









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Aunque el formato de elección múltiple sigue siendo muy utilizado en la evaluación educativa por razones prácticas (economía en el tiempo de administración, corrección objetiva y automática, amplio muestreo de un dominio, etc.), se han destacado sus limitaciones para evaluar las habilidades de nivel cognitivo superior y para estimar el nivel de destreza de las personas en contextos realistas (Martínez-Arias, 2010). Por ello, en la última década del pasado siglo los procedimientos de evaluación educativa incorporaron a los clásicos tests de elección múltiple los denominados tests de desempeño que se utilizan para evaluar competencias complejas como, por ejemplo, la expresión escrita y oral en el contexto del aprendizaje de lenguas (Hambleton, 2000).
Los tests de desempeño (performance assessment) son procedimientos de evaluación en los que se demanda a los sujetos que lleven a cabo tareas en las que han de demostrar su capacidad para aplicar conocimientos y destrezas en situaciones similares a las de la vida real (Martínez-Arias, 2010). Destaca en este tipo de pruebas su formato abierto: las respuestas, que son estructuradas o construidas por el examinado, han de ser cuantificadas mediante una escala de categorías ordenadas (rating scale) por un calificador. Obviamente la calificador del criterio del calificador en la puntuación otorgada es determinante, por lo que se ha utilizado la denominación de evaluación mediada por el calificador(rater mediated assessment) para caracterizar el aspecto central de este tipo de metodología (Engelhard, 2002). Es decir, la magnitud de las calificaciones que reciben los examinados no dependen sólo de su nivel de competencia, sino que hay considerar otras facetas que la influyen notablemente como la calificador de las tareas y de los atributos a evaluar, la severidad del calificador y su uso de las rubricas o categorías de calificación. Sin duda, el comportamiento de los calificadores ha de ser tomado en consideración si se desea evaluar de forma válida y justa el constructo de interés (Lane & Stone, 2006).
El objetivo de este trabajo es mostrar la utilidad de uno de los modelos de Rasch, denominado Many-Facet Rasch Measurement (Linacre, 1989), para medir en una dimensión común los elementos de las facetas que suelen estar incluidas en el marco de una evaluación del desempeño: los examinados, los calificadores, las tareas y los atributos evaluados.
Como un ejemplo del uso del modelo se presenta el análisis de una prueba de Expresión Escrita integrada en un examen para la obtención del Diploma de Español como Lengua Extranjera (DELE) de Nivel B. Los DELE son títulos oficiales que emite el Instituto Cervantes en nombre del Ministerio de Educación, Política Social y Deporte del Gobierno de España. El Diploma de Español de nivel B1 acredita la capacidad del usuario de la lengua para comprender los puntos principales de textos orales y escritos en variedades normalizadas de la lengua que versen sobre asuntos conocidos, ya sean estos relacionados con el trabajo, el estudio o la vida cotidiana; para desenvolverse en la mayoría de las situaciones y contextos en que se inscriben estos ámbitos de uso, y para producir asimismo textos sencillos y coherentes sobre temas conocidos o que sean de interés personal, tales como la descripción de experiencias, acontecimientos, deseos, planes y aspiraciones o la expresión de opiniones. El modelo Many-Facet Rasch Measurement se ha utilizado extensamente para analizar exámenes de expresión oral y escrita del inglés y del español (Eckes, 2011; Gyagenda & Engelhard, 2010; Kondo-Brown, 2002; Park, 2004; Prieto, 2011; Prieto & Nieto, 2014; Tyndall & Kenyon, 1996; Wolfe, 2009).
El modelo Many-Facet Rasch Measurement (MFRM)
MFRM fue desarrollado por Linacre (1989) para extender el Modelo Dicotómico de Rasch (1960), el Modelo de Escalas de Calificación (Andrich, 1978) y el Modelo de Crédito Parcial (Masters, 1982) a las evaluaciones en las que uno o varios calificadores puntúan el desempeño de una persona en una tarea de formato abierto. El objetivo de los modelos de Rasch, Andrich y Masters es medir conjuntamente en una dimensión los elementos de dos facetas: las personas y los ítems. La propiedad principal de esta familia de modelos, denominada objetividad específica por Rasch (1977), es el fundamento de la invarianza de las medidas.
De acuerdo con Engelhard (2013), la medición invariante de personas e ítems se puede lograr si se cumplen cinco requisitos: (a) las medidas de las personas deben ser independientes de los ítems específicos utilizados para medir, (b) una persona con mayor competencia (o aptitud) debe de tener siempre una mayor probabilidad de éxito en un ítem que una persona menos competente (las curvas características de las personas no se cruzan), (c) las medidas de los ítems han de ser independientes de las personas empleadas para la calibración, (d) cualquier persona habrá de tener mayor probabilidad de éxito en un ítem fácil que en un ítem más difícil (las curvas características de los ítems no se cruzan) y (e) los ítems y las personas deben ser localizados simultáneamente en una única dimensión latente (mapa de la variable). El objetivo de MFRM es incorporar más facetas al marco de medición: tal es el caso de los calificadores (evaluadores).
La incorporación de esta faceta implica redefinir las condiciones anteriores para lograr la invarianza de las medidas: (a) la medición de las personas ha de ser independiente de los calificadores específicos que han intervenido en la medición, (b) una persona con mayor competencia tendrá mayor probabilidad de obtener de los evaluadores mayores calificaciones que una persona con menor competencia (las curvas características de las personas no se cruzan), (c) la calibración de los calificadores ha de ser independiente de las personas a las que han evaluado, (d) cualquier persona ha de tener mayor probabilidad de obtener una puntuación alta de los calificadores benévolos que de los calificadores más severos (las curvas características de los calificadores no se cruzan) y (e) los calificadores y las personas deben ser localizados simultáneamente en una única dimensión latente (mapa de la variable).
El cumplimiento de los requisitos enunciados anteriormente en un conjunto de datos puede ser contrastado mediante los estadísticos de ajuste que se describen más adelante. Si los datos se ajustasen aceptablemente al modelo, las medidas pueden recibir algunas interpretaciones especialmente útiles y deseables: las calificaciones de los examinados son independientes de la severidad de los calificadores que les han evaluado y los valores de los calificadores en la dimensión denominada severidad/benevolencia son independientes de la competencia de los alumnos evaluados.
MFRM puede ser expresado de distintas formas en función del número de facetas y de los objetivos del estudio. Una expresión muy común se basa en una extensión del Modelo de Escalas de Calificación a una situación en la que existen más de dos facetas que contribuyen a la variabilidad de las medidas (examinados, calificadores, atributos evaluados, tareas, etc.). En este caso, se trata de un modelo lineal aditivo basado en una transformación logística de los cocientes entre las probabilidades de que una persona, puntuada mediante una escala de categorías numéricas, reciba una puntuación o la inmediatamente inferior. En concreto,

En la ecuación 1, el logit (ln (Pnijk /P nij(k-1) )) es la variable dependiente y las diversas facetas (personas, tareas, calificadores, atributos, etc) son las variables independientes. Es decir, el modelo especifica que la probabilidad de que el calificadorj otorgue a una persona n una calificación (k) en lugar de la inferior (k-1) en atributo l depende de los efectos aditivos de la calificador de la tarea (D i ), de la severidad del calificador (R j ), de la competencia de la persona (B n ), de la calificador del atributo evaluado (C l ) y del valor del paso entre las categorías k y k-1 (F). El paso o k
umbral no es considerado una faceta del modelo y en esta formulación se asume que es invariante en los distintos calificadores, tareas y dominios. Cuando no se asume la invarianza de los pasos (suponiendo, por ejemplo, que los calificadores difieren en el uso de las rúbricas) la formulación de MFRM es una extensión del Modelo de Crédito Parcial con el que se desea analizar las peculiaridades de los calificadores al usar las categorías numéricas:
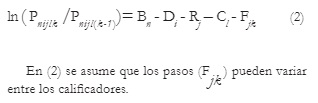
Mediante MFRM, los parámetros de cada faceta pueden ser estimados independientemente del resto de las facetas en una escala común (la escala logit). Las sumas de las puntuaciones directas son los estadísticos suficientes para estimar los parámetros (Linacre & Wright, 2002). La escala logit puede oscilar entre 0 ± ∞. El punto 0 se fi ja convencionalmente en el nivel medio de los ítems, de los calificadores, de las tareas y de los atributos, permitiendo la variación libre en la escala común de las personas evaluadas.
Para cada elemento de cada faceta, el análisis facilita una medida en logit, un error típico de medida (SE=la precisión del valor estimado) e índices de ajuste entre las respuestas observadas y las predichas por el modelo.
Aunque lo más común es utilizar la escala logit, puede ser útil presentar los valores en una escala denominada promedio imparcial (fair average). El promedio imparcial (M I ), el caso de los examinados, es la media de las puntuaciones que otorgaría a una persona un calificador con un nivel promedio de severidad (Eckes, 2011). Para calcular cada puntuación esperada para una persona n, se fi jan en la media (M) los parámetros de todas las facetas excepto la de la persona. Es decir, la ecuación (1) se reformularía de la siguiente forma:

Siendo r la puntuación en la escala de categorías recibidas por un examinado n. La media debe de contabilizar las puntuaciones de cada persona en las tareas, los atributos y los calificadores. M I es un valor en la escala de puntuaciones brutas asignadas a las categoría (0-3, por ejemplo) por lo que los valores son de más fácil interpretación que los logit.
De forma similar es posible obtener el promedio imparcial de cada calificador para puntuar su nivel de severidad. En este caso, M I es la media de las puntuaciones que otorgaría un calificador a un examinado con un nivel medio de competencia. Además de estos estadísticos a nivel individual, es posible obtener estadísticos grupales indicativos del ajuste promedio, la media, la variabilidad y la fiabilidad de las medidas de las personas, los ítems y los calificadores (Myford & Wolfe, 2004a).
Si los datos se ajustan al modelo, las medidas tienen unas características muy deseables: invarianza de las medidas de las personas, los calificadores, las tareas y los atributos, la medición con propiedades de intervalo y la cuantificación de la precisión a nivel local (Prieto & Delgado, 2003). Los análisis pueden llevarse a cabo con el programa FACETS (Linacre, 2015).
Estadísticos básicos
Índices de ajuste. Indican el grado en el que las calificaciones observadas se diferencian de las esperadas. Una calificación observada es la otorgada por un calificador a un evaluado en un atributo. Una calificación esperada es la predicha por el modelo, dado el nivel del examinado, la severidad del calificador y la calificador de la tarea. Los índices de ajuste son medias de los cuadrados de las diferencias estandarizadas: Outfi t es la media no ponderada de estos valores (muy sensible a desajustes extremos) e Infi t, la media de los valores ponderados con la función de información (Wolfe, 2009).
Ambos estadísticos tienen un valor esperado de 1 y pueden oscilar entre 0 e infi nito. Los valores menores que 1 revelan que los residuos (diferencias entre los valores observados y esperados) son menores que los esperados por azar (es decir, se puede interpretar como sobreajuste).
Son los valores superiores a 1 los que manifiestan más desajuste de lo esperado. Convencionalmente, se considera que los valores que oscilan entre 0.5 y 1.5 indican un desajuste muy pequeño y que los superiores a 2 revelan un desajuste severo que degrada las medidas (Linacre, 2010). Sin embargo, otros criterios más estrictos indican que Infi t y Outfi t deberían ser menores a 1.2 y 1.7 respectivamente para obtener una medición productiva (Smith, Schumaker & Bush, 1998). FACETS aporta valores individuales de ajuste para los evaluados, los calificadores, los ítems y las categorías de calificación.
Contraste Chi-cuadrado de la inexistencia de diferencias en una faceta (χ2)
Mediante el estadístico Chi-cuadrado se puede contrastar la hipótesis nula de que las estimaciones de los parámetros de los elementos de una faceta no difierensignificativamente entre sí. Por ejemplo, en la faceta “calificador”, se puede contrastar la hipótesis de que, contabilizando el error de medida, todos los calificadores ejercen el mismo nivel de severidad (Myford & Wolfe, 2004a).
Fiabilidad entre calificadores
Los índices estadísticos que se han utilizado para analizar la fiabilidad entre los calificadores pueden ser clasificados en dos categorías: índices deconsenso e índices de consistencia (Eckes, 2011). Los índices de consenso reflejan el grado en el que los calificadores atribuyen las mismas calificaciones en idénticas circunstancias. En esta categoría se inscribe el Porcentaje de Acuerdo (% Acuerdo), aportado por FACETS, que indica el porcentaje de veces que un calificador atribuye las mismas calificaciones que otros calificadores en idénticas circunstancias (examinado, tarea, atributo, etc.). Los índices de consistencia indican el grado de asociación entre las calificaciones otorgadas por distintos calificadores. A esta categoría pertenece la Correlación calificador-resto de los calificadores (Rc,rc ) que cuantifica el grado en el que las evaluaciones de cada calificador son consistentes con las del resto de los calificadores. Convencionalmente, los valores inferiores a .30 permiten identificar a los evaluadores muy inconsistentes, en los que la ordenación de las personas difiere notablemente de la del resto de los calificadores.
Fiabilidad de la separación de las medidas (SR: separation reliability). Además de evaluar la precisión individual de las medidas mediante el error estándar (de cada persona, cada calificador o cada ítem), FACETS proporciona evaluaciones de la fiabilidad a nivel de grupo. SR es un índice empleado para evaluar la fiabilidad de las puntuaciones de las distintas facetas (las personas, las tareas, los atributos o los calificadores) que refleja cuál es la proporción de la varianza verdadera respecto de la varianza observada de las medidas.
Las interpretaciones sustantivas de SR identificación entre las facetas (Myford & Wolfe, 2004a). En el caso de las medidas de las personas, PSR (Person separation reliability) es comparable al coeficiente alfa empleado en la Teoría Clásica de los Tests, indicando qué proporción de la varianza observada de las medidas de las personas es su varianza verdadera:

En este caso, se esperan altos valores de PSR cuando las medidas reflejancalificador la variabilidad de las personas en el constructo. Dado que se suele desear que no existan variaciones sustanciales entre los calificadores en el nivel de severidad, los valores bajos de RSR (Rater separation reliability) son los aceptables (las diferencias observadas en la severidad de los calificadores serían atribuibles al error de medida).
Estadísticos de las categorías de evaluación. Para determinar si las categorías numéricas (rúbricas) son funcionales empíricamente (ordenadas y distinguibles) se toman en consideración varios indicadores: orden de los promedios en las categorías de las medidas de las personas, Outfi t, y orden de los pasos entre las categorías (Linacre, 2004).
Si las categorías de evaluación funcionan adecuadamente, los promedios de las medidas (logit) de las personas que reciben una calificación deben estar ordenados monotónicamente. Este patrón de resultados revela que cuanto mayor sea la calificación recibida, mayor será el nivel de las personas en el constructo (Park, 2004). Los valores Outfi t de las categorías son también un indicador de su funcionalidad.
Para cada categoría de evaluación, FACETS calcula la medida promedio de las personas incluidas en la categoría (la medida observada) y una medida esperada (el promedio esperado si los datos se ajustasen al modelo). Como se indicó con anterioridad, si el valor observado y el esperado son muy semejantes, Outfi t adoptará un valor próximo a 1.0.
Los valores de Outfi t superiores a 2.0 indican que la categoría de evaluación no ha sido utilizada de manera adecuada. Finalmente, se puede observar si los pasos entre las categorías están ordenados monotónicamente y suficientemente separados. El desorden de los pasos indica que existen categorías que no son las de más probable uso en ningún rango de la variable medida. Esta circunstancia se manifiesta en el aplanamiento de las curvas características de las categorías.
Método
Participantes
Realizaron el examen 948 personas con edades entre 12 y 69 años, y una media de edad de 25 años. El país de nacimiento de los participantes fue muy diverso, siendo los más frecuentes Italia (18.8%), China (13.7%), Grecia (10.5%), Japón (13.9%) y Corea del Sur (13.8%). Los examinados realizaron la prueba en el mes de julio de 2014 en centros propios o adscritos al Instituto Cervantes de más de 30 países, correspondiendo los grupos más numerosos de participantes a centros de Italia (18.4%), China (12.0%), España (11.7%), Japón (10.7%), Grecia (10.7%) y Corea del Sur (10.3%).
Las pruebas fueron evaluadas por un total de 14 calificadores (2 hombres y 12 mujeres), todos ellos profesores de Cursos Internacionales de la Universidad de Salamanca con una amplia experiencia en la enseñanza del español a alumnos extranjeros.
Prueba
La prueba de expresión escrita constaba de dos tareas. En la primera se le pidió al examinado que redactase un texto con una intención comunicativa (carta, correo electrónico, etc.) con una extensión entre 100 y 200 palabras. La segunda tarea consistió en la redacción de un texto, con una extensión entre 130 y 150 palabras, con una finalidad narrativa.
Procedimiento
Los textos de cada examinado fueron evaluados independientemente por dos calificadores, los cuáles puntuaron cada texto en cinco atributos: una calificaciónholística (que representa la impresión global del desempeño del examinado) y cuatro calificaciones analíticas. Las variables analíticas fueron: Adecuación al género discursivo (adaptación de la redacción al contexto), Coherencia (control de los recursos necesarios para establecer relaciones entre el discurso y la situación de comunicación), Corrección (conocimiento y capacidad de uso de la ortografía, de las categorías gramaticales y de las reglas morfosintácticas) y Alcance (equilibrio de los recursos léxicos utilizados con los temas y las situaciones de comunicación). Para emitir las calificaciones se usó un sistema de rúbricas consistentes en cuatro categorías numéricas ordenadas (0-3). El valor 2 es el equivalente a la superación mínima del umbral correspondiente al nivel B1. El valor 3 supone una consecución sobrada del nivel. El valor 1 indica que el desempeño no permite superar el umbral correspondiente a la consecución del nivel. La puntuación 0 se asigna cuando el texto es ilegible o la información es irrelevante y no se ajusta al objetivo. Los calificadores recibieron instrucciones con ejemplos prototípicos de textos clasificables en cada categoría.
Dado que los textos de cada examinado no eran evaluados por todos los calificadores, se implementó un sistema de asignación de las pruebas para garantizar la conectividad que es imprescindible para lograr que todas las medidas estén en la misma escala. Es decir, debe ser posible discernir si la diferencia en las calificaciones recibidas por dos examinados se debe a que uno de ellos es más competente que el otro o a que el calificador que evaluó al primero es más benigno que el que evaluó al segundo. Una estimación óptima de la severidad de los calificadores requeriría que todos los calificadores evaluasen todas las pruebas. Obviamente, este procedimiento no puede ser empleado en muchas situaciones. Por tanto, es necesario aplicar un plan de asignación de las pruebas a los calificadores que, garantizando la conectividad, sea asequible en la práctica. Los requisitos mínimos de estos planes consisten en que al menos dos calificadores evalúen cada prueba y que cada examinado comparta un calificador con otro examinado. Existen varios diseños de asignación de las pruebas a los calificadores para garantizar la conectividad (Eckes, 2011; Wright & Stone, 1979). El diseño más simple consiste en asignar a un calificador un subconjunto pequeño de las pruebas evaluadas por cada uno de los demás calificadores (Eckes, 2011). En este trabajo se utilizó un diseño simple de rotación de los examinados y los calificadores similar al descrito por Tesio et al. (2015).
Resultados
Dada la necesaria brevedad de este artículo, se comentarán principalmente los resultados correspondientes a las facetas de examinados y de calificadores. No obstante, una inspección del mapa de la variable o mapa de Wright (Figura 1) es útil para observar las calibraciones de los elementos de todas las facetas en un único marco de referencia.
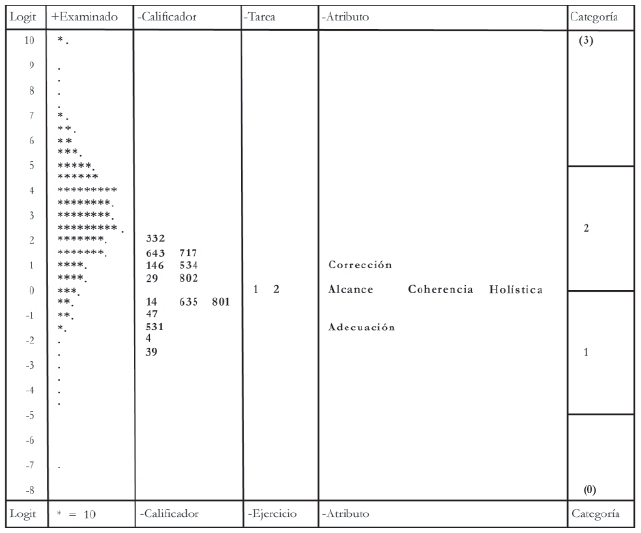
Figura 1: Mapa de la variable derivado del análisis con MFRM. Cada estrella representa a 10 examinados y cada punto a menos de 10. Los calificadores están representados por su número de identificación.
En la primera columna del mapa aparece la escala logit en la que se miden los examinados, los calificadores, las tareas, los atributos y los umbrales entre las categorías.
En la columna Examinado de la Figura 1 se representa la distribución de los examinados en la escala. Cada asterisco (*) representa a 10 personas y cada punto a una frecuencia inferior. Los candidatos con mayor nivel en la prueba de expresión escrita se sitúan en la parte superior de la columna y en la parte inferior los de menor puntuación. Se observa que el rendimiento de los examinados es elevado (2.82 logits en promedio) y que hay una gran variabilidad en su competencia (entre 11.26 y -7.19 logits). En la columna Calificador aparecen los valores de severidad de los calificadores, siendo el número 332 el más severo (1.96) y el número 39 el más benigno (-2.29). Los valores en severidad oscilan en torno a 0 (suele situarse el punto cero de la escala en la media en severidad de los calificadores). La variabilidad de los calificadores en severidad es alta (la desviación típica es 1.36 logits) y mayor de lo que sería deseable: idealmente habría de observarse que los calificadores apenas difieren entre sí en la variable severidad, un indicador de que los criterios de asignación de las calificaciones son usados de manera uniforme por los calificadores. En la columna Tarea se muestra el nivel de calificador de los textos que debían escribir los examinados; se observa que las dos tareas apenas difieren en calificador. En la columna Atributo aparecen los valores de calificador relativa de los atributos en los que se han calificado las tareas. Se ha de notar que, aunque las diferencias en calificador son pequeñas, la variable corrección es la más difícil y la variable adecuación la más fácil. Finalmente, en la columna Categoría se muestran, mediante líneas, la localización en logits de los umbrales entre las categorías utilizadas para puntuar las respuestas de los candidatos (de 0 hasta 3). En este caso, se utilizó la formulación del modelo expresada en (1). Es decir, se asume que las categorías son utilizadas de manera similar por todos los calificadores.
En adelante, se comenta de forma más detallada las propiedades psicométricas de los valores de las facetas más relevantes: los examinados y los calificadores.
Examinados
En la parte superior de la Tabla 1 se muestran, como ilustración de la salida proporcionada por el programa FACETS, los resultados de tres examinados cuyo número de identificación aparece en la primera columna (ID). En la columna 2 se muestran sus puntuaciones logit en la variable medida. Se observa que el sujeto 1 presenta una alta competencia (3.24). Por el contrario, el nivel en la variable del sujeto 82 es muy bajo (-2.25 logits). La suma de las 20 calificaciones(r = 2 calificadores x 2 tareas x 5 atributos) recibidas por cada examinado aparecen en la columna X y su media en la columna M O (Promedio de las calificaciones observadas). Los valores Χ y M O dependen del grado de severidad de los calificadores que han puntuado a cada examinado. Por ello, es conveniente utilizar como indicador de su competencia la puntuación en logit o el Promedio imparcial (M I ), que es la media de las calificaciones que recibiría el examinado de un calificador con un nivel medio de severidad. Enlas dos últimas columnas de la derecha aparecen los estadísticos de ajuste: se observa que los examinados 1, 10 y 82 presentan valores de un ajuste aceptable (indicativo de que su desempeño ha sido interpretado por los calificadores consistentemente).
Tabla 1: Puntuaciones y estadísticos descriptivos de los examinados
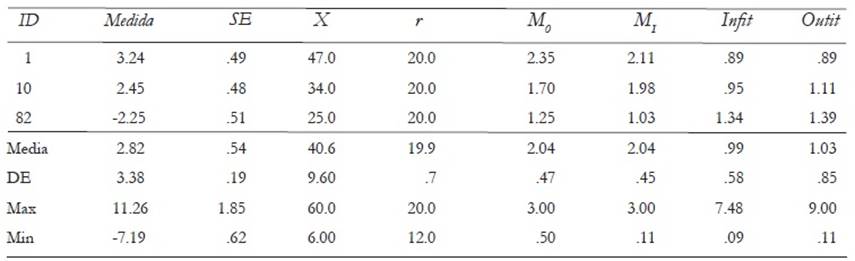
Nota. Medida: Valor en logits; SE: Errór estándar; X: suma de las calificaciones; r: número de calificaciones; MO: Promedio observado; MI: Promedio imparcial; Infit y Outfit: estadísticos de ajuste.
En la parte inferior de la Tabla 1 aparecen los principales estadísticos de las puntuaciones de los candidatos (N = 948) que realizaron el examen de expresión escrita. Se aprecia un rendimiento medio muy superior (2.82 logits) a la calificador media de las tareas (situada en 0). Asimismo, se observa una alta variabilidad (DE = 2.38 logits) entre los examinados que es significativa estadísticamente ( χ 2 = 16135.1, gl=947, p< .0001). Las medidas de los candidatos oscilaron entre 11.26 logits y -7.19 logits. La fiabilidad de las puntuaciones es muy elevada (PSR=.95), lo cual indica que las puntuaciones en el examen permiten diferenciar calificador entre los diferentes niveles de competencia de los examinados. El ajuste al modelo de las calificaciones otorgadas a los examinados es aceptable, dado que las medias de Infi t y Outfi t apenas difieren de 1.0 y que el porcentaje de los candidatos que presentan un desajuste severo con las predicciones del modelo es bajo (7.28%).
Calificadores
En la Tabla 2 se muestran los promedios (en la escala de 0 a 3) de las evaluaciones de los calificadores: M O y M I , las puntuaciones en severidad (en la escala logit), su precisión (SE), los estadísticos de ajuste y los índices de fiabilidad entre calificadores (consenso y consistencia). Se observa que la variabilidad de los calificadores en severidad es elevada (DE = 1.36 logits) y significativa estadísticamente ( χ 2 = 6062.8, gl=13, p< .0001), este dato no es el deseable. Idealmente las variaciones en severidad habrían de ser bajas y atribuibles al error de medida, por lo que RSR (Rater separation reliability) debería ser bajo. Sin embargo, el índice RSR observado alcanza el valor máximo (1.00): un valor tan alto revela que las diferencias observadas en severidad entre los calificadores son muy fiables. De hecho, la precisión de las estimaciones de la severidad es alta: el error estándar de los estimadores del parámetro de severidad es muy bajo (.06) en todos los casos. Los extremos en la escala de severidad están ocupados por el calificador ID 332 (el más severo: 1.96 logits) y el calificador ID 39 (el más benigno: -2.29 logits).
Tabla 2: Puntuaciones y estadísticos descriptivos de los calificadores
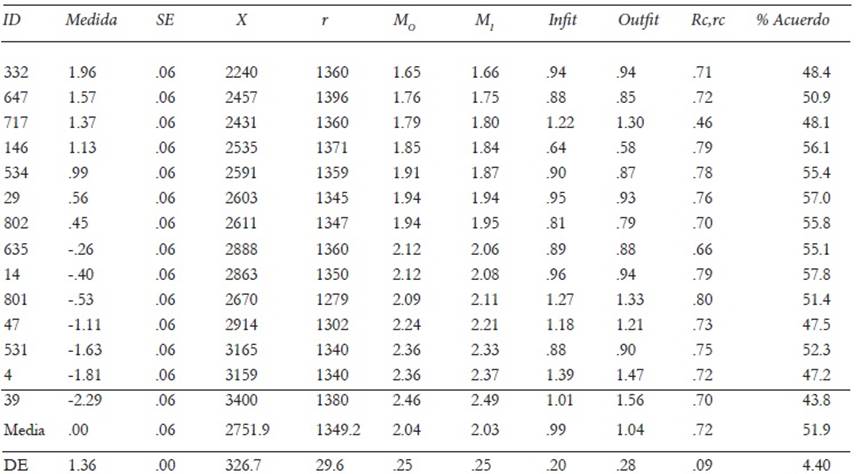
Nota.Medida= Valor en logits; SE= Errór estándar; X= suma de las calificaciones; r = número de calificaciones otorgadas; MO= Promedio observado de las calificaciones; MI= Promedio imparcial de las calificaciones; Infi t y Outfi t: estadísticos de ajuste; Rc,rc: estadístico de consistencia entre calificadores; % Acuerdo: estadístico de consenso entre calificadores.
En la escala de puntuaciones brutas en la que se expresa el Promedio imparcial (M I ), indicador del grado de severidad en la escala de 0 hasta 3, se observa igualmente una gran variabilidad que oscila entre 2.49 para el calificador más benigno (ID 39) y 1.65 para el calificador más severo (ID 332). Entre ambos calificadores la diferencia en puntuaciones directas es notable (.84 puntos). Se ha de notar que la relación entre las escalas en M I y en logits es inversa: las mayores puntuaciones en la primera indican mayor benevolencia, mientras que en la segunda manifiestan mayor severidad.
Los valores de los estadísticos de ajuste indican un ajuste adecuado de los calificadores. Por un lado, las medias de Infi t y Outfi t difieren escasamente de la unidad con una variabilidad baja. Por otro, se observa que los valores se sitúan en un rango aceptable: Infi t entre .64 y 1.39; Outfi t entre .58 y 1.56. Estos datos indican que todos los calificadores muestran una adecuada consistencia interna (intra-calificador) en sus evaluaciones.
Los estadísticos relacionados con la fiabilidad entre calificadores aparecen en las dos últimas columnas de la Tabla 2. Las correlaciones de las evaluaciones de cada calificador con los demás calificadores son altas (media= .72 ; rango entre .46 y .80) indicando que hay una consistencia elevada entre los calificadores (la ordenación de los examinados en competencia es muy semejante entre ellos). Los índices de consenso de los calificadores (% Acuerdo: porcentaje de veces que cada calificador atribuye las mismas calificaciones que otros calificadores en idénticas circunstancias) oscilan entre 43.8% y 57.8%, con una media de 51.9%. En consecuencia, se ha de considerar que el grado de consistencia externa es mayor que el grado de consenso. Este dato se corrobora al analizar las propiedades métricas de las categorías de respuesta (rúbricas).
Categorías
En la Tabla 3 aparecen los estadísticos correspondientes a las categorías de respuesta derivadas de la formulación (1), la extensión de MFRM a partir del Modelo de Escalas de Calificación. Puede observarse que han sido empleadas todas las categorías numéricas y que la asignada más veces (55%) fue la2. Además, las medidas promedio de cada categoría se incrementan monotónicamente desde -1.54 hasta 5.72 logits, el incremento de los promedios indica que cuanto mayor es la categoría, mayor es el nivel en la variable latente. Se observa asimismo que ninguna categoría desajusta severamente (Outfi t < 2.0) y que los umbrales (pasos) entre las categorías sucesivas no están desordenados. Este dato implica que todas las categorías son modales (Figura 2): cada una es la de más probable elección en algún intervalo de la variable medida. Además, los incrementos entre los umbrales sucesivos son grandes y permiten distinguir adecuadamente rangos amplios de diferente magnitud en la variable latente.

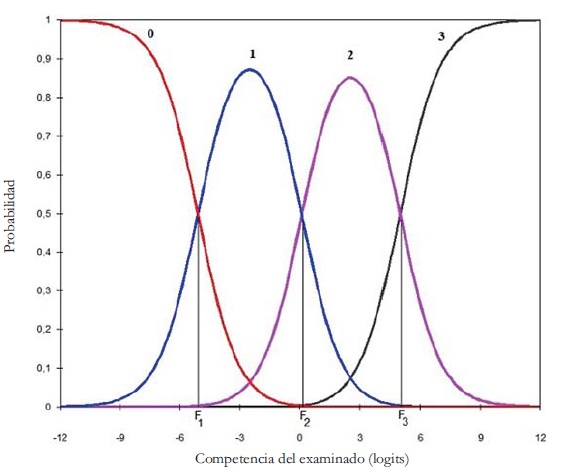
En consecuencia, del análisis grupal de los calificadores, se puede concluir que las categorías numéricas presentan una funcionalidad óptima para obtener medidas en la variable latente (Linacre, 2004).
Si no se asume que los calificadores utilizan las categorías de manera uniforme, conviene analizar los datos con un modelo híbrido que es una extensión del Modelo de Crédito Parcial (Véase la ecuación (2)). Este enfoque aporta evidencias sobre el uso de las categorías por cada calificador. En la Tabla 4 se muestra el uso de cada categoría por cada calificador y los valores de los umbrales entre las categorías adyacentes de cada uno de ellos. Puede observarse, por ejemplo, que el calificador más severo (ID 332) sólo ha asignado la calificación 3 un 4% de las veces, mientras que el calificador másbenigno (ID 39) la asignó el 52% de las veces. En la Tabla 3 se mostró que dichos calificadores presentaban un adecuado ajuste al modelo (alta consistencia interna). Además ambos tenían una alta consistencia con otros calificadores (Rc,rc ≥.70), lo cual indica que sus calificaciones ordenan a los examinados de forma similar. Sin embargo, los estadísticos de consenso con otros calificadores son moderados: el porcentaje de acuerdo de los dos calificadores que ocupan los extremos del continuo de severidad/benignidad es menor del 50%.
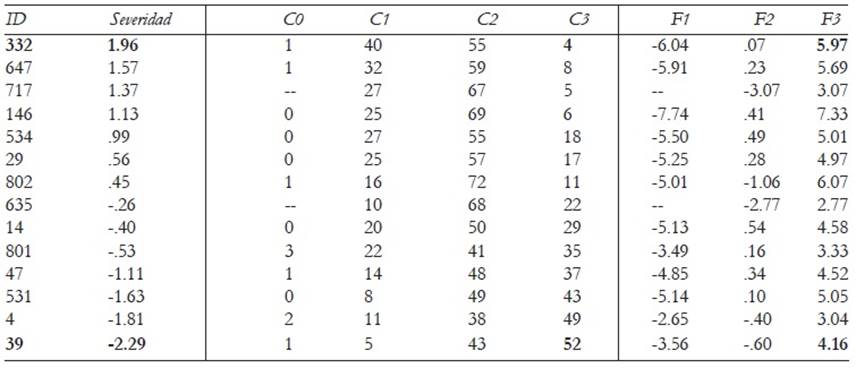
Tareas y Atributos
Ya se observaba en el mapa de Wright (Figura 1) que las dos tareas que debían desarrollar los examinados diferían escasamente en dificultad (tarea 1 = -.18 logits; tarea 2 = .18 logits). Sin embargo, aparecen mayores diferencias en dificultad entre los atributos evaluados, siendo la característica más difícil la Corrección gramatical del texto (1.18 logits)y la más fácil la Adecuación de la redacción al contexto (-1.46). Dado el gran número de calificaciones emitidas, los estimadores de la calificador de los elementos de ambas facetas son muy precisos (Item SeparationReliability, ISR): ISRTarea = .99 e ISRAtributo = 1.00, y su variabilidad es significativa estadísticamente: Tarea( χ 2 = 115.5, gl = 1, p< .0001) y Atributo ( χ 2 = 2358.2, gl = 3, p< .0001).
Discusión
Como se indicó al inicio, los tests de desempeño (performance assessment) son procedimientos de evaluación en los que los examinados realizan tareas de formato abierto que han de ser cuantificadas por un calificador mediante una escala de categorías numéricas. La calificador del criterio del calificador en la puntuación otorgada es determinante. Es decir, la magnitud de las calificaciones que reciben los examinados no dependen sólo de su nivel de competencia, sino que hay que considerar los efectos del calificador en la calificaciones: su grado de severidad o benignidad, su uso de las rubricas y otros efectos idiosincráticos como el de halo y el de tendencia central (Myford & Wolfe, 2004b). Los efectos del calificador han de ser considerados una amenaza para la validez de las calificaciones de los examinados (Lane & Stone, 2006). Además, en los programas de evaluación a gran escala se suele evaluar el comportamiento de los calificadores con el fi n de detectar a los más eficaces y medir el efecto del entrenamiento destinado a mejorar sus prácticas.
Con los procedimientos tradicionales de medición, basados en la Teoría Clásica de los Tests, no es posible discernir si la diferencia en las calificaciones recibidas por dos examinados se debe a que uno de ellos es más competente que el otro o a que el calificador que evaluó al primero es más benigno que el que evaluó al segundo. De forma similar, si el promedio de las calificaciones otorgadas por un evaluador es elevado, no es posible determinar si la magnitud de las calificaciones se debe a que el calificador es muy benigno, o si la muestra de personas que ha puntuado tiene una alta competencia. Para desenredar esta madeja conviene utilizar modelos psicométricos que permitan obtener la separabilidad de los parámetros de las personas y los calificadores (Tesio et al., 2015). Tal es el caso del modelo de Rasch en el que el teorema de la objetividad específica demuestra que es posible obtener medidas invariantes (Engelhard, 2013).
Desde esta perspectiva, se ha descrito el modelo MFRM, una extensión del modelo dicotómico de Rasch, que es apto para medir en la misma métrica los elementos de las distintas facetas que pueden influir en la variabilidad de las calificaciones: los examinados, los calificadores, las tareas, los atributos evaluados, etc.
Como un ejemplo del uso del modelo y de la interpretación de sus estadísticos, se ha realizado el análisis de una prueba de Expresión escrita integrada en un examen para la obtención del Diploma de Español como Lengua Extranjera (DELE) de Nivel B1. El examen fue realizado por 948 personas con lenguas maternas muy diversas. En la prueba los examinados escribieron dos textos que fueron evaluados independientemente por dos calificadores, los cuáles puntuaron los textos en cinco características o atributos. Participaron en total 14 calificadores a los que se asignaron las pruebas mediante un procedimiento simple de rotación de los examinados y los calificadores para garantizar la conectividad. El programa Facets no detectó ningún subconjunto de datos desconectado, por lo que fue posible localizar los elementos de todas las facetas en la misma métrica.
El objetivo prioritario de la evaluación era obtener medidas que representasen de forma válida la competencia en expresión escrita de los examinados y su localización en el mapa de la variable.
Tanto en logits como en la escala de puntuaciones brutas (Promedio Imparcial), se observó que rendimiento medio de los examinados es superior a la calificador media de las tareas y que su variabilidad es alta. Al estar en la misma escala de las categorías usadas en la evaluación, el uso del estadístico Promedio Imparcial es muy recomendable para informar a los usuarios poco familiarizados con la escala logit.
La fiabilidad de las puntuaciones de las personas examinadas fue muy elevada, indicando que las calificaciones otorgadas por los evaluadores diferenciaban calificador entre los distintos niveles de competencia de los examinados. El ajuste al modelo de las calificaciones otorgadas a los examinados era aceptable, dado que las medias de Infit y Outfit apenas difieren de 1.0 y que fue bajo el porcentaje de los candidatos que presentaban un desajuste severo (Outfit y/o Infit > 2.0).
Otro objetivo importante del análisis mediante MFRM fue obtener medidas que representasen de forma válida el grado de severidad/benignidad de los calificadores y su localización en el mapa de la variable. Se observó que las puntuaciones logits en el constructo eran muy fiables y que su variabilidad era elevada y estadísticamente significativa. La variabilidad en severidad constituye una fuente de error que decrementa la validez de las puntuaciones de los examinados. En la escala de puntuaciones brutas en la que se expresa el Promedio imparcial (M I ), se observó igualmente una gran variabilidad.
Un gran número de factores puede contribuir a que el estilo habitual de un calificador sea más severo o más benevolente: la experiencia profesional, los rasgos de personalidad, la carga de trabajo, las consecuencias de la evaluación, etc. En muchas ocasiones, por ejemplo, los calificadores más experimentados suelen ser más severos que los más novatos. Como indica Eckes (2011), no existe aún suficiente investigación acerca de los determinantes personales y situacionales de la severidad de los calificadores. Tampoco abundan los estudios sobre la estabilidad y el cambio en el estilo de los calificadores al puntuar.
En varios programas de evaluación a gran escala se han implementado programas de entrenamiento para eliminar o reducir la variabilidad entre los calificadores en los modos de evaluar. Los programas suelen basarse en la instrucción mediante calificadores expertos acerca de las tareas y los procedimientos de calificación. Se trata de generar en los calificadores un conocimiento compartido sobre aspectos como el constructo que se desea medir, la clasificación en los niveles de desempeño, los descriptores característicos de cada nivel, y el significado de las categorías numéricas o rúbricas (Eckes, 2011).
Pese a los esfuerzos invertidos en el entrenamiento, existen evidencias de que las diferencias entre los calificadores, aunque se reduzcan, perviven tras los programas de intervención (Congdom & McQeen, 2000). Por ello, es imprescindible utilizar un modelo, como el MFRM, que permita medir el desempeño de los examinados de manera objetiva separando la calificador de la severidad de los calificadores (McNamara, 2000).
Un elemento muy importante de evaluación mediada por el calificador es el análisis de la fiabilidad del calificador, que presenta dos vertientes: la consistencia interna (intra-calificador) y la fiabilidad entre calificadores. Los estadísticos de ajuste de los calificadores suelen ser interpretados como el grado de consistencia interna del calificador (Eckes, 2011; Engelhard, 2013): indican la consistencia al interpretar las rúbricas y los atributos en los distintos examinados. En este estudio se observó que los valores se situaban en un rango aceptable (Infit entre .64 y 1.39; Outfit entre .58 y 1.56).
Anteriormente se indicó que se usan dos tipos de indicadores para analizar la fiabilidad entre los calificadores: índices de consenso e índices de consistencia (Eckes, 2011). Los índices de consenso reflejan el porcentaje de veces que un calificador atribuye las mismas calificaciones que otros calificadores en idénticas circunstancias (examinado, tarea, atributo, etc.). Los índices de consistencia indican el grado de asociación entre las calificaciones otorgadas por distintos calificadores. Las correlaciones de las evaluaciones de cada calificador con los demás calificadores fueron altas, indicando que hay una consistencia elevada entre los calificadores. Sin embargo, los índices de consenso de los calificadores (% Acuerdo) oscilaron entre 43.8% y 57.8%. En consecuencia, se ha de considerar que, como en otros estudios, el grado de consistencia externa es mayor que el grado de consenso (Eckes, 2011).
Además de las diferencias en severidad, existen otros modos de calificar que, al introducir una variabilidad en las calificaciones que no está asociada al constructo de interés, han sido calificador tradicionalmente como errores del calificador: el efecto de tendencia central y el efecto de halo. El primero, un caso particular de la restricción del rango, se produce cuando sistemáticamente un calificador evita usar las categorías extremas. El segundo ocurre cuando el calificador no es capaz de diferenciar entre atributos conceptualmente diferentes del desempeño y tiende a asignar calificaciones similares a todos ellos (el término de halo se aplicó bajo la suposición de que la impresión producida en el calificador por uno de los atributos u otra característica del examinado influye en las demás calificaciones).
Suelen considerarse evidencias del efecto de tendencia central un bajo índice de fiabilidad (Rater Separation Reliability) o valores de Infit y Outfit sobreajustados (Myford & Wolfe, 2004). Asimismo, es una evidencia de este efecto la baja frecuencia de calificaciones en las categorías extremas. En nuestro estudio, el análisis del grupo de calificadores no presentó fuertes indicios de un efecto de tendencia central: los promedios de Infit y Outfit apenas difieren de la unidad, RSR = 1.0 y el 44% de las evaluaciones se distribuyen simétricamente en las categorías 1 y 3.
Por su parte, cuando la mayoría de los calificadores están influidos por el efecto de halo, las medidas de los atributos evaluados apenas difieren entre sí (el índice de fiabilidad de las medidas de los atributos es bajo). En nuestro caso, la fiabilidad alcanza el máximo nivel y el rango de las medidas de los atributos es elevado.
Además de estos efectos, los calificadores pueden diferir en el uso y la interpretación de las rúbricas. El análisis del grupo de calificadores revela que las rúbricas han sido utilizadas de forma adecuada de acuerdo con los criterios de Linacre (2004). Se ha de resaltar que los umbrales (pasos) entre las categorías sucesivas no están desordenados y que los incrementos entre los umbrales sucesivos son grandes y permiten distinguir adecuadamente rangos amplios de diferente magnitud en la variable latente.
No obstante, el análisis del comportamiento individual de los calificadores con un modelo híbrido de MFRM permite describir de manera más pormenorizada el uso de las categorías por parte de los calificadores. En nuestro caso, pudimos observar el modo idiosincrático de puntuar de los calificadores situados en los extremos de la escala de severidad.
En este trabajo, se ha presentado una introducción al MFRM y a su empleo para analizar los tests de desempeño. Por razones de extensión, otras aplicaciones más especializadas no han sido descritas en este artículo, tales como el análisis del funcionamiento diferencial de los calificadores y los procedimientos para analizar su exactitud (accuracy). Los índices de exactitud de los calificadores muestran las discrepancias o distancias entre las calificaciones observadas y un patrón o punto de referencia (benchmark) que comúnmente se define mediante el promedio de las calificaciones otorgadas por un grupo de calificadores muy expertos (Murphy y Cleveland, 1995). Pueden consultarse excelentes exposiciones de estos temas en Eckes (2011), Englehard (2013) y Myford y Wolfe (2004 a y b).