









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
De acuerdo con la Organización de las Naciones Unidas (ONU) (1987), el desarrollo sostenible se define como la satisfacción de las necesidades de las generaciones presentes sin afectar las de las generaciones futuras. Esto se logra a través del aprovechamiento racional de los recursos naturales y el balance de tres principales ejes: social, económico y ambiental. Con la meta mundial de cumplir ese desarrollo sostenible, para proteger el planeta y que todas las personas gocen de paz al 2030, se crearon los Objetivos de Desarrollo Sostenible (ODS). La ONU (2017) menciona que para alcanzar esta meta mundial, se necesitan recursos financieros, conocimiento y tecnologías.
Costa Rica como un referente mundial en estrategias ante el cambio climático y protección de recursos naturales, fue el primer país en firmar el acuerdo de los ODS y en crear una agenda 20-30 acorde al cumplimiento de estas metas. La preocupación de Costa Rica por establecer dichas estrategias es proteger los servicios ecosistémicos que sostienen la economía del país como turismo ecológico, aprovechamiento maderero y actividades agrícolas, además de mitigar el cambio climático, esto según el Observatorio de la Normativa Ambiental (2011).
Específicamente para la actividad agrícola y en seguimiento a la implementación de estrategias de protección al ambiente, en el 2011, el Ministerio de Ambiente y Energía (MINAE), a través de su unidad técnica denominada Centro Nacional de Información Geoambiental (CENIGA), estableció el Sistema Nacional de Información Ambiental (SINIA) con el propósito de gestionar la información geo-ambiental del país. En esta línea, explican Sasa (2019) y Vargas et al. (2020), surgió el Monitoreo de Cambio de Uso en Paisajes Productivos (MOCUPP), el cual, liderado por el PNUD y acompañado por el CENIGA, busca, a través de la vinculación con los ODS, monitorear los territorios con cultivos agrícolas de piña, pastos y palma aceitera del país, e identificar las zonas de cambio de cobertura principalmente en cobertura arbórea.
MOCUPP ha sido una herramienta importante en el reporte preciso de las coberturas de los principales cultivos, como lo es la piña. Vargas et al. (2020) señalan que en el 2018, MOCUPP publicó a través del Laboratorio PRIAS del Centro Nacional de Alta Tecnología, la existencia de 65 670,68 ha totales del paisaje productivo de piña. Por su parte, Fernández (2018) muestra que ese mismo año, otros informes declararon 44 000 ha totales del cultivo.
A nivel mundial, Costa Rica es reconocido como principal exportador de piña, esto en palabras de FAO, (2020). Según los Informes Estado de la Nación (2015) y Estado de la Nación (2019), la piña se destina principalmente hacia Estados Unidos y la Unión Europea. Las exportaciones de la fruta incrementaron de $806 millones en 2015 a $987 millones en 2018 según la Promotora de Comercio Exterior (PROCOMER) (2022). Vargas et al. (2020) en 2018 continúan explicando que, a nivel nacional, la región Huetar Norte aportó, al año 2018, un 67% del cultivo total de piña del país, eso significa alrededor de 44 193,75 ha totales. Guti (2019) destaca, además, que el 98% de pequeños y medianos productores de piña se concentran en dicha región.
De acuerdo con el Ministerio de Agricultura y Ganadería (MAG) (2007), la producción de la piña en Costa Rica ha tendido al crecimiento a lo largo de los años; el MAG y la Cámara Nacional de Productores y Exportadores de piña (CANAPEP), coinciden en que este incremento se debe a la apertura de mercados internacionales y a la demanda de la variedad de piña MD-2. En contraste, Obando (2015) y Guevara et al. (2017) exponen que la cantidad de pequeños y medianos productores ha disminuido, en el 2015 se reportó alrededor de 1900 productores, 550 en el 2017 y se estima una cantidad menor a esta última para la actualidad.
En este contexto, surgen algunos planteamientos importantes. En primer lugar, conocer los factores explicativos del comportamiento del cultivo y la tendencia al incremento en área, aun cuando se ha reportado la salida de una gran cantidad de pequeños y medianos productores. Segundo, la importancia de seguir monitoreando los cultivos como una estrategia de implementación de tecnología y conocimiento para la disminución del riesgo de deforestación y cumplimiento de los ODS, en particular, el objetivo número 13, denominado Acción por el clima, y el número 15, Vida de ecosistemas terrestres. Finalmente, y en conjunto con los planteamientos anteriores, cuestionarse cómo podría comportarse el cultivo en el futuro para tomar decisiones en el momento pertinente y desarrollar estrategias como las que se han venido implementado, sin afectar ningún eje del desarrollo sostenible.
Investigaciones como las realizadas por Barrantes-Sotela y Sandoval-Murillo (2016) aseguran que los estudios de uso y cobertura de la tierra pretenden alcanzar una correcta gestión y conservación de los recursos naturales y el territorio, con el fin de lograr un desarrollo sostenible. Esta gestión se traduce en acciones, principalmente regulaciones y políticas locales o globales. Por su parte, las tecnologías de modelamiento permiten proyectar escenarios futuros, lo que ha hecho posible la ejecución de estudios como el realizado en la microcuenca Santa Inés, Honduras, donde se aplicó una modelación de cambios de cobertura y uso en varios escenarios, lo cual permitió analizar los resultados y priorizar acciones para la conservación del recurso hídrico del lugar, todo lo anterior explicado por Medardo (2015).
Este último cuestionamiento motivó a la formulación del presente estudio, el cual busca, bajo la línea de cumplimiento de los ODS anteriormente identificados, encontrar las razones del comportamiento actual del cultivo de la piña y los factores que le influyen, para predecir su comportamiento futuro. Esto se puede lograr a través del uso de tecnologías de modelamientos que toman como base lo que sucede actualmente y parten del supuesto de que se mantiene una tendencia a lo largo del tiempo.
En este sentido, la presente investigación simuló la cobertura del cultivo de piña a partir de las variables impulsoras del cambio, con el fin de proponer una herramienta que permita a las personas tomadoras de decisiones, establecer estrategias basadas en datos que favorezcan tanto el crecimiento económico, como la protección de los recursos naturales del entorno donde se desarrolla la actividad productiva.
Área de estudio
Este proyecto se desarrolló en los cantones de Upala y los Chiles en la Región Huetar Norte de Costa Rica.
Upala y Los Chiles, Región Huetar Norte
La Región Huetar Norte (RHN) abarca un área de 7 662,46 km2 según el MAG (2011). Está conformada por los cantones de Los Chiles, Upala, San Carlos, Guatuso, Río Cuarto y Sarapiquí de Heredia; así como los distritos de Sarapiquí del cantón de Alajuela, y Peñas Blancas del cantón de San Ramón.
El límite Norte es la frontera con Nicaragua, lo que le da socialmente biculturalidad y un alto flujo migratorio. Granados et al. (2015) exponen que sus paisajes son, mayoritariamente, rurales con ganadería y cultivos agrícolas como tubérculos, cítricos y piña.
La región registra temperaturas medias de 26°C en las zonas más bajas y 20°C en zonas más elevadas; la precipitación promedio anual va de 3 000 mm hasta los 4 500 mm, esto según el Instituto de Desarrollo Rural (INDER) (2015).
Por otro lado, Valverde y Acuña (2011) dicen que el cantón de Los Chiles está ubicado entre las coordenadas 10°51’28°” Latitud Norte y 84°40’37” Longitud Oeste. Según los datos del Instituto Nacional de Estadísticas y Censos (INEC) (2015), Tiene una extensión de 1 358,8 km2, y una población total aproximada de 28 694 personas. Vargas et al. (2020) en el 2018 continua explicando que en 2018, este cantón reportó 8 649,30 ha de cultivo de piña.
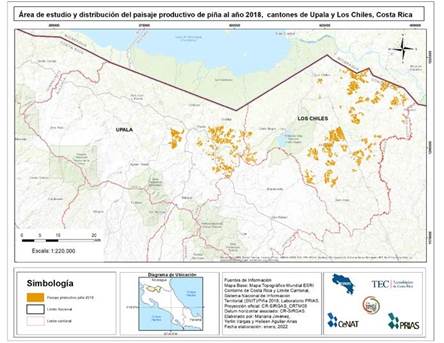
El cantón de Upala se ubica entre las coordenadas 10°52’11” Latitud Norte y 85°09’57” Longitud Oeste, esto según los datos proporcionados por Valverde y Acuña (2011). El INEC (2015) detalla que este sector comprende una superficie de 1 508,7 km2 y una población aproximada de 48 910 personas. Además, de acuerdo con Vargas et al. (2020), en el año 2018 se reportaron 3 610,61 ha de cultivo de piña en este cantón. En la Figura 1 se observa el mapa correspondiente del área de estudio.
Materiales y métodos
Identificación de variables impulsoras del cambio en la cobertura de la piña
A partir de información recopilada de diversas fuentes, se construyó una base de datos inicial de productores de piña de la zona, a los cuales se les aplicó una entrevista semi estructurada para identificar y Figura 1. Mapa de la ubicación del área de estudio
validar variables sociales, económicas y ambientales que han determinado la dinámica del cultivo en el sitio de estudio durante el período 20152018. En la entrevista se les consultó a los productores si aumentaron o disminuyeron las hectáreas cultivadas de piña, los motivos económicos (elementos de mercado, accesibilidad y preferencia de los proveedores de insumos, compradores, entre otros), ambientales (plagas y enfermedades, condiciones climáticas, entre otros) o del contexto social (presiones socio ambientalistas, disponibilidad y condiciones de la mano de obra, cambio de tipo de cultivo a piña, entre otros) que influyeron en esos cambios; el año que realizaron el cambio; entre otros aspectos relacionados a la distribución geográfica. La variable dependiente fue cambio de cobertura de piña. Las variables independientes corresponden a las variables sociales, económicas y ambientales correlacionadas con los cambios de cobertura del cultivo. Martínez et al. (2000), Granados et al. (2015) y Guevara et al. (2017) están de acuerdo en que el análisis estadístico se realizó por medio de los métodos de asociación y correlación Fisher y biserial puntual (rbp), respectivamente; además las pruebas se ejecutaron utilizando el programa Statistical Package for the Social Science (IBM® SPSS®) versión 26.0 y Excel con un nivel de confianza de 95%.
Datos de entrada para el modelamiento
Todos los datos fueron rasterizados en el programa QGis 3.14.15 (en adelante mencionado como QGis) con una extensión “Capa máscara” creada desde un archivo de tipo texto (.txt) con las coordenadas límite de la zona de estudio. El tamaño de píxel utilizado en todas las capas fue 30 m x 30 m. Según Argemiro et al. (2020), el tipo de dato fue configurado a Signed integer 32 bits (Int32) mediante la herramienta de conversión “Traducir” del menú raster. Este proceso debe verificarse en las propiedades de la capa, ya que es indispensable que las capas tengan el mismo formato de datos, tamaño de filas y columnas para los modelos de simulación.
Cobertura de piña del periodo 2015-2018
Las capas anuales de la cobertura de piña, en formato vectorial, fueron obtenidas desde el servicio Open Geospatial Consortium (OGC) del nodo externo del “MOCUPP Piña” disponible en el sitio virtual del SNIT (https://www.snitcr.go.cr/ico_servicios_ogc_info?k=bm9kbzo6MT Y=&nombre=MOCUPP%20Pi%C3%B1a). Estas fueron cortadas única-
mente para el área de estudio y sus atributos fueron disueltos por cantón, a los cuales se les calculó el área (ha) para cada uno de ellos. Dichos resultados fueron rasterizados en el “Modelador gráfico” del menú “Procesos” del programa QGis. De forma tal que se crearon dos clases para el análisis asignando donde el valor 1 correspondió a la clase Piña y el valor 2 a la clase No Piña.
Variables espacializadas
Distancia a sitios de interés
Los sitios de interés indicados se obtuvieron a partir de los resultados de las entrevistas fueron ubicados por medio de puntos geográficos mediante el programa Google Earth, desde donde se exportaron hacia QGis en un archivo formato Keyhole Markup Language (KML). Para calcular las distancias a estos sitios, se desarrolló un modelo mediante el “Modelador gráfico” del menú “Procesos” del programa QGis.
Cada archivo vectorial que contenía los sitios de interés fue rasterizado con un tamaño de píxel 30 m x 30 m, para crear las capas de distancias. Para ello se utilizó el plugin “Proximidad” (distancia raster) disponible en el menú “Procesos” de la extensión GDAL.
Clima
Los datos climáticos empleados fueron precipitación media anual en milímetros (mm) y temperatura media anual en grados Celsius (°C). Se consultó las estaciones termo-pluviométricas dentro del área de estudio y su ubicación a través del sitio virtual de Estaciones automáticas del Instituto Meteorológico Nacional (IMN) (https://www.imn.ac.cr/estaciones-automaticas). Por otro lado, los datos de precipitación y temperatura mensuales para cada año fueron extraídos a partir de los boletines meteorológicos disponibles a través del sitio virtual (https://www.imn.ac.cr/boletin-meteorologico) y procesados en tablas dinámicas de Excel para estimar los promedios o datos acumulados. Se evaluaron distintos métodos de interpolación, con el fin de determinar cuál de ellos espacializaba mejor la variable.
Suelo
La Universidad de Costa Rica (UCR) (2016), señala que las capas en formato vectorial de órdenes de suelo se obtuvieron de la plataforma virtual del Centro de Investigaciones Agronómicas (CIA) de la Facultad de Ciencias Agroalimentarias de la Universidad de Costa Rica. La capa se disolvió por atributo de órdenes; la capa disuelta fue previamente reclasificada en valores numéricos absolutos para su rasterización. La variable suelo corresponde a los órdenes de suelo que traslapan con el paisaje productivo de piña.
Modelamiento
Se seleccionó el programa de descarga libre DINAMICA EGO versión 5.0 (en adelante mencionado como DINAMICA) ya que, además de ser una interfaz bastante intuitiva, tiene compatibilidad de los datos de entrada y salida con programas como QGis o ArcGis, un sólido respaldo bibliográfico de su librería y de modelos de simulación preestablecidos aptos para el alcance de este proyecto.
Mas y Flamenco (2011) y, posteriormente, Mas et al. (2017) indican que DINAMICA utiliza los autómatas celulares expander que consiste en la expansión o contracción de las áreas adyacentes; y patcher que crea nuevas áreas desde un punto “semilla”. Para simular los mapas de cambio, se basa en las variables explicativas y los pesos de evidencia obtenidos en la calibración.
Calibración del modelo
Construcción del cubo raster
Las variables explicativas de los cambios deben ingresar al modelo como un archivo multicapa llamado cube map. Se creó un cube map con las variables espacializadas en QGis que resultaron relacionadas con los cambios de cobertura de piña. El formato del archivo de salida es ER Mapper Data Format (ers) de ERDAS.
El modelo se calibró con el objetivo de que hubiese una mayor proporción de cambios en el expander para no alterar la apariencia real de la cobertura. El patcher se configuró para ser disperso y crear áreas pequeñas, tal como se ve en la cobertura real de la piña, donde las áreas cultivadas son dispersas, no uniformes y pequeñas.
Los mapas de entrada fueron las capas correspondientes a los años 2015, 2016 y 2017, debido a la disponibilidad de información, y estos fueron los utilizados a lo largo del modelo. En steps se especificó la cantidad de años transcurridos en ese periodo. Campos (2018) dice que el modelo puede construirse para analizar el intervalo de tiempo completo (single step), o bien, para cada periodo de tiempo según la cantidad de pasos especificados.
El modelo requiere reclasificar las variables continuas en variables categóricas para calcular los pesos de evidencia, manteniendo la estructura original de los datos. Para ello, estima los rangos de peso, que son buffers creados a partir de intervalos de datos. Los insumos del modelo fueron los mapas correspondientes a los años de estudio y el cubo raster de variables explicativas, los cuales se añadieron con Load categorial map y Load map respectivamente. El functor de este modelo funcionó cuando el skeleton se completó con los parámetros de cada transición y variable. Se aconseja que para completar el skeleton, únicamente se varíe el valor delta mínimo y se mantengan los demás valores por defecto que establece el modelo. Si se conoce bien la estructura de los datos y variables, se puede modificar los demás parámetros hasta obtener los rangos deseables, esto siguiendo las palabras de Soares et al. (2009).
Según Espinoza (2016) y Zamora y CATIE (s.f), el cálculo de coeficientes de peso en cada transición es un proceso de DINAMICA que estima el peso que tiene cada una de las variables y su influencia en el cambio de categorías (transición), para ello se analiza cada variable, de forma independiente, en cada uno de los rangos previamente creados. Asimismo, Soares et al. (2010) y Mas y Flamenco (2011) dicen que los coeficientes de peso se obtienen de una probabilidad condicional, es decir, la probabilidad de que se cumpla un hecho “A” sí y solo sí se cumple un hecho “B”.
Espinoza (2017), continúa diciendo que este paso se completa una vez que se haya procesado el modelo de rangos de peso. La salida fue la tabla con los pesos de evidencia, que contenía el coeficiente de peso (W) por cada variable en cada transición. Cuando W es menor a cero entonces indica que inhibe la transición; cuando es igual a 0 no tiene efecto sobre la transición y cuando es mayor a 0, indica que favorece la transición. En la visualización de la salida del modelo se analizaron los gráficos con las líneas de tendencia entre los coeficientes de peso y los valores por cada variable en cada transición según Soares et al. (2009). En este paso se omitieron los rangos que estuvieran por debajo de cero según los gráficos de cada variable.
Vargas et al., 2020 y Martínez et al. en el 2000, así como Mas et al. (2017), explicaron que este paso permitió la validación el supuesto de independencia de las variables espacializadas empleadas en el modelo. La salida fue una tabla con resultados de diferentes índices de asociación. Para validar el supuesto de independencia de las variables se utilizó el índice Cramer, el cual analiza el grado de relación o asociación entre dos variables. Según Macedo (2013), entre más cercanos a 1 se encuentren los resultados mayor dependencia muestran entre sí, por lo que para el presente estudio se omitieron las variables que presentaron un índice Cramer mayor al umbral 0,5 con el fin de identificar las variables independientes.
Este paso fue el último, previo a ejecutar la simulación. Utilizó como entrada el mapa de la cobertura inicial. En el submodelo Repeat se definió la cantidad de años o pasos a modelar. Además, se calibró el functor Calc WOE (Weights Of Evidence) de forma tal que el resultado fuese un mapa lo más cercano posible al mapa del paisaje productivo de piña, al año 2018, elaborado por el Laboratorio PRIAS del CeNAT (Centro Nacional de Alta Tecnología), (en adelante mapa real 2018). Se realizaron las modelaciones cambiando los mapas iniciales (2015, 2016 y 2017) y se ajustó la cantidad de años en cada cambio.
El mapa simulado se comparó con el mapa real 2018 mediante el índice kappa, utilizando la herramienta “r.kappa” del menú GRASS del programa QGis, la cual permitió determinar la precisión del modelo. Este índice permitió explicar la relación de similitud entre los valores reales y simulados, se considera pobre cuando los valores son cercanos a 0 y perfecto cuando son cercanos a 1, de acuerdo con Altman (1990).
Simulación de la cobertura de piña
Una vez que se calibró el modelo, se procedió a simular hasta el año 2028 con el mapa real 2018 como insumo inicial. Seguidamente, se calculó el área simulada por cantón mediante la herramienta raster GRASS r.report.
Zonas de cambio en la cobertura arbórea y áreas silvestres protegidas
Se utilizaron las capas de “Bosque Maduro” y “Áreas de Silvestres Protegidas (ASP)” disponibles en el nodo externo del Sistema Nacional de Áreas de Conservación (SINAC) en el sitio virtual del SNIT (https://www.snitcr.go.cr/ico_servicios_ogc_info?k=bm9kbzo6NDA=&nombre=SINAC). Ambas capas se cortaron a la extensión de los cantones en estudio y se les asignó el valor 1 a cobertura arbórea y 0 al resto de coberturas para el caso de la capa de “Bosque Maduro”. Se utilizó la calculadora raster para comparar contra el mapa simulado de la cobertura de piña e identificar las zonas con cambio de cobertura tanto en la cobertura arbórea como en las áreas silvestres protegidas. La operación raster fue basada en una resta entre la capa simulada de piña al 2028 menos las capas del SINAC:
@2028*10 - capa SINAC (Bosque Maduro) (1) @2028*10 - capa SINAC (ASP) (2)
Donde: @2028 es la capa de piña simulada al 2028
Capa SINAC (Bosque Maduro): corresponde a la capa de Bosque Maduro del 2013 Capa SINAC (ASP): corresponde a la capa de Áreas Silvestres Protegidas
Esto permitió obtener valores de celda entre 10-20 para las clases de Piña y No Piña, respectivamente, los cuales se modificaron por medio de la resta a valores de celda de 9-19 (ASP) y 8-18 (Cobertura arbórea), dónde los valores de nueve y ocho, marcaron las zonas con cambio de cobertura, ya sea de ASP o cobertura arbórea a piña para el año 2028.
Resultados
Con las entrevistas aplicadas, se cubrió un 44,6% del total de hectáreas cultivadas de piña en el cantón de Los Chiles y un 46,2% de las hectáreas cultivadas en el cantón de Upala. Los valores obtenidos para el área total por cantón se especifican en la Tabla 1. Estos valores aumentaron consecuentemente con los años, mostrando una tendencia al aumento.
Tabla 1 Distribución anual del área total cultivada del paisaje productivo de piña en los cantones Upala y Los Chiles, Alajuela, Costa Rica
| Año | Área (ha) Upala | Área (ha) Los Chiles |
|---|---|---|
| 2015 | 2 631,134 | 4 928,209 |
| 2016 | 3 456,246 | 6 486,184 |
| 2017 | 3 394,483 | 8 201,727 |
| 2018 | 3 609,142 | 8 470,647 |
Fuente: Elaboración propia
Identificación de variables impulsoras del cambio en la cobertura de la piña
Los resultados obtenidos del análisis estadístico aplicado a las variables socio económicas y ambientales muestran que las variables “Condiciones del clima y suelo”, “Otros procesados industriales de la piña”, “La demanda de la piña”, “Exporta hacia Europa” y “Distancia a plantas empacadoras” están asociadas a los cambios de cobertura de piña.
Para la variable clima se obtuvo que precipitación promedio anual es los Chiles es de 1550 mm, en el período de estudio, mientras que la precipitación es Upala es de 2502 mm anuales, durante el mismo periodo. La temperatura media anual de Upala ese de 27,22 °C y la de Los Chiles de 27,17 °C. Los datos de las estaciones por cantón fueron interpolados mediante el método IDW (Inverse Distance Weight, por sus siglas en inglés). En el caso de la variable suelo, se encontró que, los órdenes de suelos que coinciden con el área cultivada de piña son del tipo Inceptisoles y Ultisoles.
Calibración del modelo
Los mapas que se utilizaron en el modelo fueron de los años 2016 y 2018. Los valores obtenidos de las matrices de un solo paso, y paso múltiple se resumen en la Tabla 2, Éstos representan el porcentaje de ocurrencia del cambio de una clase a otra. La clase 1 representa la cobertura de Piña y la clase 2 la cobertura de No Piña.
Tabla 2 Matrices de transición obtenidas para el cambio de cobertura del paisaje productivo de piña
| Transición | Multi paso | Paso único |
|---|---|---|
| 1 a 2 | 12% | 31% |
| 2 a 1 | 1% | 2% |
Fuente: Elaboración propia
Los valores en las matrices indican la cantidad de píxeles dentro de una clase que cambian a otra clase. El valor obtenido es proporcional a los píxeles totales pertenecientes a cada clase.
Para el caso de los coeficientes de peso (W) se obtuvo para cada rango un total de 81 transiciones significativas, principalmente de la clase No Piña a Piña. Las variables que favorecen la transición de una clase a otra son: cercanía a planta empacadora, cercanía a las vías principales y precipitación. En la Tabla 3 se resumen las nueve principales transiciones con su respectivo W y contraste. El contraste positivo indica que la variable favorece la transición.
Tabla 3 Pesos de evidencia más significativos de los cambios de cobertura del paisaje productivo de piña
| Transición | Variable | Rango | Coeficiente de peso | Contraste |
|---|---|---|---|---|
| No piña a piña | Distancia a plantas empacadoras | 0-100 | 2,122 | 2,134 |
| Piña a no piña | Distancia a vías principales | 10 000-11 000 | 1,700 | 1,701 |
| No piña a piña | Distancia a plantas empacadoras | 1 000-2 000 | 1,572 | 1,592 |
| No piña a piña | Distancia a plantas empacadoras | 2 000-6 000 | 1,150 | 1,325 |
| No piña a piña | Precipitación | 1 600-1 700 | 0,985 | 1,155 |
| No piña a piña | Distancia a plantas empacadoras | 20 000-21 000 | 0,940 | 0,975 |
| Piña a no piña | Precipitación | 1 900-2 000 | 0,850 | 0,952 |
| No piña a piña | Distancia a plantas empacadoras | 8 000-9 000 | 0,767 | 0,813 |
| No piña a piña | Distancia a plantas empacadoras | 9 000-13 000 | 0,705 | 0,915 |
| No piña a piña | Distancia a plantas empacadoras | 6 000-7 000 | 0,670 | 0,696 |
Fuente: Elaboración propia
La variable Temperatura no generó rangos ni coeficiente de peso. Para la elaboración de los mapas de probabilidad, las variables explicativas evaluadas mediante la prueba Cramer, resultaron todas por debajo del umbral 0,5, por lo que se comprueba el supuesto de independencia entre ellas y ninguna debe eliminarse del modelo.
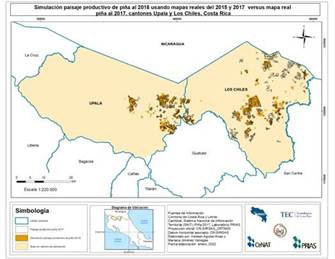
El mapa simulado al 2018 que utilizó como insumo base el mapa del año 2016 fue el utilizado para validar el modelo y se observa en la Figura 2. El mapa de la derecha corresponde al mapa real 2018 facilitado por el Laboratorio PRIAS. El coeficiente kappa obtenido fue 0,547 e indica una similitud moderada. En la Figura 3 se observan de izquierda a derecha los mapas simulados al 2018 utilizando como mapas iniciales el 2015 y el 2017 respectivamente. El coeficiente kappa obtenido del mapa simulado al 2018 a partir del 2015 en contraste al mapa real es de 0,437. Mientras que el del mapa simulado al 2018 a partir del 2017 es de 0,857.
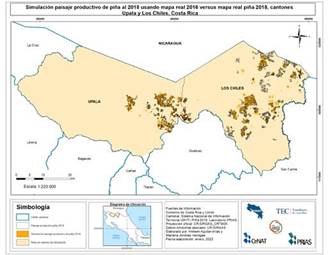
Fuente: Elaboración propia
Figura 2 Paisaje productivo de piña simulado al año 2018 a partir del mapa 2016 y comparación con mapa real 2018 en los cantones de Los Chiles y Upala, Alajuela, Costa Rica
Simulación de la cobertura de piña
El mapa de la cobertura de piña para el año 2028 se muestra en la Figura 4. Él área cultivada con piña para el 2028 es de 6 096,52 ha para Upala y 10 568,78 ha para Los Chiles. Esto representó un incremento de 2 487,38 ha en Upala y 2 098,13 ha en Los Chiles. Se refleja un incremento hacia los centros de poblado, donde la combinación de la cercanía a plantas empacadoras, acceso mediante vías nacionales y condiciones del suelo fueron aptas para la expansión del cultivo, principalmente en la zona de Los Chiles. Por su parte, Upala reporta los mayores pronósticos de aumento en área de cultivo, lo que permite inferir que la combinación de todas las variables impulsoras del cambio favoreció dicho aumento, principalmente por la cercanía de las plantas empacadoras.
La zona norte del cantón de Los Chiles proyecta una reducción de sus áreas, lo que concuerda con la información recolectada durante la aplicación de entrevistas, donde se identificó que, actualmente productores de la zona están en proceso de devolver fincas alquiladas y vender terrenos propios. Se debe considerar que hubo muestra no estudiada en la zona, lo que disminuyó la influencia en las variables.
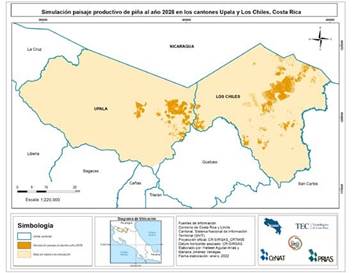
Fuente: Elaboración propia
Figura 4 Paisaje productivo de piña simulado al año 2028 en los cantones de Upala y Los Chiles, Alajuela, Costa Rica
En la Figura 5 se muestra visualmente la simulación obtenida para el año 2028 a partir del mapa 2016 en contraste con la cobertura real del paisaje productivo de piña, monitoreada para el año 2018 por el Laboratorio PRIAS.
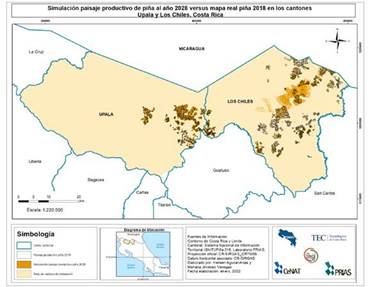
Fuente: Elaboración propia
Figura 5 Simulación de cobertura de piña al año 2028 (E) con respecto a la cobertura de piña real reportada en el 2018 (B) en los cantones Upala y Los Chiles, Alajuela, Costa Rica
Zonas de cambio en la cobertura arbórea y áreas silvestres protegidas
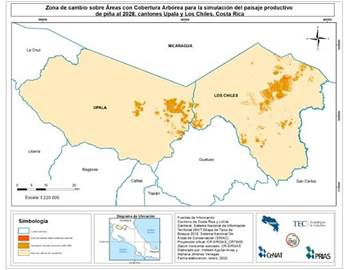
Por medio del análisis aplicado y las proyecciones obtenidas se identificó un aumento del paisaje productivo de piña para el año 2028, incremento que en algunos casos se encuentra sobre áreas silvestres protegidas o con cobertura arbórea. Las Figura 6 y 7 muestran dichas zonas con cambio de cobertura.
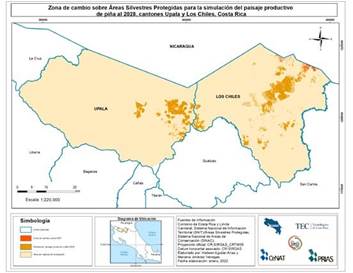
Fuente: Elaboración propia
Figura 6 Zonas de cambio en la cobertura sobre Áreas Silvestres Protegidas en el año 2028 en los cantones de Upala y los Chiles, Alajuela, Costa Rica
Discusión
Variables impulsoras del cambio en la cobertura de la piña
De acuerdo con Guevara et al. (2017), la demanda de piña mundial se satisface, principalmente, de Brasil, Costa Rica y Filipinas con una gran capacidad productiva. Esta fruta se posicionó entre los diez principales productos exportados desde Costa Rica hacia Europa desde el 2015 al 2018, según PROCOMER (2022). La Unión Europea, aunque no tiene una normativa específica para la piña, exige procesos como las certificaciones privadas que aseguran las buenas prácticas de producción, inocuidad y sostenibilidad (ONU). La MAG (2007) señala que la piña que no cumple los estándares de calidad de fruta fresca para exportación es rechazada por las plantas empacadoras, entonces se procesa para obtener concentrado, jugo, enlatados y congelados de piña.
Asimismo, la MAG (2010) menciona que las prácticas de manejo observadas durante las giras de campo para disminuir la humedad y la toxicidad-acidez del suelo, son características para los órdenes de suelo identificados y resultan condiciones favorables para el cultivo.
Ministerio de Agricultura y Ganadería (MAG); Servicio Fitosanitario del Estado y Servicio de Extensión Agropecuaria (2012) señala que los valores de precipitación y temperatura obtenidos se mantienen dentro de los valores ideales para la fruta. La precipitación debe ser entre los 500 mm hasta los 2 500 mm, mientras que la temperatura requerida oscila entre 15°C y 35°C. Abundantes lluvias reducen la exposición solar requerida por las plantas, indispensable para su desarrollo, según la MAG (2007); mientras que Vargas et al. (2018) apuntan que los cambios abruptos del clima están categorizados como alta afectación directa al cultivo y provocan una inestabilidad en la producción.
Ahora bien, Marla (2017) explica que la cercanía a carreteras principales, centros de poblado y proveedores de insumos influyen positivamente en los cambios de cobertura de los terrenos con usos más intensivos debido a que la cercanía a infraestructuras y mercados disminuye costos en transporte y aumenta la oportunidad de mercado.
Simulación
Espinoza (2016) señala que las tasas de transición explican la probabilidad de que cierta cantidad de píxeles pertenecientes a una clase cambien a otra; estos valores están calculados en proporción a la cantidad de píxeles totales por cada una de las clases. Las capas de coberturas utilizadas para simular fueron clasificadas en Piña y No Piña, lo que hace que la categoría No Piña contemple todas las demás coberturas de suelo y signifique una cantidad de píxeles mucho mayor a la de Piña específicamente, esto explica por qué a pesar de que exista un incremento en área de la clase piña, el porcentaje de transición de piña a no piña en las matrices es mayor.
Como se mencionó en métodos, para calcular los coeficientes de peso, DINAMICA los obtiene de una probabilidad condicional, en ese sentido, por ejemplo, la probabilidad de que una clase pase de No Piña (clase 2) a Piña (clase 1) es alta cuando se cumple que está cercano a plantas empacadoras. Caso contrario, la probabilidad de que una clase piña pase a no piña es mucho mayor cuando hay alta precipitación y la distancia a vías principales aumenta.
Aunque se demostró el supuesto de independencia de variables y no hubo la necesidad de eliminar ninguna variable, el modelo descartó la variable temperatura. El tipo de representación de datos (Int32) utilizado creó el mapa de esta variable con los valores de 26° y 27° C, así el modelo lo reconoce como una variable categórica y al ser un mapa con dos únicos valores en el espacio, tiene la misma influencia sobre todo el área.
El mapa simulado al año 2018 y generado a partir del insumo del 2017 mostró un coeficiente kappa de 0,857, lo que evidenció que es el modelo con mejor ajuste. No obstante, el coeficiente kappa del mapa simulado al año 2018, pero generado a partir del insumo del 2015 dio como resultado 0,437, lo que indicó que aún existe una similitud moderada entre los mapas y que además tiene un paso (año) más incluido, lo que permite modelar al año deseado con una menor cantidad de mapas simulados, razón por la que no se utilizó la simulación basada en el insumo del año 2017.
Zonas de cambio en la cobertura arbórea y áreas silvestres protegidas
Al analizar los resultados obtenidos producto del modelamiento de las zonas con cambio de cobertura, deben de tomarse tres consideraciones importantes: en primer lugar, las zonas con cambio analizadas comprenden áreas silvestres protegidas. Éstas zonas se amparan de leyes que controlan el uso de suelo n., especialmente en refugios nacionales de vida silvestre, por lo que la expansión de la cobertura de cualquier cultivo está limitada por estas legislaciones y el incumplimiento de las mismas puede provocar consecuencias legales según la Ley de La Biodiversidad 7788 (1998).
Por otra parte, la capa insumo de bosque maduro utilizada es cinco años inferior al presente estudio, lo que permite inferir que no refleja el estado más actualizado de la cobertura arbórea del país, de forma que pueden existir zonas que ya no están cubiertas por árboles, o, por el contrario, que haya un aumento en la cobertura.
Finalmente, tomando como base otros estudios que utilizan más categorías de coberturas en DINAMICA EGO, como los de Espinoza (2016), Leija, et al. (2016) y Argotty (2018), se sugiere evaluar, en un próximo, modelo la clase de cobertura arbórea y realizar un estudio de las variables que influyen en sus cambios, al igual que se hizo con la piña. El modelo nuevamente ejecutará los procesos, pero contemplando el peso que tengan las variables tanto en la cobertura de piña como en la cobertura arbórea.
Conclusiones
Las variables socioeconómicas y ambientales que influyeron de forma significativa en los cambios de cobertura del cultivo de piña del año 2015 al 2018 son: la demanda de la piña, condiciones del suelo y clima; procesados industriales, exportaciones hacia Europa y distancia a plantas empacadoras.
Las variables explicativas relacionadas con los cambios de uso resultaron ser independientes entre sí y permitieron el modelamiento de la cobertura futura del paisaje productivo de piña.
El modelo resultó ser moderadamente apto para simular la cobertura de piña en el futuro, el coeficiente kappa obtenido de la comparación de los mapas resultantes fue de 0,547.
A partir del mapa simulado al año 2028 se logra deducir que la cobertura de piña mantendrá un crecimiento, expandiéndose hacia los centros de poblados, donde se ubican principales plantas empacadoras y se cuenta con acceso por vías nacionales.
Upala es el cantón que proyecta un mayor incremento del área cultivada de piña con 2 487,06 ha más de las cultivadas actualmente.
Se identificaron zonas con cambio de cobertura arbórea a piña y en áreas silvestres protegidas. Se debe considerar para los tomadores de decisiones ya que el insumo de comparación es del año 2013, cinco años inferior al estudio. Los resultados arrojaron zonas de cambio en sitios que es prohibido por ley el cambio de uso del suelo.
Para evaluar el impacto en la cobertura arbórea se debe de hacer un modelo que involucre la clase y variables explicativas de esta cobertura