









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La medición psicoeducativa cumple un rol fundamental en la actualidad en el campo de las ciencias sociales y de la salud, en las cuales se suele conceptualizar como la asignación sistemática de números a personas como una forma de representar características psicológicas, tales como inteligencia, personalidad, motivación, aptitud, actitudes, calidad de vida, entre otros (Raykov & Marcoulides, 2011). A diferencia de muchos atributos físicos (peso, edad, estatura, color de piel, etc.), las variables de interés en estos campos del saber no pueden ser observadas directamente por lo que instrumentos para cuantificar este tipo de variables se consideran como indicadores indirectos de una o varias variables no observadas (constructos o variables latentes).
Un constructo o variable latente es una fuente oculta de varianza (o de covarianza) en un conjunto de puntuaciones observadas, las cuales se obtienen a partir de la aplicación de un test a un conjunto de personas (estudiantes, pacientes, aspirantes a ingreso a una institución, etc.). En este sentido, un test es un dispositivo evaluativo o procedimiento mediante el cual se obtiene una muestra de la conducta de los examinados en un dominio especificado, el cual es posteriormente evaluado y calificado mediante un proceso estandarizado (AERA, APA & NCME, 2014). De esta manera, los puntajes derivados de la aplicación de un test son indicadores de un constructo, el cual se considera como la causa principal de su variabilidad (Borsboom, Mellenbergh & Heerden, 2004).
Para medir este tipo de variables, es necesario acudir a técnicas especializadas que permitan cuantificar el nivel de las personas en un determinado constructo o la pertenencia de estas a diferentes clases latentes. Para ello, la psicometría se ha consolidado como una disciplina científica que estudia los problemas inherentes a la medición de variables latentes y que provee de modelos para abordarlos. Ahora bien, uno de los pasos cruciales en este proceso es establecer si la variable latente por medir (ansiedad, depresión, conocimientos, etc.) es categórica, continua o una combinación de ambas (De Ayala, 2009). En el caso de que sea categórica, los sujetos serán clasificados en grupos cualitativamente diferentes denominados clases latentes. Por otra parte, si el constructo de interés se considera una variable continua, entonces cada persona presentará un determinado nivel en un continuo. Una tercera posibilidad es que el espacio latente se considere una combinación entre variables categóricas y continuas, de modo que cada persona sería asignada a una clase latente y además presentará un nivel en el constructo; en este último escenario es necesario acudir a los modelos de mezcla.
Por otra parte, las poblaciones de interés en las ciencias sociales y de la salud suelen ser muy heterogéneas y es frecuente que las fuentes de dicha heterogeneidad no sean conocidas a priori (Lubke & Muthen, 2005). Por ejemplo, los examinados pueden utilizar diferentes estrategias cuando contestan ítems pertenecientes a un test, de modo que algunas de ellas serán apropiadas para resolver los ítems y otras no (Von Davier, 2010). Así las cosas, en principio es posible observar que en una misma muestra los examinados conformen distintas subagrupaciones en función de las estrategias utilizadas para contestar los ítems. Ante esta situación, sería conveniente emplear un modelo de mezcla para analizar las respuestas a los ítems, por cuanto es plausible suponer que los parámetros de los ítems y de los examinados son distintos en cada una de las posibles subagrupaciones no observadas que componen la población en estudio (Vermunt, 2014).
Cuando las fuentes de heterogeneidad son conocidas (sexo, edad, zona de residencia, etc.) se pueden utilizar modelos multigrupo como el análisis del funcionamiento diferencial del ítem para comparar los parámetros estimados en los grupos conformados a partir de las fuentes de variabilidad irrelevante al constructo que se pretende medir (Raykov, Marcoulides, Lee & Chang, 2013). No obstante, los grupos podrían conformarse a partir de variables no observadas, por lo cual la pertenencia de los examinados a las posibles subagrupaciones únicamente puede ser inferida a partir de los datos. Los modelos en los que se asume que la fuente de heterogeneidad no es observable están diseñados para detectar conglomerados de sujetos con patrones de respuesta similares en un conjunto observado de variables, como por ejemplo las respuestas a un test. De hecho, el uso de los modelos de mezcla de la Teoría de respuesta al ítem ha resultado ser de gran utilidad para complementar los análisis del funcionamiento diferencial de los ítems (DeMars & Lau, 2011; Lee & Beretvas, 2014).
Cabe señalar que la mayoría (si no es que todos) de los modelos de mezcla para analizar datos provenientes de la aplicación de test pueden ser vistos como extensiones del modelo básico utilizado en el análisis de clases latentes, el cual es un modelo de mezcla debido a que para estimar la probabilidad de observar un determinado vector de respuestas a un conjunto de ítems es necesario multiplicar entre sí las probabilidades de respuesta correcta en cada clase latente y posteriormente sumar dichos productos. Por ejemplo, si se contara con 10 ítems dicotómicos en principio podrían observarse 1024 patrones de respuesta diferentes y sería posible agrupar a los examinados de acuerdo con estos de tal manera que quienes presenten patrones similares pertenezcan a un mismo grupo.
En el contexto del análisis de clases latentes es posible agrupar dichos patrones de respuesta (y, por ende, a los sujetos que muestran dichos patrones) en un número reducido de k clases latentes (k< 1024) de modo que los patrones de respuesta para los examinados pertenecientes a una misma clase son más similares entre sí que con respecto a los patrones de quienes pertenezcan a otra clase latente.
Un supuesto fundamental en el análisis tradicional de clases latentes es el de la independencia local, el cual se refiere a que las variables observadas no covarían entre sí a lo interno de cada clase. De este modo, asumiendo la independencia local de los ítems a lo interno de las clases latentes, la probabilidad condicional de un determinado patrón de respuestas es igual al producto de las probabilidades individuales de respuesta de ese patrón (Collins & Lanza, 2010).
Los modelos de mezcla de la Teoría de respuesta al ítem son aquellos que permiten no solo estimar la pertenencia de los examinados a alguna de las posibles clases latentes, sino también su nivel en el constructo que se pretende medir. Dado que estos modelos incorporan variables latentes continuas y categóricas, son especialmente útiles para analizar datos generados a partir de la medición de un constructo continuo en una muestra compuesta por dos o más subagrupaciones no observadas. En este sentido, son modelos de clases latentes en los que las probabilidades de observar una determinada respuesta en una clase latente se modelan de acuerdo con alguno de los modelos tradicionales de Teoría de respuesta al ítem (Formann & Kohlmann, 2002).
Lo anterior implica que en estos modelos se flexibiliza el supuesto de independencia local entre los ítems a lo interno de cada clase, para lo cual se plantea la existencia de una o varias variables latentes continuas que explican las dependencias entre los ítems en cada una de las clases (Sterba, 2013). A diferencia del análisis tradicional de clases latentes, esto permite plantear la existencia de diferencias individuales sistemáticas entre los individuos que pertenezcan a una misma clase latente.
En el modelo de la Teoría de respuesta al ítem de tres parámetros para ítems dicotómicos (Hambleton, Swaminathan & Rogers, 1991) se plantea que la probabilidad de contestar correctamente un ítem (o de elegir la opción codificada con el mayor valor) depende de su dificultad (b), de su discriminación (a) y del azar (c), así como del nivel en el constructo del examinado (θ):
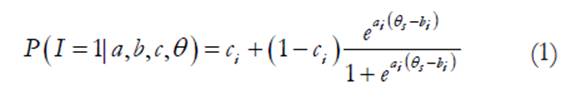
Cuando este modelo se combina con el análisis de clases latentes, entonces es posible estimar la probabilidad de elegir la opción de mayor valor para cada una de las g clases latentes así como la proporción de examinados que pertenecen a cada clase (π g ), a saber:
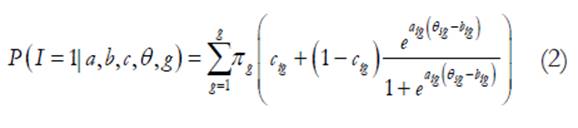
En los modelos de mezcla de la Teoría de respuesta al ítem tanto la distribución de la habilidad como las probabilidades de respuesta dependen de la pertenencia a una determinada clase latente. Dado que se asume la existencia de dos o más clases a las que podrían pertenecer los examinados, el número de estas debe ser inferido utilizando estrategias que implican la clasificación de los patrones de respuesta observados (Von Davier & Yamamoto, 2007). Así pues, estos modelos asumen una estructura más compleja a lo interno de cada clase en comparación con el análisis de clases latentes. Específicamente, además de incluir una variable latente categórica de clasificación también incluyen una continua para modelar el nivel en el constructo de los examinados.
Cabe señalar que, como se puede observar en la Fórmula 2, el modelo utiliza una transformación logito como función de enlace al modelo, por lo cual se asume que la distribución de probabilidad condicional de la respuesta al ítem es binomial (Bernoulli). Además, para que el modelo sea estimable el resultado de sumar los π g de cada clase latente debe ser igual a 1 y la suma de los b ig en cada clase debe ser igual a 0 (Rost, 1990).
Los parámetros de los ítems y los de las personas podrían ser diferentes en cada clase. Por lo tanto, estos modelos se utilizan cuando se sospecha que cada examinado podría pertenecer a una de varias posibles clases exhaustivas y mutuamente excluyentes que corresponden a las posibles estrategias para contestar los ítems (Mislevy & Verhelst, 1990). Dada su gran flexibilidad, han sido estudiados para conocer sus fortalezas, debilidades y aplicaciones.
Desde una perspectiva teórico-metodológica, ha habido un gran interés por investigar aspectos relacionados con los métodos de estimación de los parámetros, la consistencia en la asignación de los examinados a las clases latentes, los índices de ajuste utilizados para seleccionar los modelos, la comparabilidad de los parámetros estimados en cada clase y la utilidad de incluir covariables como parte de la caracterización de los examinados en las clases latentes (Li, Cohen, Kim & Cho, 2009; Muthen & Lubke, 2007; Nylund, Asparouhov & Muthen, 2007; Paek & Cho, 2015; Preinerstorfer & Formann, 2011; Smit, Kelderman & van der Flier, 2000; Smit, Kelderman & van der Flier, 1999; Tueller y Lubke, 2010; Von Davier & Molenaar, 2003; Willse, 2011). En esta línea de investigación, recientemente se ha comenzado a explorar la sensibilidad de estos modelos en la detección de clases latentes espúreas (Alexeev, Templin & Cohen, 2011; Chen & Jiao, 2013), la utilidad de incorporar estructuras multinivel en los análisis (Cho & Cohen, 2010), la estimación mediante métodos bayesianos y la inclusión de covariables observadas (Dai, 2013).
Finalmente, a la fecha se han explorado una gran diversidad de aplicaciones de estos modelos, como la generación de evidencias de validez referidas a la invarianza de los parámetros de los ítems (Baghaei & Carstensen, 2013) y a la dimensionalidad de los test (Hong & Min, 2007), la identificación de posibles fuentes del funcionamiento diferencial de los ítems (Choi, Alexeev & Cohen, 2014; Cohen & Bolt, 2005; DeMars & Lau, 2011; Elosúa & López, 2006; Frick, Strobl & Zeileis, en prensa; Meij, Kelderman & Flier, 2010; Oliveri, Ercikan, Zumbo & Lawless, 2014; Tay, Newman & Vermunt, 2011), el estudio de las diferencias individuales relacionadas con la tendencia a elegir ciertas opciones de respuestas (Bolt, Cohen & Wollack, 2001; Carter, Dalal, Lake, Lin & Zickar, 2011; Egberink, Meijer & Veldkamp, 2010; Eid & Rauber, 2000; Meij, Kelderman & Flier, 2008; Meiser & Machunsky, 2008; Mneimneh, Heeringa, Tourangeau & Elliott, 2014), la identificación de la existencia de tipos diferentes de examinados que utilizan estrategias distintas de razonamiento (De Boeck & Rijmen, 2003; Embretson, 2007), la identificación de subagrupaciones de examinados en función de la velocidad de estos para contestar los ítems ubicados al final de un test (Bolt, Cohen & Wollack, 2002; Meyer, 2010), la detección de examinados con bajos niveles de motivación para contestar test de bajas consecuencias (Mittelhaëuser, Béguin & Sijtsma, 2013), la detección de diferentes estilos de respuesta respecto de la expresión de la ira (Gollwitzer, Eid & Jürgensen, 2005), la identificación de subpoblaciones de adolescentes que incurren en el consumo de drogas y conductas sexualmente riesgosas, así como también la selección de los ítems de mayor utilidad para distinguir a dichas subpoblaciones (Holmes & Pierson, 2011), la identificación de diferentes clases asociadas al autoreporte de la adicción al tabaco (Muthen & Asparouhov, 2006), el estudio de las diferencias en cuanto a la interpretación de los ítems incluidos en los cuestionarios utilizados por los pacientes para reportar diferentes aspectos de su estado de salud (Sawatzky, Ratner, Kopec & Zumbo, 2012; Schmiege, Meek, Bryan & Petersen, 2012), la detección de examinados que dan autoreportes falsos en inventarios de personalidad (Holden & Book, 2009; Zickar, Gibby & Robie, 2004) y la validación de puntos de corte asociados a estándares de desempeño en pruebas estandarizadas (Jiao, Lissitz, Macready, Wang & Liang, 2011).
Así pues, el objetivo del presente artículo es ilustrar la utilidad de los modelos de mezcla de la Teoría de respuesta al ítem para detectar agrupaciones de examinados no observadas. Con ello, se pretende evidenciar la utilidad del modelo para la medición en el campo de las ciencias sociales y de la salud.
Método
Participantes
La muestra de examinados incluidos en el análisis corresponde a 2827 costarricenses cuyas edades oscilan entre los 60 y los 100 años, los cuales participaron en el estudio denominado Costa Rica Estudio de Longevidad y Envejecimiento Saludable (Rosero, Fernández & Dow, 2005):
In the first stage of the design model, a random selection was made from the database of the Census of Population of the 2000, totaling 9,600 individuals 55 years of age of older, after a stratification by five-year age groups that assures a sufficiently large number of observations for advanced ages. The sampling fraction in this selection varies between 1% for the ones born in 1941-1945 and 100% for the born ones before 1905. For the detailed longitudinal follow-up, including the survey to which the present report refers, a sub-sampling was selected consisting of 60 “Areas of Health” (from a total of 102 in the whole country) aggregated into subregions. The sample covers 59% of the national territory (p. 2).
En relación con el consentimiento de los sujetos para participar en el estudio, Rosero, Fernández y Dow (2005, p. 4) afirman lo siguiente: “In the first visit, the participants granted their informed consent (Appendix 1) by means of their signature”.
Instrumento
Como parte del estudio se aplicó una versión reducida de 15 ítems de la Escala de depresión geriátrica (Yesavage, Brink, Rose, Lum, Huang, Adey & Leirer, 1983), cuyas opciones de respuesta son 1 (“Sí”) y 2 (“No”). La calidad técnica de dicho instrumento ha sido evaluada en una gran cantidad de estudios (Friedman, Heisel y Delavan, 2005; Brown & Schinka, 2005;
Jongenelis, Pot, Eisses, Gerritsen, Derksen, Beekman & Ribbe, 2005) para medir el nivel de depresión en la población de adultos mayores.
Mediante este instrumento se midió el nivel de depresión de los examinados mediante preguntas como “¿Sintió que su vida está vacía?”, “¿Estuvo preocupado o temiendo que algo malo le pasara?”, entre otras. De este modo, quienes tienden a elegir la segunda opción de respuesta muestran menores niveles de depresión. Para interpretar las opciones de respuesta de la misma manera en todo el instrumento, se recodificaron los ítems 1, 5, 7, 11 y 13.
Procedimiento y análisis de datos
Los datos fueron descargados del sitio web mencionado en el apartado de participantes. Además, se eliminó de la muestra a todos los sujetos con datos faltantes en alguno de los 15 ítems, por lo que los análisis se realizaron con 1563 personas. Cabe señalar que para el objetivo del presente artículo, cual es el de ilustrar los posibles usos de un modelo psicométrico y no el de generalizar conclusiones hacia la población, no representa problema alguno la estrategia de eliminar examinados de la muestra.
En primer lugar se realizaron análisis descriptivos para identificar la posible presencia de errores en la digitación de las respuestas. Posteriormente, se realizó un análisis factorial confirmatorio para recabar evidencias sobre la estructura interna de la escala. Finalmente, se analizaron los patrones de respuesta a los ítems mediante el modelo de mezcla de la Teoría de respuesta al ítem. Todos los análisis se ejecutaron con el programa MPLUS (Versión 7.3).
Resultados
En la Tabla 1 se muestra para cada ítem el porcentaje de personas que eligió la categoría “No”, su correlación con la puntuación total (índice de discriminación), las cargas factoriales (con sus respectivos errores estándar) estimadas mediante un modelo unidimensional y la proporción de varianza explicada. La mayoría de personas eligió la opción “No”, además, tanto las cargas factoriales como los índices de ajuste son evidencias que apuntan a la unidimensionalidad del test. Cabe señalar que la confiabilidad de las puntuaciones derivadas de la aplicación del test estimada mediante el coeficiente alfa de Cronbach es de .841.
Tabla 1 Descriptivos y resultados del análisis factorial confirmatorio (N = 1563)
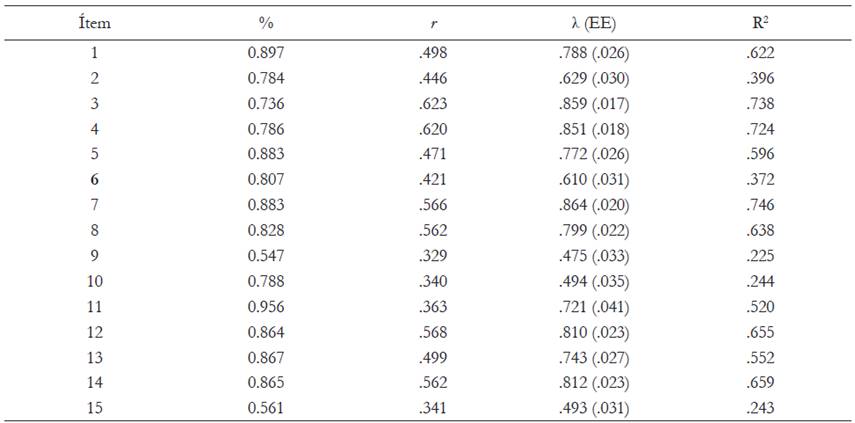
Nota. χ2 = 358.479 (30, p < .001), CFI = .974, TLI = .97, RMSEA =.044 [.039, .048].
Por otra parte, en la Tabla 2 se pueden apreciar diferentes índices de ajuste para los tres modelos que se pusieron a prueba. Dado que actualmente no existe un único método ampliamente aceptado para comparar modelos con distintas clases latentes, es necesario combinar la teoría sustantiva que se utilizó como base para construir el test así como los diferentes índices de ajuste diseñados para comparar modelos con un número creciente de clases latentes (Masyn, 2013).

En este caso, se observa que el AIC, el BIC y el BIC ajustado (BICa) no coinciden en cuanto a cuál modelo representa mejor los datos, ya que el AIC más pequeño corresponde al modelo de tres clases, mientras que el BIC apunta al modelo de una clase y el BICa al de dos clases. Por su parte, las pruebas de razón de verosimilitudes Vuong-Lo-Mendell-Rubin (VLMR-LRT) y Lo-Mendell-Rubin ajustada (LMRALRT) muestran un valor p estadísticamente significativo (p < .05) cuando se compara el modelo de una clase con el de dos clases, no así con el de tres clases respecto del de dos clases (Asparouhov & Muthen, 2012). Finalmente, el valor de la entropía (EN) es moderado para el modelo de dos clases latentes, lo cual indica que existe cierta incertidumbre a la hora de asignar a los sujetos a una u otra clase latente (Asparouhov & Muthen, 2014).
Con base en estos resultados se decidió elegir el modelo de dos clases latentes para ejemplificar algunos de las etapas involucradas en este tipo de análisis. Sin embargo, es necesario recalcar que sería necesario en este punto incluir a expertos en el constructo medido por la escala para determinar desde un punto de vista sustantivo si interpretable la existencia de dos tipos de examinados en la muestra.
En la Tabla 3 se presentan los parámetros estimados para cada ítem, tanto en la clase uno como en la clase dos. El parámetro a corresponde al índice de discriminación y el parámetro b, al de dificultad. Entre paréntesis se consignan los errores estándar. En la última columna aparecen los valores de entropía para cada ítem, lo cual permite identificar qué tanto contribuye cada ítem a la separación entre las dos clases latentes.
Tabla 3 Parámetros estimados con el modelo de dos clases latentes
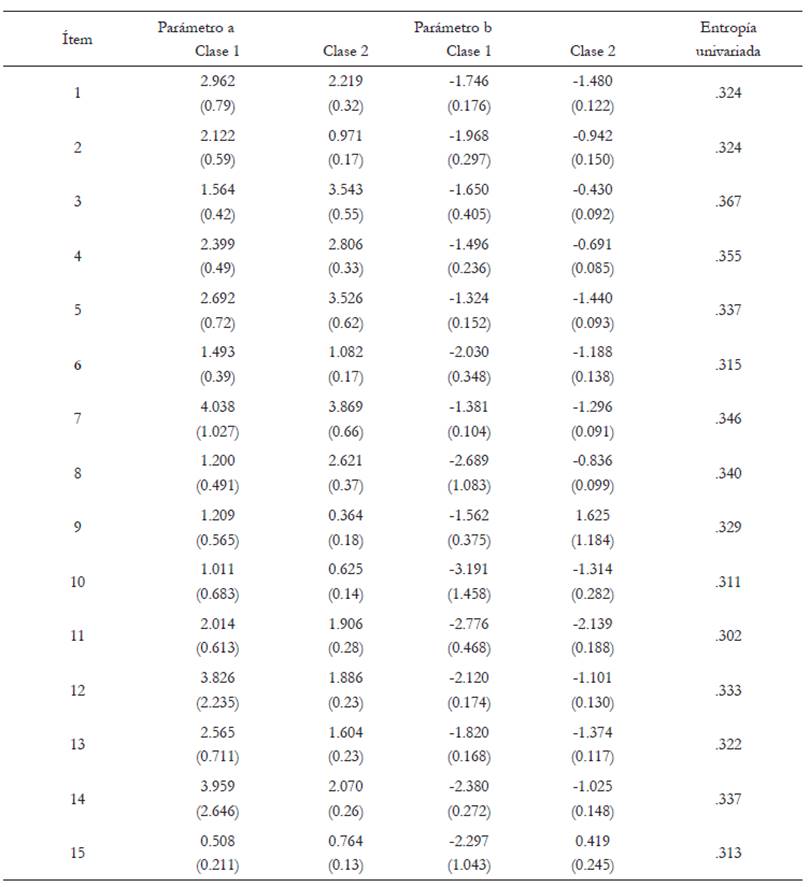
Nota.Entre paréntesis se presentan los errores estándar.
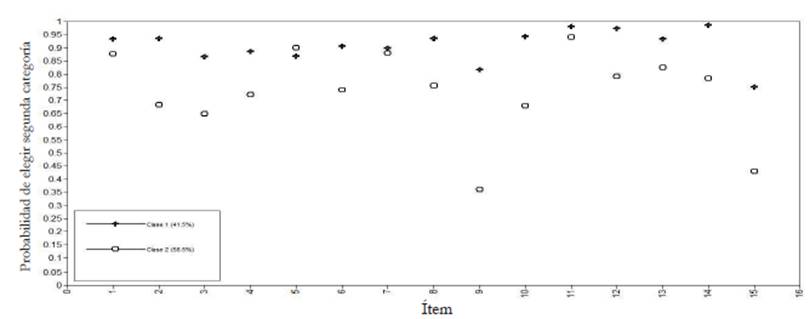
Para complementar dicha información en la Figura 1 se presentan las probabilidades de elegir la opción “No” en cada ítem y para cada clase latente. En términos generales, se puede observar que las probabilidades de seleccionar dicha opción son menores en los examinados asignados a la clase 2, diferencia que se acentúa en los ítems 9 (“¿Prefirió quedarse en casa en vez de salir y hacer cosas?”) y 15 (“¿Creyó que las personas están en una situación mejor que usted?”), los cuales además muestran valores muy diferentes a los que se observan en los demás ítems en la tabla 1.
Conclusiones
De acuerdo con los resultados observados, es posible plantear que los ítems 9 y 15 podrían estar midiendo de manera distinta el constructo en una escala sobre la cual se tienen evidencias de unidimensionalidad. A pesar de que la gran mayoría de los parámetros de los ítems no difieren de manera importante en las clases latentes identificadas, este análisis puede servir de base para utilizar un modelo confirmatorio (como por ejemplo, el análisis del funcionamiento diferencial del ítem) que permita entender mejor las razones por las cuales algunos ítems no miden de la misma manera el constructo en todos los examinados.
Un aspecto importante de recalcar es que los modelos de la Teoría de respuesta al ítem son de carácter exploratorio, por lo que los resultados derivados de su aplicación no deben emplearse como evidencia definitiva para la toma de decisiones. Es de vital importancia que se incluyan análisis descriptivos guiados por la teoría que fundamentó la construcción del instrumento para determinar características importantes de los sujetos asignados a cada clase latente. Y, finalmente, también se deben incorporar metodologías confirmatorias (utilizando otra muestra de examinados) para generar evidencias de que los resultados observados son generalizables.