











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
Desde el Laboratorio de Procesamiento de Imágenes Digitales (LAPID), adscrito a la Escuela de Informática de la Universidad Nacional (UNA), se ha experimentado con el desarrollo de modelos, métodos y algoritmos para el procesamiento de imágenes digitales, haciendo uso del procesamiento y modelos matemáticos, inspirados en el sistema de visión humana por computadora; una rama de la inteligencia artificial (IA). Se destacan dos ejes para esta investigación del LAPID. El primero ofrece almacenamiento, manipulación y análisis de imágenes, y el segundo brinda espacios para estudiantes de pregrado, grado o posgrado en pasantías o proyectos finales de graduación, para desarrollar competencias y experiencias en desarrollos de modelos en el área de la IA.
Dando continuidad a las funciones académicas y de investigación que desarrolla el LAPID, cabe destacar que, desde el 2016, ha dedicado recursos para que el equipo académico pueda crear modelos, métodos y probar algoritmos de IA. En ese contexto, se utilizó el método de clasificación de mamografías (benignas y malignas), por lo que estos y otros son puestos a la disposición del estudiantado de la Escuela de Informática y Computación, a fin de fortalecer las competencias enumeradas en Tabla 1.
Para las actividades con el estudiantado, se elaboró un marco de competencias y resultados de aprendizaje que permiten planificar actividades y evidenciar resultados en las experiencias que se realizan (de una a dos veces al año). En la Tabla 1, se detalla el conjunto de competencias que incluye capacidades, habilidades y valores. Estos, de forma conjunta, guían la construcción y el desarrollo durante el período de práctica o las pasantías. Durante esta investigación, el estudiantado fortaleció siete competencias técnicas y transversales y 14 resultados de aprendizaje.
Tabla 1 Marco de competencias y resultados de aprendizaje del LAPID
| Competencia | Resultado de aprendizaje |
|---|---|
| C1. Capacidad para manipular imágenes. | RA 1.1. Aplica acciones o cambios para manipular las imágenes según los atributos: corrección de color, tamaño, tipo, resolución, formato, etc. |
| C2. Capacidad para comprender los fundamentos de la inteligencia artificial y el aprendizaje automático (Machine Leaning). | RA 2.1. Identifica los conceptos de la IA y el endizaje automático (Machine Learning). |
| RA 2.2. Comprende cómo funcionan las redes según los tipos de arquitecturas (convolucionales o recurrentes). | |
| RA 2.3. Describe y depura código para implementar algoritmos de aprendizaje automático o Machine Learning en Python versión 3. | |
| RA 2.4. Identifica y utiliza bibliotecas y frameworks específicos para aprendizaje automático o Machine Learning. | |
| C3. Capacidad para programación y desarrollo de modelos. | RA 3.1. Aplica la programación y la implantación de modelos de redes neuronales. |
| RA 3.2. Puede construir, entrenar y evaluar modelos de redes neuronales. | |
| RA 3.3. Aplica análisis matemático en la programación y desarrollo de los modelos. | |
| C4. Capacidad de solucionar problemas (transversal). | RA 4.1. Provee soluciones prácticas utilizando programación y redes neuronales para facilitar el análisis de imágenes médicas. |
| RA 4.2. Selecciona algoritmos y modelos según la necesidad que enfrenta. | |
| C5. Capacidad de análisis de resultados. | RA 5.1 Interpreta función de pérdida, matriz de confusión y análisis de efectividad. |
| C6. Capacidad ética (transversal). | RA 6.1. Cumple con todos los protocolos éticos y de privacidad de trabajar con datos médicos e imágenes sensibles. |
| C7. Capacidad para investigar (transversal). | RA 7.1. Se actualiza de forma constante con las últimas investigaciones de la IA. |
| RA 7.2. Investiga sobre los avances de la IA aplicada a la medicina y el manejo de imágenes médicas. |
Nota: marco de competencias y resultados de aprendizaje(LAPID, 2023)
El conjunto de competencias (técnico y transversales), basado en una propuesta anterior de un ejercicio realizado por perso nas académicas de la escuela (Garita-Gonzalez et al., 2021), en el cual el primer tipo de competencias deriva del desarrollo de modelos en programación, pero se extien de a las competencias en IA y aprendizaje automático. El segundo tipo se desarrolló desde la ética de la persona académica y el estudiantado, que enmarca los protocolos y la privacidad de trabajar con datos mé dicos. Estas competencias se contrastaron con Ethically Aligned Design, del Instituto de Ingenieros Eléctricos y Electrónicos (IEEE), creado en el 2019, para el diseño, desarrollo y uso de la IA.
El marco de competencias del LA PID se delimita, en esta investigación, al aprendizaje automático y al uso de las redes neuronales de convolución (CNN), para la clasificación de mamografías benignas o malignas desde un contexto de ejercicio académico, liderado por docentes de la es cuela y ejecutado por el estudiantado que se encuentra cursando su práctica profesional en el LAPID. Se desea reflexionar sobre ¿cómo pueden mejorarse las habilidades del estudiantado mediante la introducción de la IA, aprendizaje automático y redes neuronales?
Dicho lo anterior, resulta importante considerar los modelos existentes que motivan el uso de IA en la educación superior. Netragaonbar (2024) discute cómo la IA puede hacer que los servicios educativos sean más accesibles y rápidos tanto dentro como fuera del aula. Esto coincide con lo indicado por Hutson et al. (2022), quienes, al analizar el primer informe AI100 de Stanford, aseveran el impacto global en las personas y las industrias, incluida la educación superior. Las instituciones educativas están acelerando la adopción de IA en diversas disciplinas para enfrentar los cambios del mercado. En EE. UU. se proyectó un crecimiento del 48 % en el mercado de la IA en universidades entre 2018 y 2022. Además, el mismo estudio confirma que el uso actual de la IA en educación mejora los resultados de aprendizaje, aumenta la retención de información, reduce costos y el tiempo de finalización de estudios.
Si se reflexiona sobre esto, es válido confirmar que la Universidad Nacional está dando los primeros pasos en crear grupos académicos para desarrollar lineamientos o estructuras que permitan guiar el uso de la IA en sus procesos. Lo anterior concueda con Tsou (2024), quien recomienda iniciar el camino para desarrollar políticas integrales de IA. Por ejemplo, en Estados Unidos, el personal académico se ve amenazado por la IA y forma alianzas como mecanismo de supervivencia, mientras que otros sienten incertidumbre y ansiedad sobre su papel en la enseñanza. En Europa, las actitudes hacia las aplicaciones de IA son diversas y están influenciadas por la necesidad de directrices y una mejor comprensión de sus implicaciones en la academia. En China, la educación está siendo impactada de dos maneras principalmente: los Gobiernos guían de forma activa a las instituciones educativas hacia la investigación y formación en IA, y el sector corporativo desarrolla aplicaciones de IA que podrían estandarizar e intensificar el competitivo sistema educativo, impulsado por el interés empresarial privado. A todo esto, se puede pensar que la IA está transformando la educación superior en todo el mundo, emergiendo como uno de los agentes de cambio en el ámbito académico (Tsou, 2024).
Paralelo a los diferentes usos de la IA en la educación superior, cabe recapacitar en la oposición de adoptar esta tecnología, debido a conceptos erróneos y la percepción de que los docentes deberán actualizar sus métodos de enseñanza. En escenarios más impactantes Hutson et al. (2022) generan predicciones sobre la pérdida de empleo a causa de la IA, para el 2030. El mismo informe también señala que se crearán entre 555 y 890 millones de nuevos empleos debido a la IA. Este tema pueda, entonces, inferir en promover el uso del IA.
En adelante, se analizarán conceptos relacionados a la IA (aprendizaje automático y redes neuronales), aplicados a los procesos de enseñanza y aprendizaje, con el objeto de utilizar modelos innovadores centrados en el estudiantado. En el contexto de esta investigación, se suma la verdadera importancia en cómo la aplicación de tecnologías avanzadas de IA, específicamente a través de algoritmos de aprendizaje profundo, ha mostrado resultados prometedores para mejorar la interpretación de mamografías. Esto lo confirma Yoon et al. (2021).
Ahora bien, en cuanto a la estructura de este artículo, se dividió en un apartado introductorio sobre antecedentes del proyecto, el marco teórico que expone los principales conceptos, la metodología utilizada durante la investigación, el apartado de análisis y resultados detalla los principales hallazgos, y, finalmente, las conclusiones y referencias.
Marco teórico
La IA fue creada en una conferencia en el Dartmouth College, en 1956, y se ha convertido en una ciencia empírica, con el desarrollo y la tecnología de las aplicaciones informáticas. Este concepto se ha expandido, gradualmente, y se caracteriza por simular el pensamiento y la cognición humana en máquinas; es decir, utilizarlas para simular la inteligencia humana (Tian, 2020). Además, Harika et al. (2022) la definen como la programación y arquitectura de computadoras diseñadas para entrenar máquinas y realizar tareas. Se contrasta con lo definido por Mian y Sushma (2023) cuando hacen referencia a las cosas que el humano ha creado o fabricado, contrario a lo que ocurre de manera inherente. Se puede resumir, entonces, a esa capacidad de crear métodos y modelos para lograr objetivos mediante la interacción con un entorno de aprendizaje tecnológico y de transformación.
Aprendizaje automático y redes neuronales
Sobre el aprendizaje automático o Machine Learning (ML), los autores Rashed y Popescu (2021) destacan que estas técnicas aumentan la capacidad de los sistemas para aprender automáticamente a partir de la experiencia, sin necesidad de una programación explícita. Se utilizan diferentes métodos de ML para una variedad de tareas, como el procesamiento de imágenes, el análisis predictivo, la minería de datos, la clasificación, la regresión, la agrupación (clustering) y muchos otros. De acuerdo con Mian y Sushma (2023), el ML se ha convertido en una necesidad industrial importante, siendo utilizado en la banca, la medicina y la defensa.
En este orden de idea, se reconoce que el ML no aprende de la misma manera que un ser humano y no es independiente en su aprendizaje. En realidad, el ML depende por completo de las personas: ellas seleccionan, limpian y etiquetan los datos, diseñan y entrenan los algoritmos de IA. Como dato interesante, los algoritmos de aprendizaje automático que utilizan redes neuronales existen desde hace más de 40 años y, debido a su potencial disruptivo, ha aumento gracias al refinamiento de estos algoritmos (UNESCO, 2021).
Sobre el concepto de las redes neuronales (RN), se indica que están inspiradas en las redes neuronales biológicas de los cerebros de los animales y aprenden tareas teniendo en cuenta el ejemplo, sin necesidad de una programación específica para una tarea en particular. (Shin y Yoo, 2020). Esto contrasta con lo dicho por Pamukov et al. (2020), quienes confirman que las RN están inspiradas en el cerebro de los mamíferos y se utilizan en tareas de ingeniería, incluidas la clasificación, la predicción y la regresión. Entre las arquitecturas, se eligió, para esta investigación, la Red Neuronal de Convolución o Convolutional Neural Networks (CNN), se utilizan en la clasificación y la detección de objetos en imágenes. Según Cooke et al. (2023), los modelos de redes neuronales son herramientas prácticas para la resolución de problemas complejos (Mahadevkar et al., 2022), como el procesamiento de imágenes y aplicable al contexto del LAPID y el desarrollo de competencias en el estudiantado.
Un concepto que complementa a la RN es el poder del aprendizaje profundo o Deep Learning, el cual tiene la capacidad para aprender de datos no estructurados. Logra una automatización y extrae características para efectuar predicciones. Sin embargo, comprender las decisiones de las redes neuronales sigue siendo un desafío debido a su complejidad.
El modelo desarrollado en esta investigación incluye varios componentes que abarcan bibliotecas de software, funciones y módulos. En la Tabla 4 se enlistan los componentes utilizados para el desarrollo del modelo de clasificación antes mencionado (UNESCO, 2021).
La IA puede verse como una inteligencia similar a la humana, implicando la imitación de funciones propias de las personas; se destaca la resolución de problemas. Ahora bien, el ML es un subcampo de la IA caracterizado por analizar cantidades de datos para identificar patrones y facilitar la construcción de modelos predictivos. Las RN, inspiradas en procesos neuronales del cerebro humano, pueden aprender y ejecutar variadas tareas complejas, como la clasificación de imágenes y patrones, lo cual es relevante para este estudio. En síntesis, el aprendizaje automático es un componente de la IA y las redes neuronales constituyen una subdisciplina dentro de la IA. El Aprendizaje Profundo o Deep Learning son la columna vertebral de las redes neuronales (UNESCO, 2021).
Procesamiento de imágenes en usos médicos
En los últimos 20 años, se han realizado esfuerzos para utilizar tecnologías en la detección de malignidades mamarias. Sin embargo, los enfoques tradicionales no han logrado mejoras significativas en los resultados. Recientes avances en IA y aprendizaje automático están comenzando a tener un mejor efecto en el rendimiento. Hoy en día, coexisten más de 20 aplicaciones de IA aprobadas por la Administración de Alimentos y Medicamentos (FDA) para imágenes mamarias, aunque su adopción y uso aún son variables y, en general, bajos. La mamografía sigue siendo fundamental en los programas de detección de cáncer de mama en el mundo. Además de la detección de cáncer, la IA tiene otras aplicaciones potenciales en imágenes mamarias, como soporte en la toma de decisiones, evaluación de riesgo, cuantificación de la densidad mamaria, optimización de flujos de trabajo, evaluación de calidad, respuesta a la quimioterapia y mejora de imágenes. Aunque la IA ofrece oportunidades, también enfrenta desafíos en su implementación generalizada (Taylor, 2023).
Desde la perspectiva médica, las imágenes son esenciales en el diagnóstico y tratamiento médico, pues revelan la anatomía interna de cada persona. Las bases de datos de imágenes médicas son demasiado grandes para que los humanos las analicen eficazmente, por lo que algoritmos y software de IA permiten extraer, de forma automática o semiautomática, información crítica de estos conjuntos de datos. El procesamiento de imágenes con AI utiliza algoritmos para modificar, analizar y extraer imágenes, mejorando su calidad. Se aplican métodos como mejora de imágenes, restauración, segmentación, extracción de características y reconocimiento de objetos para diversos usos particulares.
Los autores Magomedov et al. (2024) indicaron que muchas áreas de la medicina involucradas con el análisis de imágenes se emplean para el procesamiento de rayos X, resonancias magnéticas y tomografías computarizadas. Estas tecnologías se pueden utilizar para diagnosticar y controlar enfermedades, mejorar la detección y diagnóstico del cáncer de mama y predecir el riesgo de desarrollarlo. La IA permite profundizar en el diagnóstico, acrecentando drásticamente la exactitud de los resultados. Con la mejora del diagnóstico, se puede aumentar la exactitud de los resultados de forma contundente.
En términos del uso del procesamiento de imágenes, también es un método eficaz para involucrar al estudiantado en el aprendizaje por investigación y descubrimiento. Quienes apliquen estas tecnologías aprenden sobre los muchos conceptos matemáticos subyacentes al procesamiento de imágenes, como sistemas de coordenadas, pendiente e intersección, píxeles, aritmética binaria y muchos otros. No obstante, se enfatiza la necesidad de investigaciones más profundas para validar, de manera concluyente, la efectividad de estos algoritmos en la práctica clínica real. Este objeto de estudio puede desencadenar intereses futuros en el uso aplicado de la AI en la educación superior y, eventualmente, a usos médicos conjuntos.
Ahora bien, las imágenes de mamografías constituyen una técnica de diagnóstico por imagen que usa rayos X a fin de recrear imágenes detalladas de la mama y el tejido mamario (Sardinas, 2009). Además, la mamografía sigue representando el examen de elección para detectar cáncer en la población general (Delgado et al., 2021). Estas imágenes fueron el principal activo del estudio.
Para el alcance del objetivo de clasificar mamografías benignas o malignas, se desarrolló un modelo de CCN básico, que debía aprender a interpretar y reconocer algunas características, como la forma, los bordes, la densidad y otros detalles de las mamografías, (ejemplo de esto se presenta en la Figura 1).
Dentro del contexto académico de este ejercicio, se definieron los siguientes seis tipos de diagnósticos de mamografías: 1) calcificaciones: son depósitos de sales de calcio; 2) masas circunscritas: se refieren a áreas en donde hay tejido mamario que forma una masa bien definida y limitada en comparación con el tejido de alrededor, también llamados quistes con líquido o tumores ya sólidos; 3) masas espiculadas: como lo indica el nombre, son masas que tienen proyecciones o espiculaciones que se extienden desde sus bordes; 4) masas mal definidas: se caracterizan por tener bordes difusos o poco definidos en lugar de bordes nítidos; 5) distorsiones arquitecturales: son alteraciones en la disposición normal de los tejidos mamarios; 6) densidades asimétrica: se producen cuando hay diferencias significativas en la densidad de tejido entre una mama y la otra (Blanco et al., 2017).
Metodología
El tipo de investigación es aplicada y exploratoria. La primera permite usar redes neuronales convolucionales (CNN) para la clasificación de mamografías benignas y malignas en contextos médicos. La segunda engloba a la persona investigadora que utiliza formas novedosas de emplear modelos de aprendizaje automático. El enfoque mixto se centra en comprender la IA en el procesamiento de imágenes médicas.
Objetivo
Desarrollar competencias en IA y ML en estudiantes que deseen experimentar en la creación de modelos de aprendizaje automático y redes neuronales de convolución para clasificar mamografías.
Población
Este estudio inició y finalizó en el I ciclo del 2023, con la participación de personas académicas y estudiantes que cursan el último curso de la carrera; es decir, la Práctica Profesional Supervisada. Se utilizó el set de mamografías disponibles de la base de datos The Mamograpic Image Society (Suckling et al., 2015), donde hay disponibles 322 imágenes en el formato PGM (Portable Gray Map). Ahora bien, se utilizaron 118 imágenes de mamografías porque tienen diagnósticos médicos como se aprecia en Tabla 2.
Tabla 2 Lista de diagnósticos de las mamografías utilizadas
| Diagnóstico | Cantidad de mamografías |
| Calcificaciones | 25 |
| Masas circunscritas | 20 |
| Masas espiculadas | 21 |
| Masas mal definidas | 15 |
| Distorsiones arquitecturales | 20 |
| Densidades asimétricas | 17 |
| Total | 118 |
Nota: Suckling et al. (2015).
En la Figura 1 se presenta un ejemplo de las imágenes de mamografías utilizadas.

Durante esta investigación, se planificaron tres etapas empleadas para el desarrollo del modelo (Figura 2). Todo inició al identificar un problema médico: la clasificación de mamografías benignas y malignas. Se utilizó Python, como lenguaje de programación, con el cual se seleccionaron componentes, tales como módulos, bibliotecas y funciones; cada uno se clasificó en aprendizaje automático o procesamiento de imágenes y redes neuronales de convolución (Tabla 4).
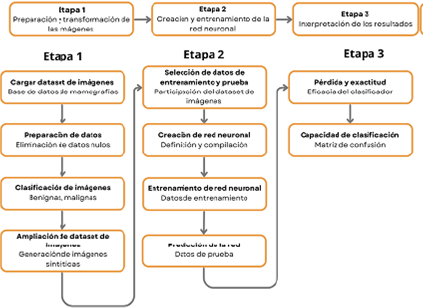
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
Figura 2 Metodología con la secuencia de pasos que permite clasificar mamografías en maligna o benigna
También, se abordó desde tres etapas: la primera realizó la preparación para trans-formar las imágenes y, para esto, se utilizó una base de datos para el almacenamiento de imágenes médicas y mamografías digita-les con fines educativos. Seguido de cargar el conjunto de imágenes médicas de mamografías digitales en la base de datos UNAPAC del LAPID. En la segunda etapa se creó un modelo de clasificación automático mediante redes neuronales de convolución, cargando, entrenando y validando el modelo, hasta clasificar una mamografía como benigna o maligna. En la tercera y última etapa, se efectuó una interpretación de los resultados obtenidos. Además, se desarrolló una construcción de una aplicación informática desde la página web del LADIP, en la cual se puede llevar a cabo las pruebas de funcionalidad y la corrección de posibles errores. En la Figura 2 se esquematiza la metodología empleada para construir la aplicación informática.
Análisis y resultados
En adelante, se detallan siete hallazgos de la investigación. El primer resultado especifica el método planificado, el cual consta de tres etapas propuestas por el LAPID y ejecutado por el estudiantado (Figura 2). Entre la innovación de metodologías aplicadas a los procesos de enseñanza y aprendizaje, se destaca a la persona estudiante como el centro del proceso. En la Tabla 3 se muestra la trazabilidad de las competencias, los resultados de aprendizaje y las habilidades de cada etapa que se desarrolla durante el curso de la PPS.
Tabla 3 Conjunto de competencias, resultados de aprendizaje y habilidades desarrollados
| I Etapa. Preparación y transformación de las imágenes | ||
|---|---|---|
| Competencias | RA | Habilidades |
| C1 | RA 1.1. | Conocimientos de |
| C3 | RA 3.1. | Conversión de imágenes |
| Recorte y rotación | ||
| Ajuste de color y contraste | ||
| Segmentación | ||
| Extracción de datos | ||
| Limpieza de los datos | ||
| Cambios de formatos de datos | ||
| Binarización | ||
| C2 | RA 2.1. | Lenguaje Python |
| Manipulación de datos | ||
| Manejo de archivos | ||
| RA 2.4. | Manejo de bibliotecas de procesamiento de imágenes | |
| II Etapa. Creación y entrenamiento de la red neuronal | ||
| C3 | RA 3.3. | Álgebra lineal |
| RA 3.1. | Construcción de redes neuronales | |
| RA 3.2. | Experiencia en la división de conjuntos de entrenamiento | |
| C2 | RA 2.2. | Arquitectura de las redes neuronales, capas, funciones de activación y conexiones |
| RA 2.3. | Bibliotecas de aprendizaje automático | |
| RA 2.3. | Normalización de datos | |
| RA 2.1. | Depuración de datos | |
| Manejo de datos faltantes | ||
| III Etapa. Interpretación de resultados | ||
| C5 | RA 5.1. | Validación y pruebas |
| Optimización y entrenamiento de redes para el descenso de gradiente como el descenso de gradiente como el descenso de gradiente estocástico (SGD) | ||
| Comprender el problema | ||
| Métricas de evaluación | ||
| Visualización de resultados | ||
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
Tabla 4 Lista de componentes para la creación del modelo de desarrollo
| Componente | Tipo | Clasificación | Funcionalidad |
|---|---|---|---|
| Cv2 | Librería | Imágenes | Utilizada para el tratamiento de imágenes. Incluye la carga, la visualización, la manipulación y el filtrado de imágenes. |
| Os | Módulo | Sistema operativo | Utilizado para la funcionalidad del sistema operativo. |
| Pycaret | Librería | Machine Learning | Utilizada para el aprendizaje automático en el desarrollo de modelos de ML. |
| Numpy | Función | Machine Learning | Utilizada para ejecutar cálculos lógicos y matemáticos (vectores y matrices de grandes dimensiones). |
| Pandas | Biblioteca | Machine Learning | Utilizada para la manipulación y análisis de datos. |
| Matplotlib | Librería | Machine Learning | Utilizada para la creación de gráficos de datos y de modelos de aprendizaje automático. |
| Tensorflow | Librería | Machine Learning Redes neurales | Utilizada para construir y entrenar redes neuronales. |
| Sklearn o Scikit-learn | Librería | Machine Learning | Utilizada para hacer análisis predictivo. |
| Keras | Librería | Redes neurales | Utilizada para programar las redes neuronales |
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
El segundo resultado es la construcción de la Tabla 4, en la que el estudiantado identifica y clasifica los componentes utiliza dos en este modelo, basándose en tipos, clasificación y funcionalidad para crear el modelo de desarrollo y la CNN. Todos los componentes de esta tabla se emplean en el código de Python, el cual, finalmente, es un código que implementa una aplicación informática.
El tercer resultado involucra el diseño de una rúbrica, la cual es una herramienta esencial para evaluar los aprendizajes en las áreas de manejo de imágenes, IA y aprendizaje automático, algoritmos de aprendizaje automático en Python, bibliotecas y frameworks de aprendizaje automático y la programación, y desarrollo de modelos de redes neuronales. Paralelo a esto, la rúbrica le permite a la persona académica la retroalimentación hacia el estudiantado, logrando, así, la equidad y la transparencia en la evaluación (Casco et al., 2020).
Tabla 5 Rúbrica para evaluar los aprendizajes.
| Manipulación de imágenes | |||
|---|---|---|---|
| Avanzado | Competente | Básico | Insuficiente |
| Aplica acciones y cambios avanzados en imágenes y demuestra destreza y creatividad. | Aplica acciones y cambios efectivos en imágenes. | Aplica acciones básicas, pero debe mejorar el manejo adecuado de los atributos. | No puede aplicar acciones en imágenes. |
| Conocimientos de IA y aprendizaje automático | |||
| Avanzado | Competente | Básico | Insuficiente |
| Demuestra un amplio conocimiento de los conceptos e IA y aprendizaje automático. | Identifica, de forma correcta, conceptos de IA y aprendizaje automático. | Demuestra un conocimiento ligero de los conceptos de IA y aprendizaje automático. | No puede identificar los conceptos mencionados. |
| Implementar algoritmos de aprendizaje automático en Python | |||
| Avanzado | Competente | Básico | Insuficiente |
| Demuestra, de forma excepcional, cómo se describe y depura el código complejo de aprendizaje automático en Python. | Describe y depura el código para implementar algoritmos de aprendizaje automático en Python. | Describir y depurar código básico de aprendizaje automático en Python. | No puede describir ni depurar código en Python. |
| Uso de biblioteca y frameworks de aprendizaje automático | |||
| Avanzado | Competente | Básico | Insuficiente |
| Utiliza bibliotecas y frameworks de manera experta. | Utiliza bibliotecas y frameworks específicos de aprendizaje automático, de manera competente. | Es consciente de las bibliotecas y frameworks, pero tiene dificultades para usarlos. | No puede usar bibliotecas ni frameworks de aprendizaje automático |
| Programación y desarrollo de modelos de redes neuronales | |||
| Avanzado | Competente | Básico | Insuficiente |
| Demuestra, de forma excepcional, la programación y el desarrollo de modelos de redes neuronales. | Aplica, de manera eficaz, la programación y la implantación de modelos de redes neuronales. | Realiza intentos básicos de programación y desarrollo de modelos de redes neuronales. | No puede aplicar la programación ni la implementación de modelos de redes neuronales. |
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
El cuarto resultado involucra el código en Python generado por la persona estudiante, el cual puede ser consultado en sitio web del LAPID. La elaboración de este código fue guiada por la persona docente, siguiendo la metodología del LAPID. Se adjunta par cialmente, en la Tabla 6, el código para la creación del modelo y cómo entrenarlo.
Dicho lo anterior, la primera fila es un código que permite crear una CNN para la clasificación binaria de imágenes de entrada de 224 x 224 píxeles en blanco y negro. Esta red contiene múltiples capas de convolución y un max-pooling, el cual consiste en una operación para resguardar las características más importantes de la imagen, pues reduce su resolución espacial; además, incluye otras dos capas: las densas y las dropout, para evitar el sobreajuste. La segunda fila entrena el modelo de la CNN utilizando el conjunto de datos de mamografías de entrenamiento y ajusta varios parámetros y
Tabla 6 Código para definir, crear y entrenar la red neuronal de convolución
| Creación del modelo El código define una arquitectura de modelo de red neuronal de convolución (CNN); utiliza la biblioteca Keras en Python. | def create_model(): |
| model = Sequential() | |
| model.add(Conv2D(32, kernel_size=(3,3) , | |
| activation=’relu’,input_shape=(224, 224, 1))) | |
| model.add(Conv2D(64, kernel_size=(3,3),activation=’relu’)) | |
| model.add(MaxPool2D(pool_size=(2, 2))) | |
| model.add(Conv2D(64, kernel_size=(3,3),activation=’relu’)) | |
| model.add(MaxPool2D(pool_size=(2, 2))) | |
| model.add(Dropout(0.25)) | |
| model.add(Dense(64, activation=’relu’)) | |
| model.add(Dropout(0.25)) | |
| model.add(Flatten()) | |
| model.add(Dense(1, activation=’sigmoid’)) | |
| Entrenamiento del modelo Este código entrena el modelo de red neuronal haciendo uso de un conjunto de datos de entrenamiento. | return model |
| hist = model.fit(x_train_filtered, | |
| y_train, | |
| validation_split=0.2, | |
| epochs=10, | |
| batch_size=64, | |
| callbacks=(early_stop, model_check_point)) |
Tabla 7 Valores de entrenamiento de la red neuronal de convolución
| Época | Pérdida de entrenamiento | Precisión de entrenamiento | Pérdida de validación | Precisión de validación |
|---|---|---|---|---|
| 1 | 1,2394 | 0,5472 | 0,68392 | 0,5488 |
| 2 | 0,6560 | 0,6062 | 0,62771 | 0,6334 |
| 3 | 0,5847 | 0,6783 | 0,53949 | 0,7183 |
| 4 | 0,4829 | 0,7608 | 0,40146 | 0,8311 |
| 5 | 0,3581 | 0,8380 | 0,32128 | 0,8586 |
| 6 | 0,2495 | 0,8956 | 0,24107 | 0,8955 |
| 7 | 0,1850 | 0,9236 | 0,15873 | 0,9414 |
| 8 | 0,1410 | 0,9458 | 0,13121 | 0,9506 |
| 9 | 0,1211 | 0,9532 | 0,11778 | 0,9548 |
| 10 | 0,1058 | 0,9598 | 0,1182 | 0,9550 |
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
configuraciones, incluyendo la división de validación, el número de épocas, el tama ño del lote y funciones de que monitorear y guardar el progreso del entrenamiento.
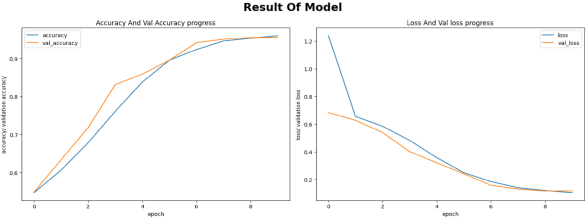
En el quinto resultado se muestra los valores obtenidos al entrenar la CNN. Estos datos resultantes, por un lado, se analizan con la persona estudiante, por lo que debe ser capaz de interpretar los valores para evidenciar su aprendizaje. Por otro lado, y para esta investigación, se interpretan los valores resultantes, del entrenamiento del modelo y se tabulan en la Tabla 7; se presentan los valores de pérdida y precisión en el conjunto de entrenamiento y validación para cada una de las diez épocas. Cada fila corresponde a una época específica y las columnas muestran la pérdida en el conjunto de entrenamiento, la precisión en el conjunto de entrenamiento, la pérdida en el conjunto de validación y la precisión en el conjunto de validación para esa época. Ahora bien, se puede analizar también desde la Gráfica 1.
Dicho lo anterior, se analizan los va lores detallados en la Tabla 7, que corresponde a la pérdida y la precisión con respeto a los datos del conjunto de entrenamiento y el conjunto de validación a lo largo de las diez épocas. Por tanto, sobre el primero, se indica que los datos inician con 1,2394, en la primera época, y disminuye a 0,1058 en la décima época; sugiere que el modelo está mejorando la capacidad de entrenarse, lo cual se conoce como pérdida. Por último, la precisión se genera al observar que hay un aumento gradual de 0,5472 en la primera época, a 0,9598 en la décima época, porque el modelo está aprendiendo a clasificar de forma correcta.
En cuanto al conjunto de validación, este inicia en 0,68392, en la primera época, y llega a 0,1182, en la décima época. Esto es positivo porque hay una disminución cuando avanzan las épocas. Sugiere, entonces, que el modelo ajusta los datos del entrenamiento, y esto se conoce como la precisión del conjunto de entrenamientos. Paralelo a esto, se observa que la precisión aumentó a lo largo de las épocas y logró un valor de 0,9550, en la décima época.
Durante el periodo de la PPS las personas académicas y el estudiantado concluyeron que el entrenamiento fue positivo, tanto en la pérdida como en la precisión de los conjuntos de entrenamiento y validación; pues siempre mostró una mejoría conforme se ejecutaron los ciclos, y esto sugiere que el modelo aprendió, de forma efectiva, por lo que tiene una precisión de 95,50 % para clasificar los datos. Estos resultados pueden verse en El Gráfico 1.
El sexto resultado es la interpretación de la matriz de confusión, la cual se obtiene al evaluar el modelo de clasificación y muestra la cantidad de predicciones correctas e incorrectas, a partir de los valores reales del conjunto de datos de prueba. Por tanto, la Tabla 8 representa los valores que dan como resultado la matriz de confusión.
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
Gráfico 1 Modelo de resultados de la red neuronal
Tabla 8 Reporte de clasificación
| Clases | Precisión | Recall | F1-score | Support |
| 0 | 0,87 | 0,91 | 0,89 | 3373 |
| 1 | 0,93 | 0,9 | 0,92 | 4619 |
| Accuracy | 0,91 | 7992 | ||
| Macro avg | 0,9 | 0,91 | 0,9 | 7992 |
| Weighted avg | 0,91 | 0,91 | 0,91 | 7992 |
Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024
El reporte de clasificación y la matriz de confusión del modelo permiten medir el rendimiento de la cantidad de predicciones correctas e incorrectas cuando son ejecutados con valores reales del conjunto de datos de pruebas (25 % de las imágenes).
Para la clase “0”, representa la clase negativa, es decir, las mamografías benignas; y “1”, la clase positiva, por ende, las mamografías malignas.
Las métricas de evaluación sirve, para interpretar la precisión, donde la clase “0” es del 87 %, lo cual significa que 87 % de las mamografías, clasificadas como benignas por el modelo, eran realmente benignas. La métrica de precisión para la clase “1” es del 93 %, es decir, el 93 % de las mamografías clasificadas como malignas por el modelo, eran realmente malignas.
Para la clase “0”, el recall es una métrica que mide la proporción de casos positivos reales, identificados de forma correcta por el modelo, por lo que el recall es de 91 %, esto significa que el 91% de las mamografías malignas reales fueron identificadas correctamente, en tanto que para la clase “1”, el recall es del 90 %, lo cual indica que el 90 % de las mamografías malignas reales fueron identificadas correctamente.
El F1-score es otra métrica que permite interpretar la precisión y el recall como una sola medida, y se encontró que el F1-score, para la clase “0”, es del 0,89; y, para la clase “1”, es del 0,92. Finalmente, la métrica accuracy evidencia cuánto el modelo acierta en las predicciones (positivas y negativas). En este caso, tiene una exactitud del 91 % en sus predicciones.
En el Gráfico 2 se puede interpretar correctamente los resultados de la siguiente manera.
Verdaderos positivos. Estos corresponden a los casos en los que el modelo predice la clase 1 y la clase verdadera también es 1. En la matriz de confusión, el valor 4160, ubicado en la matriz en la segunda fila y columna. Se interpreta que el modelo identificó correctamente 4160 casos como positivos.
Verdaderos negativos. Ocurre en los casos en los que el modelo predice la clase y la clase verdadera también es 0. En la matriz de confusión, el valor en la matriz es 3079, ubicado en la primera fila y primera. Se interpreta que el modelo identificó correctamente 3079 casos como negativos.

Nota. Investigación y propuesta de Johnny Villalobos Murillo, Gabriela Garita González y Byron Jesús Alfaro Ramírez, 2024.
Gráfico 2 Matriz de confusión
Falsos positivos. Estos son los casos en los que el modelo predice la clase 1, pero la clase verdadera es 0. En la matriz de confusión el valor es 294, ubicado en la matriz: primera fila y segunda columna, interpretación. Se interpreta que el modelo identificó incorrectamente 294 casos como positivos cuando en realidad eran negativos.
Falsos negativos. Estos son los casos en los que el modelo predice la clase 0, pero la clase verdadera es 1. En la matriz de confusión, el valor es 459, ubicado en segunda fila y primera columna. Se interpreta que el modelo identificó incorrectamente 459 casos como negativos cuando en realidad eran positivos.
Además, se evalúa el rendimiento del modelo de clasificación, mostrando, por medio de la matriz de confusión (Gráfico 2), la cantidad de predicciones correctas e incorrectas ejecutadas por el modelo, en comparación con los valores reales del conjunto de datos de pruebas. En resumen, los resultados de las métricas indican que el modelo desarrollado tiene un rendimiento consistente, en la clasificación de mamografías benignas y malignas, con altas precisiones, recalls y F1-scores para ambas clases, y una alta exactitud en general. Esto sugiere que el modelo es efectivo en su tarea de detección.
El séptimo resultado es la creación de la aplicación informática, la cual esta pública en el sitio web del LAPID y puede ser probado con otras imágenes, que cumplan con los formatos indicados. En la Figura 3 se muestra la interfaz principal.
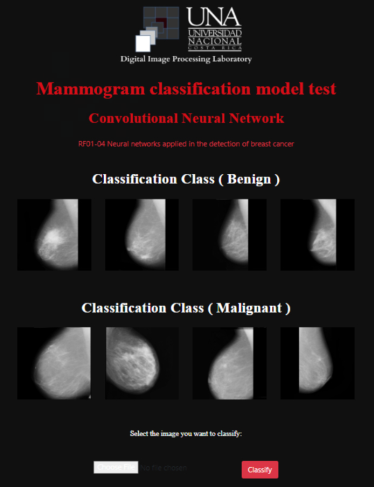
Nota. Tomado de Suckling et al. (2015).
Figura 3 Aplicación informática para clasificar mamografías malignas y benignas Pantalla de ingreso de los datos que permite cargar una imagen para ser clasificada.
Conclusiones
Este estudio ofrece contribuciones significativas al panorama de la investigación en AI, específicamente en el ámbito de diagnóstico por imágenes. Además, refuerza las competencias necesarias en las futuras personas profesionales en informática y computación, mejorando las habilidades en programación, resolución de problemas, uso del aprendizaje automático y las redes neuronales. Se subraya el valor formativo en estas tecnologías del estudiantado que realiza su práctica profesional para finalizar su grado en bachillerato.
El LAPID ha desarrollado modelos y algoritmos inspirados en el sistema de visión humana, ofreciendo almacenamiento, manipulación y análisis de imágenes. También, ha brindado espacios para que el estudiantado desarrolle competencias y experiencias en IA. Se estableció un marco de competencias y resultados de aprendizaje que guía los procesos de enseñanza y aprendizaje.
Actualmente, en la carrera, no incluye cursos de AI ni como asignaturas troncales ni optativas, lo cual impide que estudiantes desarrollen plenamente competencias deseadas en esta área antes de finalizar el grado. Esto sugiere la necesidad de replicar actividades académicas como las descritas en este estudio.
Se destaca la propuesta del modelo que genera siete resultados estructurados para guiar al estudiantado y experimentara con IA. Según los resultados, se puede destacar: el diseño y uso de una metodología de enseñanza y aprendizaje definida en tres etapas: la preparación, la enseñanza y el aplicativo, que involucra la transformación de imágenes, la creación y el entrenamiento de una red neuronal de convolución. La innovación está en involucrar al estudiantado y lo centra como el actor principal en el proceso de enseñanza y aprendizaje, cuando desarrolla la práctica profesional. Seguido, la definición del marco de competencias y resultados de aprendizaje delimita los alcances durante el PPS y enmarca habilidades y valores a desarrollar. Además, se identifican componentes y herramientas asociados al lenguaje de programación Python, para el desarrollo del modelo, incluidas el procesamiento de imágenes y la construcción de modelos de aprendizaje automático. La rúbrica es un aspecto relevante de esta investigación, que permite evaluar las competencias del estudiantado y, con ello, medir el desempeño en el proceso mismo de aprendizaje. Por último, se analizaron los valores del entrenamiento de la red neuronal de convolución, que, en general, evidencian que el conjunto de resultados es efectivo en la clasificación de mamografías. Para finalizar este estudio, demostró ser una forma innovadora de reforzar competencias en el estudiantado desde una actividad académica.
En conclusión, este estudio demuestra ser una forma innovadora de reforzar competencias en el estudiantado a través de actividades académicas. Además, puede generar implicaciones y nuevos caminos para futuras investigaciones, siendo crucial evaluar si las competencias propuestas en AI en este estudio, son relevantes y suficientes para las próximas generaciones de profesionales.

