónima y sin compensación de la participación. A su vez, explicitó que los participantes podían abandonar la investigación en el momento que quisieran.
Análisis de datos
Para analizar la dimensionalidad de los instrumentos, se procedió a la realización de un AFC mediante el software R/Rstudio y el paquete lavaan, mediante el método DWLS a partir de MCP. Se utilizaron los índices de bondad de ajuste robustos: χ2 de Satorra-Bentler (S-B χ2) dividido por los grados de libertad (valores ≤ 5,0 indican un buen ajuste); NNFI (Non-Normed Fit Index); CFI (Comparative Fit Index), RMSEA (Root Mean Square Error of Approximation). De acuerdo con los criterios especificados por Kline (2011) y Schumacker & Lomax (2016) se consideró un ajuste aceptable a valores mayores o iguales a .90 en NNFI y CFI. En RMSEA, valores menores a .05 indican un buen ajuste y los valores comprendidos entre .05 y .08 un ajuste razonable (Browne & Cudeck, 1993). Se examinaron las cargas estandarizadas obtenidas con la finalidad de determinar la adecuación de los modelos congenéricos y tau equivalente.
A continuación, mediante los paquetes psych y GPArotation, en R/Rstudio, se calcularon matrices de covarianzas y correlaciones de Pearson, y MCP. A partir de ellas, se computaron los coeficientes de confiabildiad más difundidos y recomendados en la literatura: alfa, omega total, omega jerárquico y GLB (algebraico y factorial) para cada dimensión. Aunque el omega jerárquico es adecuado cuando el modelo subyacente es bifactorial o con un factor de segundo orden (Flora, 2020), se calculó como ejemplo. Se consideraron adecuados valores mayores a .80 en el alfa y el omega total y mayores a .65 en el omega jerárquico (Catalán, 2019).
Resultados
En primer lugar, se examinó la dimensionalidad de los instrumentos al probar el modelo unidimensional del BAI (Vizioli & Pagano, 2020) y el de dos factores independientes del ERQ (Pagano & Vizioli, en prensa; Gross & John, 2003). Como puede observarse, los índices de bondad de ajuste resultaron adecuados en ambos casos (tabla 2).
Tabla 2 Índices de bondad de ajuste de los modelos del BAI y del ERQ

Nota: NNFI = Non-Normed Fit Index; CFI = Comparative Fit Index; RMSEA = Root Mean Square Error of Approximation; IC = intervalo de confianza; GL = grados de libertad.
En segundo lugar, se examinaron las cargas estandarizadas al fin de evaluar el ajuste a los modelos congenérico y tau-equivalente. Las cargas factoriales estandarizadas correspondientes a ambos instrumentos evidencian la adecuación del modelo congenérico (tabla 3).
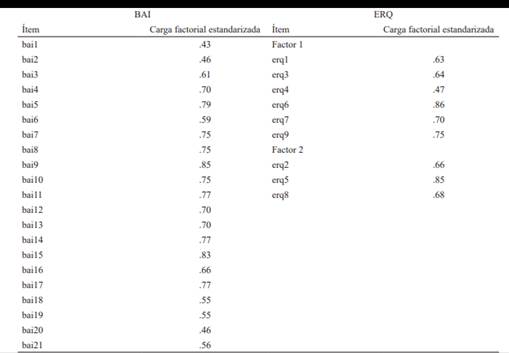
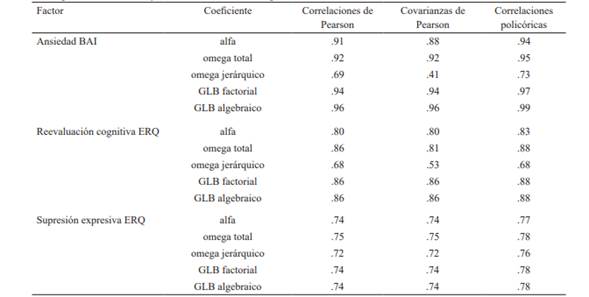
Como era de esperarse, dado que el modelo congenérico evidenció ajustarse a los datos, los valores de omega total son superiores a los de alfa. A su vez, los valores obtenidos a partir de MCP resultan adecuados en todos los casos y superiores a los obtenidos a partir de matrices de correlaciones y covarianzas de Pearson (tabla 4)
Discusión
La presente investigación tuvo como objetivo proporcionar una guía para el cálculo de coeficientes ordinales de confiabilidad. Para esta finalidad, 1) se definió a la confiabilidad, se expusieron distintos coeficientes para estimarla con sus ventajas y desventajas, 2) se explicó la adecuación de su cálculo mediante MCP, 3) se mencionaron softwares gratuitos para el cálculo de coeficientes ordinales de confiabilidad, 4) se proporcionó una guía para el cálculo de coeficientes ordinales con R/Rstudio y 5) se ofreció un ejemplo que compara distintos coeficientes de confiabilidad calculados a partir de MCP, matrices de correlaciones de Pearson y matrices de covarianzas de Pearson.
En este sentido, se ha presentado al alfa como un coeficiente adecuado en situaciones donde se cumplen los supuestos de unidimensionalidad, ausencia de errores correlacionados y tau equivalencia (McNeish, 2018; Raykov, 1998; Raykov & Marcoulides, 2019; Savalei et al., 2019). A su vez, en caso de incumplirse la tau-equivalencia, el coeficiente alfa puede aproximarse a mayor límite inferior de confiabilidad (Cronbach, 1951; Trizano-Hermosilla & Alvarado, 2016; Sijtsma, 2009). Mientras que el omega total se recomienda en situaciones de unidimensionalidad, ausencia de errores correlacionados y adecuación del modelo congenérico (Domínguez-Lara, 2016; Savalei et al., 2019). El omega jerárquico resulta indicado cuando el modelo subyacente a los datos es bifactorial o con un factor de segundo orden (Flora, 2020; Revelle & Zinbarg; 2009; Trizano-Hermosilla & Alvarado, 2016). El coeficiente H presenta la ventaja de poder calcularse inclusive en modelos multidimensionales. Sin embargo, como sucede con el alfa y el omega, su valor aumenta con la adición de reactivos (Domínguez-Lara, 2016). Asimismo, dentro de la literatura, se ha sugerido el cálculo del coeficiente GLB (McNeish, 2018; Sijtsma, 2009; Trizano-Hermosilla & Alvarado, 2016) beta (Revelle & Zinbarg, 2009) y theta (Domínguez-Lara, 2012; Elosua & Zumbo, 2008). Estos coeficientes persiguen distintos objetivos y procedimientos que el alfa y los omega y permiten obtener evidencias complementarias y relevantes de confiabilidad. En caso del coeficiente H, se lo recomienda como recurso complementario siempre que el modelo congenérico exhiba un ajuste adecuado (Domínguez-Lara, 2016).
En cuanto al cálculo de coeficientes ordinales, se informó acerca de la adecuación de su cálculo mediante MCP. En este sentido, mediante el ejemplo proporcionad,o se ha hallado que los valores obtenidos a partir del cálculo de coeficientes de matrices de correlaciones de Pearson y de covarianzas de Pearson, fueron menores a los obtenidos mediante MCP. Estos resultados pueden explicarse dado que, al contar con datos ordinales, las matrices de correlaciones de Pearson y de covarianzas de Pearson tienden a incurrir en infraestimaciones (Gadermann et al., 2012). Se resalta la adecuación de las MCP para trabajar con datos ordinales (Elosua & Zumbo, 2008; Gadermann et al., 2012; Jöreskog, 1994; Viladrich et al., 2017).
Al comparar los coeficientes ordinales calculados entre sí, puede observarse que el alfa ordinal fue menor al omega total en todos los casos. Podría explicarse por la adecuación de los datos al modelo congenérico. De manera que resulta esperable que el omega sea ligeramente más elevado que el alfa (Deng & Chang, 2017; Revelle & Zinbarg, 2009). En cuanto al omega jerárquico, su valor fue el menor de los obtenidos. Se puede explicar dado que se recomienda en modelos bifactoriales o con factores de segundo orden (Flora, 2020; Revelle & Zinbarg; 2009; Trizano-Hermosilla & Alvarado, 2016). Sin embargo, en casos de modelos que tienen una estructura establecida con varias dimensiones que no están fuertemente correlacionadas, se recomienda el cálculo del alfa o el omega total para cada una de sus dimensiones (Savalei et al., 2019). En cuanto a los GLB factorial y jerárquico, los valores obtenidos fueron similares entre sí y mayores a los de otros coeficientes. Sin embargo, es posible que los valores resulten sesgados en función del tamaño muestral (Sijtsma, 2009).
En cuanto a las limitaciones de la presente investigación, en primer lugar, debe mencionarse que el software R se encuentra en constante actualización y crecimiento. De manera tal que es posible que la guía propuesta deba sufrir modificaciones con el paso del tiempo.
En segundo lugar, la esta investigación se centra en el procedimiento para realizar el cálculo de coeficientes ordinales con R/Rstudio. De tal manera, futuras investigaciones pueden ofrecer guías basadas en otros softwares.
En tercer lugar, el tamaño muestral reducido impidió realizar comparaciones de los valores obtenidos con distinta cantidad de participantes. De esta manera, se sugiere que futuras investigaciones comparen el rendimiento de los coeficientes según tamaños muestrales.
En conclusión, la presente investigación ofrece una guía conceptual actualizada acerca de la confiabilidad y los distintos coeficientes ordinales para su estimación. Asimismo, se proporciona una guía práctica para la obtención de coeficientes de confiabilidad mediante el R/Rstudio junto con un ejemplo.
Este trabajo favorece el cálculo de coeficientes ordinales de confiabilidad mediante una herramienta gratuita de sencilla utilización, tal como es el R/Rstudio. Se espera que este manuscrito sirva a estudiantes, docentes e investigadores con la finalidad de resolver situaciones prácticas en las cuales se trabaja con la calidad psicométrica de un instrumento. Si bien, no debe descuidarse el valor teórico en la interpretación de los resultados. Puntualmente, el recurso propuesto pretende servir de guía para el inicio de investigadores o estudiantes no familiarizados con R.

