











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Los resultados de la evaluación a través de los test pueden tener consecuencias adversas en la vida cotidiana de las personas. Basta pensar en un contexto clínico en el que una persona puede recibir tratamiento de una institución de salud en base a los resultados de una prueba. Estas circunstancias comprometen a los científicos a realizar estudios que garanticen la equidad en la medición y la validez de las inferencias que se hacen a partir de las puntuaciones en los test (Borsboom, Romeijn & Wicherts, 2008). Es difícil defender un test que resulte sesgado contra un grupo en función de su sexo, etnia, cultura u otra característica sociodemográfica. El término sesgado, en este contexto, implica que las puntuaciones tienen distinto significado para miembros de diferentes grupos. Así, en su desarrollo, los test deben pasar por procesos de análisis del sesgo para evitar la discriminación a las minorías étnicas (afroamericanos, hispanos, asiáticos) o entre sexos, por poner un ejemplo (GonzálezBetanzos, 2011).
Una aproximación básica al estudio del sesgo es el estudio de la invarianza en la medida, la falta de invarianza se produce cuando el ítem (o el test) tiende a proporcionar puntuaciones distintas para personas que pertenecen a diferentes grupos y que, sin embargo, tienen el mismo nivel de rasgo (Shealy & Stout, 1993; Fidalgo, 1996). El término impacto se reserva para las diferencias reales entre los grupos (Camilli & Shepard, 1994).
En el presente trabajo esta propuesta teórica se aplica al problema psicométrico de análisis de la Escala de Detección del Trastorno de Ansiedad Generalizada -EDTAG (Carroll & Davidson, 2000). Este instrumento se ha propuesto como una prueba de cribado, una determinada puntuación en la EDTAG es uno de los criterios para determinar que la persona padece el trastorno, esta puntuación se ha determinado sin atender al sexo. Al mismo tiempo, se han encontrado puntuaciones mayores en las mujeres que en los hombres en dicho test. Por ello, el objetivo del presente trabajo es identificar si existe invarianza en la medida y/o si las diferencias entre hombres y mujeres son reales (i.e. existe impacto).
La EDTAG es un instrumento corto conformado por 12 ítems dicotómicos que detecta la presencia o ausencia de sintomatología del trastorno de ansiedad generalizado (TAG) según se observa en el DSM-IV. El instrumento se divide en 4 criterios: el criterio A que se refiere a la expectación aprensiva (ítems 1 y 2), el criterio B a la falta de control en la preocupación (ítems 1 y 2), el criterio C a los Síntomas fisiológicos (ítems del 5 al 10) y finalmente en el último criterio se recoge el aspecto temporal y su afectación en la vida cotidiana (ítems 11 y 12) que se relacionan con el criterio E.
La EDTAG fue adaptada al español por Bobes, García-Calvo, García-García y Rico-Villademoros (2006) en un estudio prospectivo multicéntrico, en una comparación entre pacientes y grupos sanos, la escala muestra una confiabilidad de 0.85, las pruebas señalan que una puntuación de 6 o más es indicativa de la presencia del TAG (sensibilidad = 84%, especificidad = 83%). Según estos autores se requiere en mínimo de una respuesta SI en los criterios A, B y E y tres respuestas afirmativas en el criterio C. En la aplicación se observó que las mujeres presentan puntuaciones significativamente mayores a los hombres, según los autores este hallazgo se corresponde con la prevalencia del trastorno en la población.
En el DSM-V (APA, 2013) se señala una prevalencia anual entre el 0.4 y el 3.6%, y una prevalencia a lo largo de la vida del 9% observándose el doble de casos en mujeres respecto a los hombres en los países que participan en la evaluación epidemiológica. En México, se ha estimado que el trastorno está presente alguna vez en la vida de la persona entre un 0.7%, y un 1,2% en los últimos 12 meses de la población general, observándose también una razón de 2 mujeres: 1 Hombre (MedinaMora et al., 2003).Asegurar la invarianza en la medida en la EDTAG tiene especial relevancia pues sus resultados están siendo utilizados como criterio de referencia para diagnóstico, el tratamiento, la evaluación de intervenciones, para estudios epidemiológicos y como medidas de observación para introducir y mejorar políticas sanitarias (AERA, APA, NCME, 1999). Por ello, en el presente trabajo realizaremos dos tipos de análisis, en el primero se utilizarán modelos de ecuaciones estructurales (MACS) y en el segundo se propone un análisis basado en los modelos de respuesta al ítem (TRI).
Método
Participantes
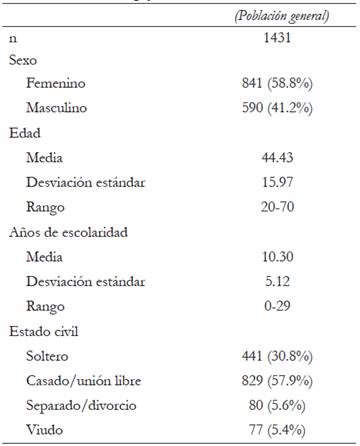
Participaron 1431 personas (véase características sociodemográficas en Tabla 1). La muestra estuvo formada por participantes de la población general, se buscó que la proporción entre rango de edades fuera similar. Los rangos de edad iban de 20 a 70 años con una media de 44.43 años y una desviación típica de 15.97.
Instrumentos
EDTAG: Escala de Detección del Trastorno de Ansiedad Generalizada deCarroll y Davidson (2000). Diseñada para detectar el trastorno de ansiedad generalizada consta de 12 ítems dicotómicos (“si” o “no” respecto a la presencia de criterios del DSM IV) que sirven para determinar la presencia o ausencia de sintomatología del TAG de acuerdo con el DMS-IV. En esta investigación se utilizó la adaptación en español de Bobes et al. (2006).
GADI (Generalized Anxiety Disorder Inventory, deArgyropoulos et al., 2007).Es un instrumento autoaplicado que consta de 18 ítems escala tipo Likert de 5 puntos (entre 0 “en absoluto” a 5 “el síntoma está presente en grado extremo”) útil para la evaluar la presencia o ausencia del trastorno por ansiedad generalizada así como su intensidad. La confiabilidad evaluada mediante el alfa fue de 0.948 para la subescala cognitiva, 0.84 para la subescala que evalúa los trastornos de sueño y 0.89 para la subescala de síntomas somáticos.
BAI (Beck Anxiety Inventory).Consta de 21 ítems que se contestan en una escala de 4 puntos (de 0 a 3). Se utilizó la versión mexicana adaptada por Robles, Varela, Jurado y Páez (2001). Presentó una consistencia interna con valores de alfa de Cronbach de .84 en estudiantes universitarios y de .83 en población general.
Procedimiento
En el presente estudio se aplicó la traducción española disponible Bobes et al. (2006) esta versión fue revisada por tres jueces con experiencia en el ámbito de la psicometría y con conocimientos sobre el trastorno de ansiedad generalizada, ninguno de los jueces consideró pertinente la modificación de los ítems. Los datos fueron recogidos en población general a través de la solicitud de participación anónima y voluntaria a transeúntes.
Metodologías para el análisis
La invarianza en la medida (IM) significa que las propiedades de medida del test o de los ítems de un test deberían ser independientes de las características de las personas, excepto por la característica específica que se está midiendo con el test. Formalmente se considera que la distribución de las puntuaciones observadas en las respuestas a un test debería depender únicamente del espacio de la dimensión latente que se evalúa (Mellenbergh, 1989; Meredith, 1993). A saber,

Según la ecuación 1 los valores de las variables observables (que son las respuestas a los ítems) deben depender únicamente de los valores de las variables latentes (también llamados factores o dimensiones), lo que significaría que existe una independencia entre X y g. Para estudiar la IM es necesario especificar una relación funcional entre las variables observables y la dimensión que representan, dicha relación puede ser lineal o no-lineal. El primer caso corresponde al análisis factorial confirmatorio definido a partir de los modelos de ecuaciones estructurales de medias y covarianzas (AFC-MACS), el segundo se relaciona con los modelos de teoría de la respuesta al ítem (TRI, Elosua, 2005).
El Análisis Factorial Confirmatorio (AFC) para datos categóricos y la Invarianza.
El Modelo de AFC es un modelo de regresión lineal en el cual un número de variables observadas, las respuestas a los ítems, se explica a partir de un número de variables latentes subyacentes llamadas factores. El modelo lineal parte de la ecuación que define la puntuación observada (o vector de puntuaciones - X, a través de un modelo de regresión en el que la variable independiente se define como:

ԑEs el vector de residuos n-dimensionales de la regresión de X sobre η
Este modelo asume que las variables observadas son continuas y tienen una distribución normal, la existencia de una relación lineal entre variables observadas y latentes, que los residuos se distribuyen de manera normal, que son independientes entre ellos y que son independientes de las variables latentes (Jöreskog, 1971).
Sin embargo, se sabe que la mayoría de las medidas obtenidas en los ítems que componen las escalas o los cuestionarios en la investigación en las ciencias sociales no dan como resultado valores continuos en escala de razón, sino más bien valores discretos, en el caso de la EDTAG la variable observada es dicotómica.
Si se trata a estas variables como variables continuas en el AFC se viola el supuesto de normalidad multivariada y, en el contexto del análisis multigrupo, se podría distorsionar la estructura factorial de los diferentes grupos, haciendo problemática la investigación sobre equivalencia (Lubke & Muthén, 2004). Para evitar este problema, Millsap y Yun-Tein (2004) han propuesto recientemente el empleo de un modelo de factor común multigrupo para medidas categóricas. Los autores señalan que éste modelo ha recibido poca atención en la investigación de la invarianza.
La definición de invarianza propuesta por Mellenbergh (1989) se aplica también al modelo para variables categóricas, en el caso de los modelos unidimensionales (unifactoriales), y para una adecuada comparación con modelos de TRI, se realizan contrastes estadísticos sobre la igualdad de pesos factoriales (invarianza métrica) e interceptos (invarianza escalar) a través de los grupos. Pero se añade una restricción sobre los umbrales latentes que hacen que la variable latente continua se torne discreta en las respuestas observadas.
En nuestro caso para la comparación por sexo, llamaremos grupo de referencia a las mujeres y grupo focal a los hombres. En el análisis se especifica primero un modelo de línea base compacto donde, en cada caso, los pesos y los interceptos se restringen a ser iguales en los dos grupos (se iguala λ r = λ f y τ r =τ f donde r = grupo de referencia y f = grupo focal, ver ecuación 3). El siguiente paso se especifica un modelo aumentado en el que se liberan los parámetros del ítem que se prueba para saber si es invariante (ver ecuación 4).
i)Modelo compacto -modelo de línea base
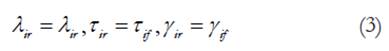
ii)Modelo aumentado
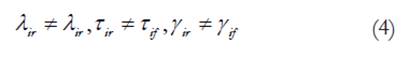
Donde i es el ítem que se prueba para invarianza
Donde γ ig es el umbral de la variable latente en el ítem i para el grupo g (ya sea r = referencia o f = focal).Una vez que se han estimado tanto el modelo compacto como el modelo aumentado se obtiene el estadístico de bondad de ajuste Chi-cuadrado, debido a que el modelo compacto está anidado en el aumentado, se puede comparar el cambio en el Chi-cuadrado con grados de libertad igual a la diferencia de los grados de libertad de los modelos respectivos. En cada comparación un resultado significativo es evidencia de que se viola la equivalencia entre los parámetros y que por lo tanto no hay Invarianza en la medida, a esta prueba se le conoce como Razón de verosimilitudes.
La Teoría de la Respuesta al Ítem (TRI) y la Invarianza.
Tanto los modelos de AFC como los de TRI relacionan la respuesta en un ítem con el nivel de rasgo de un examinado. Sin embargo, mientras que los primeros representan una relación lineal, en la TRI el modelo de respuesta al ítem es una función matemática logística, denominada curva característica del ítem (CCI). En esta función se incluyen dos tipos de parámetros, el de los sujetos y los de los ítems. El parámetro de los sujetos se denomina nivel del rasgo (θ). Los parámetros de los ítems dependen del modelo. En el caso del modelo logístico de 2 parámetros (2PL) los parámetros para los ítems son el parámetro de discriminación (a) que representa la pendiente de la función y el parámetro de dificultad (b), que indica el valor de θ correspondiente al punto de máxima pendiente de la CCI. El Modelo 2PL se escribe como:
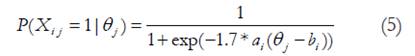
DondeP X( X i j 1|θ j )significa que la probabilidad de responder 1= Si (X i j = 1) a un ítem en el EDTAG depende del nivel del rasgo que se evalúa, en nuestro caso es el Trastorno de ansiedad generalizado, esta probabilidad se explica mediante una función logística con dos parámetros y el nivel de rasgo de la persona.
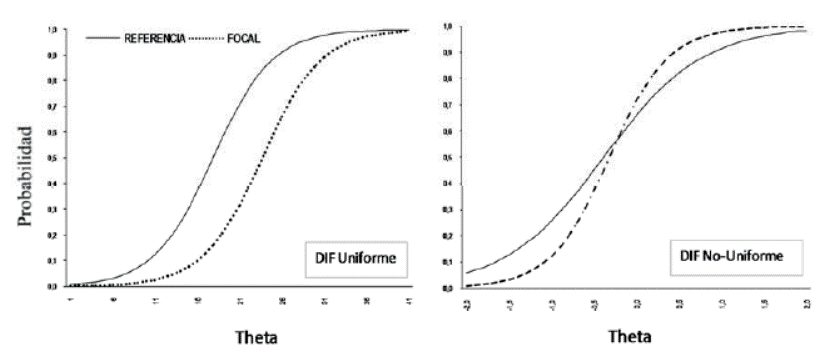
En el marco de la TRI se llama Funcionamiento Diferencial del Ítem (DIF) a la Invarianza en la medida (IM) y dice que existe DIF cuando las curvas características de los ítems (CCI) son diferentes para los grupos focal y de referencia; es decir cuando para el mismo nivel de rasgo los grupos no tienen la misma probabilidad de elegir la opción de un ítem.
Existen dos tipos básicos de DIF, el DIF uniforme y el DIF no-uniforme. En el primero, uno de los grupos, casi siempre el de referencia, tiene mayor probabilidad de dar una respuesta en todos los niveles del rasgo (ver figura 1 -izquierda) mientras que en el DIF nouniforme la probabilidad de emitir una respuesta es mayor en el grupo de referencia en algunos niveles del rasgo, mientras que en otros niveles la probabilidad es mayor para el grupo focal (ver figura 1-derecha) (Finch & French, 2007; Martínez-Arias, Hernández-Lloreda & Hernández-Lloreda, 2006).
Por lo tanto, se considera que existe invarianza (o que no existe DIF) si los parámetros del ítem permanecen invariantes a través de los grupos. Existen diversos procedimientos basados en TRI para detectar DIF: chi-cuadrado, la medida del área, la prueba de razón de verosimilitud (LR). Entre ellas, esta última se considera la más general. En esta prueba, descrita por Thissen, Steinberg y Wainer (1993), se compara el ajuste de los modelos anidados, estimados mediante procedimientos de máxima verosimilitud marginal. Este procedimiento es muy similar al que se emplea en MACS. Para ello se ajusta un modelo en el que se asume la igualdad de los parámetros estimados a través de los grupos de referencia y focal (modelo compacto); posteriormente, este modelo se compara con un modelo donde los parámetros del ítem estudiado se liberan (modelo aumentado),
i)Modelo compacto

ii)Modelo aumentado
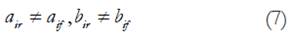
donde i es el ítem que se prueba para DIF
y se aplica la prueba de razón de verosimilitud (LR) que se define como:

Donde Lc= probabilidad de los datos según los parámetros del modelo compacto y LA = probabilidad de los datos según los parámetros del modelo aumentado. La transformación del logaritmo natural de esta función se toma como una prueba estadística distribuida como X2 bajo la hipótesis nula:
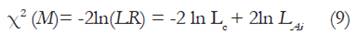
Para la Ecuación 9, M es el número de grados de libertad y es igual a la diferencia en el número de parámetros estimados en el modelo compacto respecto del modelo aumentado por lo que, en caso de un modelo de dicotómico de dos parámetros, dado que se liberan los parámetros ai y bi , el estadístico sigue una distribución chi-cuadrado con 2 grados de libertad. Si el contraste toma un valor estadísticamente significativo, esto indica que el modelo compacto se ajusta peor que el modelo aumentado.
Para usar la prueba de LR, un valor de chicuadrado se calcula para cada ítem en el test. Aquellos ítems con valor significativo de c2 se dice que presentan DIF. En la tradición de TRI, si esto ocurre, se calculan dos test adicionales. En el primero se permite variar el parámetro de discriminación y, posteriormente, se hace una prueba sobre el parámetro de dificultad, por lo que se puede saber si existe DIF uniforme o no uniforme.
Tanto el modelo lineal AFC-MACS como el modelo no lineal de TRI se utilizarán para analizar la IM de los datos del EDTAG. En el primer caso se utiliza el programa MPLUS 7.0 (Muthen & Muthen, 2012) que permite trabajar con variables categóricas y en el segundo caso el análisis se hace con el programa llamado IRTLRDIF v. 2 de Thissen (2001).
Para evaluar el ajuste (Akaike, 1974) de los modelos se utilizará el valor de Chi-cuadrado (c2 ), así como la información de otros indicadores de bondad de ajuste (Bollen y Long, 1993, Elosua, 2005). Entre ellos se utiliza el índice de ajuste general (GFI; Jöreskog & Sorbom, 1993), la raíz media cuadrática del error de aproximación (RMSEA; Hu & Bentler, 1999), el criterio de información de Akaike (AIC; Akaike, 1974) y el índice de ajuste comparativo (CFI; Bentler, 1990). Además se utiizará el criterio de Cheung y Resnvold (2002), para ello se observará la diferencia entre los valores del índice comparativo de Bentler (CFI); si el valor de la diferencia entre dos modelos anidados es superior a .01 en favor del modelo con menos restricciones, deberá rechazarse el modelo con más restricciones.
Resultados
Las medias aritméticas y las desviaciones típicas obtenidas con la versión original de la EDTAG son 4.66 (DT= 3.55) para las mujeres y 4.01 (DT= 3.37) para los hombres. La diferencia de medias entre ambas muestras es estadísticamente significativa [t = 2.80, p < .05]. El coeficiente alfa de Cronbach es de .85.
Invarianza factorial con AFC-MACS
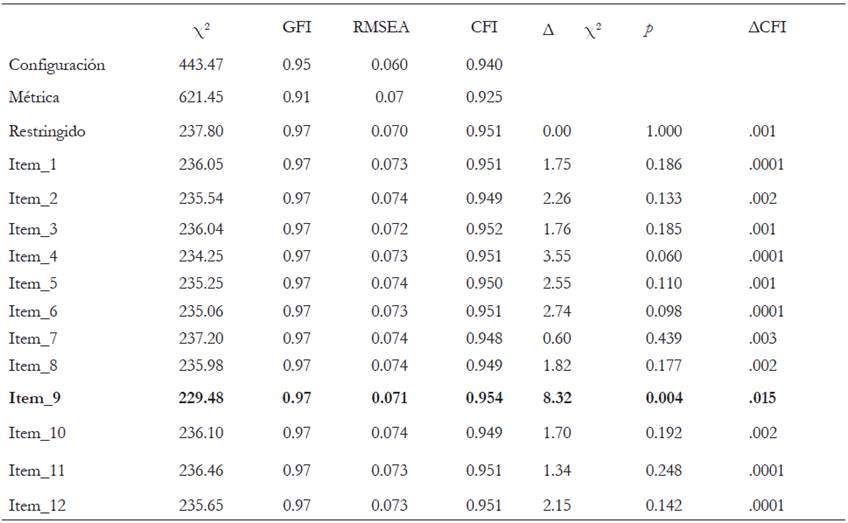
La invarianza factorial con AFC-MACS requiere una seria de pasos que inician con la determinación del modelo de línea base que se establece para cada grupo de manera separada. Este modelo representa el mejor ajuste a los datos dado que no se impone ninguna restricción en la estimación de los parámetros. La estimación progresiva de la invarianza comienza con el modelo de invarianza configural (Tabla 2). Los índices de ajuste obtenidos (Tabla 3) permiten aceptar la equivalencia de la configuración entre hombres y mujeres aunque el valor de Chi-cuadrado excede el criterio para aceptar la hipótesis de invarianza, el resto de los índices contradicen dicha conclusión. El índice de ajuste (GFI = .95) y la raíz media cuadrática (RMSEA = .06) nos permiten aceptar que ambos grupos comparten la misma configuración.
Cuando añadimos las restricciones sobre los pesos factoriales se prueba el modelo de invarianza métrica. Los valores de la Tabla 3 señalan una pérdida significativa en el ajuste del modelo. El índice de ajuste general (GFI = .1) y la raíz media cuadrática (RMSEA = .074). Si hacemos uso del criterio anidado, la diferencia entre CFI´s entre el modelo de configuración y el de invarianza métrica (ΔCFI = .018) nos conduce a señalar una posible falta de invarianza métrica entre los grupos.
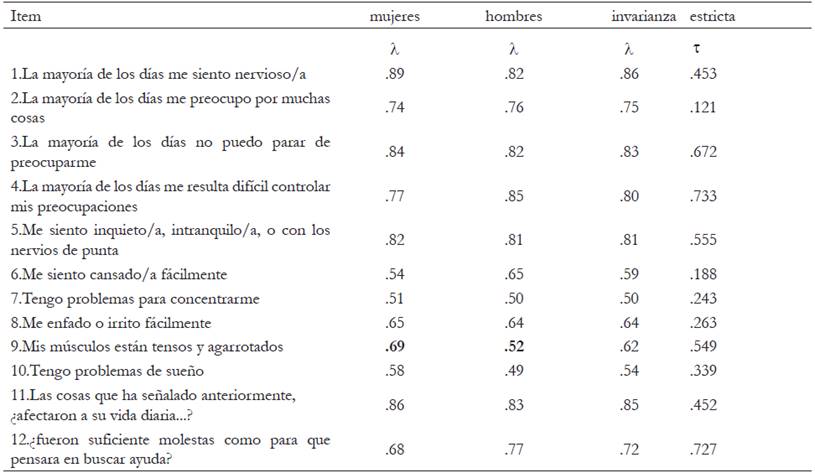
Para evaluar el (los) pesos específicos que podrían causar una falta en la invarianza métrica se compara el modelo compacto y se van liberando uno a uno los pesos factoriales de los ítems, en la Tabla 3 se muestran los resultados para la comparación. En negritas (ver Tablas 2 y Tabla 3) se muestra el único ítem en el que se encuentra un ajuste significativamente mejor entre el modelo en el que se estiman los pesos para cada grupo respecto del modelo en el que los pesos son los mismos para hombres y mujeres (Δc2 = 8.32 y un incremento en CFI = .015).
Tabla 2 Estructura factorial de la Escala de Detección del Trastorno de Ansiedad Generalizado (EDTAG) , pesos factoriales para las mujeres, hombres y el modelo invariante
Invarianza factorial con modelos de TRI
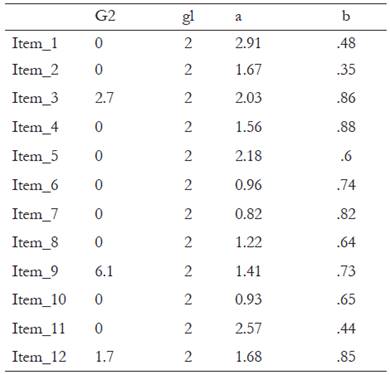
La Tabla 4 presenta los resultados del análisis FDI con el método LR-DIF (loglikelihood -Differential Item Functioning, o prueba de Razón de similitudes para el funcionamiento diferencial del Ítem). Se presenta el estadístico G2 que se distribuye como Chi-cuadrado con grados de libertad igual al número de parámetros que se restringen en el modelo. Dado que trabajamos con un modelo de dos parámetros los grados de libertad son 2. Un valor de G2 de 3.84 es indicativo de que el ítem no es invariante.
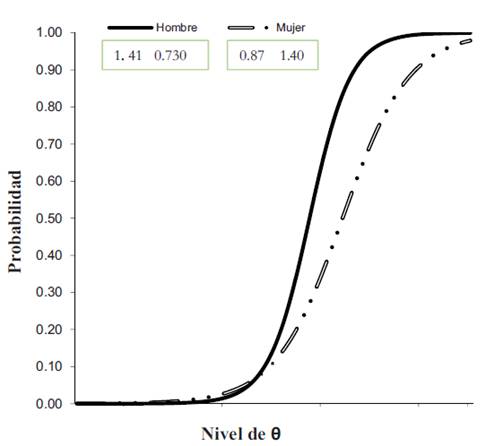
En el análisis el ítem 9 tiene un valor de G2 = 6.1 lo que significa que este ítem presenta funcionamiento diferencial. En la figura 2 se presentan los valores de los parámetros para cada grupo, como puede observarse, en el ítem 9 los hombres tienen mayor probabilidad de responder que “Tienen los músculos agarrotados” que las mujeres, aun cuando tengan el mismo nivel de ansiedad. (Figura 2.)
En los resultados tanto el análisis con los modelos de ecuaciones estructurales para el análisis factorial confirmatorio con modelos de medias y covarianzas (AFC-MACS) como con los análisis de la Teoría de la Respuesta al Ítem (TRI) coinciden en señalar que el ítem 9 no es invariante entre los grupos. Mientras que en la puntuación observada la diferencia entre las medias es de 0.66 en el análisis con la variable latente la diferencia de medias es de 0.28 mayor para las mujeres que para los hombres.
Discusión
El objetivo del presente estudio fue realizar un análisis de invarianza entre hombres y mujeres en la Escala de Detección del Trastorno de Ansiedad Generalizado (EDTAG) partiendo de dos tipos de relaciones funcionales entre el espacio latente y las variables observadas: i) Un modelo lineal y un modelo logarítmico.
En el modelo lineal se ha mostrado la evaluación progresiva de la invarianza estableciendo primero que en ambos sexos el test se comporta de manera unidimensional, es decir todos los ítems representan la medida del Trastorno de Ansiedad Generalizado (TAG) como variable latente (invarianza configural). Sin embargo, el análisis señala que no existe invarianza métrica en la medida a nivel global, para conocer específicamente en donde se produce la falta de equivalencia se llevaron a cabo análisis por ítem en el que se probó la equivalencia en los parámetros del modelo: i.e. los pesos factoriales y los umbrales, mediante un procedimiento que descubre la falta de ajuste en modelos anidados denominada prueba de Razón de verosimilitudes. Este análisis mostró que el ítem 9 no representa a la variable latente de igual forma en ambos grupos.
Como señalan diversos autores, el estudio de la invarianza desde la perspectiva lineal se acerca a la evaluación del funcionamiento diferencial del ítem que describe la relación de manera logística entre los ítems y las dimensiones latentes del rasgo.
Estos análisis han sido diseñados para su uso en escalas unidimensionales. El presente estudio pone en evidencia la necesidad de realizar análisis de invarianza en las escalas de medición, especialmente en aquellas escalas cortas donde una diferencia de un punto podría significar un falso positivo.
Sin embargo, estos resultados no proveen respuestas por si solos, se sabe que un segundo paso en el análisis, se relaciona con la revisión e interpretación de contenidos que permitan conocer porque existe un comportamiento diferencial entre hombres y mujeres en estos ítems. Además es importante tener en cuenta a las variables que pueden estar influyendo y para ello es necesario profundizar en el estudio sobre sesgo en el marco de la validez de constructo.
El presente estudio demuestra que en el EDTAG el ítem 9 que señala “Mis músculos están tensos y agarrotados” se comporta distinto para hombres que tiene mayor probabilidad de responder afirmativamente, esto puede indicar que la sintomatología en hombres y en mujeres es diferente en los procesos ansiosos.

