











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
La medición de habilidades de razonamiento y el dominio léxico (o conocimiento léxico) están estrechamente relacionados: las palabras y otras unidades lingüísticas de mayor tamaño han servido de medio para plantear y materializar las tareas de razonamiento; este es el caso de algunos componentes de la Batería de Woodcock Muñoz y de la Escala de inteligencia de Wechsler para adultos (WAIS). La naturaleza social y cultural de las lenguas, así como el carácter arbitrario del conjunto de signos del lenguaje, generan la necesidad de indagar más sobre los conocimientos lingüísticos requeridos para desarrollar los ejercicios de razonamiento de manera satisfactoria. Más aún, no es en vano que ciertos elementos, relaciones de semejanza y estructuras gramaticales (conjunciones, analogías y cláusulas condicionales, por ejemplo) hayan cobrado relevancia en los estudios sobre memoria, lógica y razonamiento (Daneman y Carpenter, 1980; Johnson-Laird, 1988).
Dada entonces esta relación entre la medición de habilidades de razonamiento y el dominio léxico, esta investigación tiene por objetivo generar evidencias sobre el dominio léxico en el contexto de relaciones semánticas de sinonimia, antonimia y temática en personas aspirantes al ingreso a la universidad. La generación de estas evidencias es uno de los mecanismos para garantizar la validez de los procesos de razonamiento medidos en la Prueba de Aptitud Académica (PAA) de la Universidad de Costa Rica con la menor incidencia posible de factores socioculturales.
La PAA es un test que mide habilidades generales de razonamiento y guarda una estrecha relación con el artículo de esta investigación. Específicamente, existe una correspondencia teórica entre las relaciones semánticas que en este trabajo se han denominado antonimia, sinonimia . temática con las categorías de los ítems de la PAA llamadas oponer, parafrasear . reducir, respectivamente.
En la categoría de oponer se utilizan dos unidades lingüísticas cuyos significados son contrapuestos. La unidad lingüística de menor tamaño que se podría utilizar es una palabra a partir de la cual se establece una relación denominada como antonimia.
En la categoría de parafrasear se utilizan dos unidades lingüísticas que, en un contexto determinado, tienen el mismo significado. En los ítems de la PAA, también se podría establecer este tipo de relaciones entre palabras; a esto se le llama sinonimia.
En los ítems de la categoría reducir, ''los evaluados deben realizar dos posibles tareas: uno, identificar la síntesis de la información expuesta en el texto principal en una proposición; dos, descubrir un elemento en común entre los significados de varias palabras, frases u oraciones'' (Rojas et al., 2019). Para realizar dichas tareas, los campos semánticos cumplen un papel fundamental: permiten el reconocimiento de grupos de palabras y la creación de una etiqueta para nombrar cada grupo de palabras o el conjunto de entidades que el grupo de palabras representa en la realidad extralingüística; este mismo proceso es esencial en la identificación de tópicos y, en consecuencia, en la categoría que se ha denominado temática.
La habilidad para identificar relaciones semánticas de antonimia, sinonimia y temática incide en el desempeño de las personas evaluadas al resolver ítems de las categorías de oponer, parafrasear y reducir, especialmente si la resolución de estos ítems depende en cierta medida del dominio léxico.
Por último, es importante aclarar a la población lectora cómo se estructura este artículo: en un primer lugar, se revisa la literatura pertinente al tema. De especial interés en esta sección son las investigaciones previas sobre léxico en la PAA, así como las vinculadas a relaciones semánticas en estudio (antonimia, sinonimia y temática). Posteriormente, se detallan los aspectos metodológicos: el enfoque, la conformación de la muestra, del muestreo y del instrumento utilizado. Además, se indica cómo se llevó a cabo el trabajo de campo y las técnicas utilizadas para el análisis. En seguida, se muestran los resultados según cada una de las relaciones semánticas. Por último, se presentan la discusión y las conclusiones del artículo.
Revisión de la literatura
La PAA de la Universidad de Costa Rica mide habilidades generales de razonamiento con ítems de selección única presentados en contextos verbales y matemáticos. Todos los ítems presentan un componente textual, el cual debe ser comprendido por las personas aspirantes para la resolución del ítem. En consecuencia, ha sido especialmente útil realizar investigaciones que analizan el dominio léxico para describir el constructor de la PAA (Brizuela y Montero, 2013; Calvo et al., 2019). Asimismo, estos trabajos se han realizado para garantizar que los ítems no incluyan conocimientos lingüísticos que impidan una medición equitativa. De igual manera, es indispensable estudiar cómo se conectan semánticamente las palabras que aparecen en los ítems, pues las relaciones de significado también podrían influir en la resolución de las tareas.
Las personas evaluadas no podrían resolver los ítems de la PAA sin acceder a la información lingüística que se utiliza para plantear la tarea de razonamiento general y el acceso a dicha información sucede, generalmente, mediante la lectura. Comprender un texto implica la activación de representaciones mentales y procesos cognitivos (Berko et al., 1999); por tanto, la resolución de los ítems también requiere la activación de los conocimientos lingüísticos de las personas evaluadas. En consecuencia, los estudios sobre el dominio léxico y las relaciones semánticas permiten abordar el proceso de resolución de los ítems desde un enfoque cualitativo y desde una perspectiva psicolingüística; es decir, gracias a estas actividades de investigación es posible caracterizar los ítems e identificar los aportes de las personas evaluadas en la resolución de las tareas de razonamiento en relación con el procesamiento del texto.
Con respecto a la resolución de tareas, las relaciones semánticas requieren de diferentes mecanismos que permiten a las personas hablantes contrastar las piezas léxicas. Más aún, la noción de contraste es fundamental incluso desde el estructuralismo lingüístico: es posible analizar cada unidad funcional según determinados rasgos distintivos (Varo, 2014). En el mismo sentido, desde una perspectiva cognitiva, la antonimia y la sinonimia no se diferencian de la categorización: también suceden gracias al contraste entre elementos, ya sea que estos se encuentren en un texto o formen parte de experiencia de la persona hablante en ámbitos particulares; es decir, en estas relaciones se requiere una serie de condiciones que posibilita el agrupamiento de los elementos, tal como señala Langacker (1987).
En cuanto a la sinonimia, el presente trabajo adopta la postura de Zapico y Vivas (2015): esta relación semántica existe cuando los elementos comparten una cantidad importante de los atributos, aunque no necesariamente todo, como exponen en esta cita:
…cuando una persona estima la similitud semántica entre dos o más ideas puede establecer entre ellas diferentes tipos de relaciones semánticas. Su proximidad puede estar dada porque ambos conceptos presentan una relación inferencial entre sí, de modo que evocar un concepto supone la propagación de la activación hacia otro concepto con el que se halla vinculado lógicamente. Pero también ambos conceptos pueden compartir numerosos atributos por medio de los cuales se establezcan relaciones no necesariamente lógicas (p. 202).
Con lo anterior, la sinonimia se entiende como un fenómeno de gradualidad. Según esta autoría, la relación de sinonimia puede ser muy compleja a pesar de la simplicidad de su definición inicial, pues otros factores pueden incidir en la identificación de la proximidad de los elementos: por ejemplo, una comunidad lingüística podría expresar mayor riqueza semántica al describir objetos concretos, o podrían suceder variaciones en las tendencias de agrupamiento de las piezas léxicas de acuerdo con la categoría gramatical.
En relación con la antonimia, el análisis propuesto concuerda con el trabajo de Greenwood y Flanigan (2007): los elementos léxicos pueden colocarse en una línea o continuo, ordenados según su proximidad semántica; en consecuencia, dos palabras que se encuentran en los extremos tienen mayor probabilidad de utilizarse como antónimos. De esta forma, la gradación de las relaciones semánticas permite englobar subcategorizaciones de la oposición, como el caso de la tipología sustentada por Escandell (2007) y Kroeger (2018), encontrada más adelante en este mismo documento. De igual manera, en concordancia con Lyons (1977), las oposiciones léxicas pueden organizarse en una dimensión de similitud, por tanto, es posible enmarcar las relaciones semánticas de antonimia y sinonimia de manera coherente e integral.
Sobre las relaciones temáticas, de recurrencia y de englobamiento, debe señalarse que la identificación y el descubrimiento de tópicos son objetivos frecuentes en la cotidianidad (May et al., 2015). En general, la categorización es una operación mental que consiste en el agrupamiento de objetos de las distintas actividades del quehacer humano (Kleiber, 1995): se clasifican, ordenan y agrupan acciones, pensamientos, percepciones y palabras. En la misma línea, debe entenderse la conformación de conjuntos desde una perspectiva psicolingüística, es decir, como una actividad en la que la población hablante tiene una participación activa desde su experiencia (Reeves et al., 1999).
Método
Enfoque metodológico
Para el desarrollo de este estudio se siguió un enfoque mixto que combinó e integró el análisis cualitativo con el cuantitativo. El primero se aplicó en la construcción y el juzgamiento del corpus para definir las categorías, los criterios y las tipologías de resolución para cada ítem. El análisis cuantitativo se implementó en la codificación e interpretación de los datos obtenidos de las encuestas aplicadas.
El instrumento se aplicó a una muestra no aleatoria, compuesta por personas en su mayoría con educación media costarricense completa y con intenciones de ingresar a la universidad pública. A partir de la encuesta se describen los patrones de respuesta sobre ítems que pretenden medir léxico y las distintas relaciones que pueden establecerse entre palabras.
Variables, muestra y muestreo
Una vez revisados y categorizados los ítems por cuatro personas investigadoras, en función de juezas internas y dos juezas externas al equipo de investigación, en setiembre de 2020 se aplicó una encuesta a 3864 personas aspirantes, candidatas a realizar la PAA para ingresar a la Universidad de Costa Rica en el 2021, cuyas edades comprenden de los 17 a los 21 años. De esta población, un 60,68 % indicó que su género es femenino (2345), un 37,42 %, masculino (1446) y un 1,89 % (73), otro. La distribución por región del país fue de un 76,96 % de la zona central del país, incluida la capital (San José), un 6,8 % de la zona del Pacífico Norte, un 8,42 % de la zona del Pacífico Central y Sur, y un 7,82 % de la zona del Caribe.
Instrumentos de obtención de información
El instrumento constó de 21 ítems, 7 por cada tipología de relación léxica (antonimia, sinonimia y temática). El instrumento estuvo disponible en un formato digital, a través de un formulario, durante 2 semanas para que el público meta lo respondiera. Cada ítem se desplegó de manera independiente con un solo intento de respuesta y la persona aspirante no tuvo restricción de tiempo para resolverlo. Una vez concluida la aplicación del instrumento se extrajo la información en una hoja de Excel y se procedió con el análisis cualitativo.
En las relaciones de antonimia, se buscaba que la persona eligiera la opción que establece una oposición a la palabra presentada en el encabezado del ítem. Las preguntas que proponían este tipo de relaciones incluían los ítems del 1 al 7. A continuación, se presenta un ejemplo de los ítems de esta categoría:
¿Cuál de las siguientes opciones se opone a la palabra escueto?
Amplio.
Extenso.
Detallado.
Redundante.
En las relaciones de sinonimia, se buscaba que la población participante eligiera la opción que estableciera un intercambio con una palabra con el mismo significado. Las preguntas que proponían este tipo de relaciones incluían los ítems del 8 al 14. A continuación, se presenta un ejemplo del formato de pregunta compartido en todos los ítems:
¿Cuál de las siguientes opciones puede intercambiarse por la palabra interpelar?
Alzarse.
Discutir.
Averiguar.
Confrontar.
En las relaciones de temática, se buscaba que la persona participante eligiera la opción que estableciera algún grado de relación. Las preguntas que proponían este tipo de relaciones incluían los ítems del 15 al 21, tal y como se evidencia en el siguiente ejemplo:
Trabajo de campo y análisis de datos
El desarrollo de esta investigación contó con cuatro fases. En la primera, se procedió con la construcción de los ítems para el diseño del instrumento. Para este fin, cada persona constructora propuso una lista de palabras extraídas de un corpus para incluirlas en el estudio. Luego, se seleccionaron algunas entradas con base en la frecuencia de aparición y la posición en el ranking dentro del corpus. Posteriormente, se construyeron los ítems con cuatro opciones de respuesta entre las que se incluía la clave. Por último, se elaboró una teorización para el establecimiento de una tipología de criterios de selección.
En la segunda fase del estudio se validó el contenido de los ítems a partir del juicio de personas expertas con el fin de confirmar la clave de cada ítem, los criterios teóricos para la clasificación en las categorías denominadas como relaciones de antonimia, sinonimia y temática. Asimismo, para cada tipo de relación se establecieron los criterios y una tipología teórica pues
para establecer un posible universo de reactivos se requiere tener una adecuada conceptualización y operacionalización del constructo, es decir, el investigador debe especificar previamente las dimensiones a medir y sus indicadores, a partir de los cuales se realizarán los ítems (Escobar y Cuervo, 2008, p. 28)
Además, se procuró que las opciones de respuesta discriminaran entre las personas evaluadas y tuvieran una dificultad adecuada que luego sería analizada con los datos recogidos con el instrumento.
La tercera fase consistió en la incorporación de dos personas expertas externas a quienes se les solicitó: resolver los ítems; establecer como alta, media o baja la dificultad de los ítems; definir el tipo de relación léxica (de antonimia, sinonimia y temática) que presenta cada ítem; y, de considerarlo pertinente, realizar observaciones para mejorar cada componente en términos de redacción o sustitución de distractores.
La cuarta fase se concentró en el diseño y aplicación del instrumento a las personas participantes encuestadas para luego pasar a los análisis de la prueba y determinar la carga factorial de cada ítem, la dificultad (Dif TRI), la discriminación (Dis TRI), la curva de información y el análisis de distractores.
Los análisis estadísticos se realizaron con el programa Stata 15 y paquetes del lenguaje R para detallar la precisión de la medida. El análisis factorial exploratorio permite determinar la carga factorial de cada ítem (que oscila entre -1 y 1) en relación con su representación en el constructo cuya variable latente se denomina dominio léxico.
Consideraciones éticas asociadas al desarrollo del estudio
Debido a que este estudio estuvo dirigido a personas, en algunos casos menores de edad, se solicitó el consentimiento informado en el que se indicó la naturaleza del estudio, las personas responsables del proyecto, los riesgos y beneficios, la voluntariedad y la confidencialidad de la participación, junto a la información de contacto.
Análisis de resultados
En seguida, se presentan los resultados de la aplicación del instrumento según cada tipo de relación semántica.
Relaciones de antonimia
Tabla 1 Relación de antonimia
| Número de ítem | Carga factorial | Dif TRI | Dis TRI |
| 1 | 0,48 | -0,3927 | 0,5625 |
| 2 | 0,41 | 0,5673 | 0,4287 |
| 3 | 0,41 | -0,2196 | 0,4304 |
| 4 | 0,39 | 1,1828 | 0,4305 |
| 5 | 0,34 | -1,1019 | 0,3303 |
| 6 | 0,43 | -1,1816 | 0,4874 |
| 7 | 0,32 | -1,9290 | 0,3284 |
Fuente: Elaboración propia (2022).
En las relaciones de antonimia se buscaba que la persona eligiera la opción que establece una oposición a la palabra presentada en el encabezado del ítem. En la Tabla 1 se observan los datos generales de la categoría de antonimia. Además del número del ítem, se presenta la carga factorial, la dificultad TRI y la discriminación TRI. La carga factorial se refiere al peso del constructo que se desea medir. La carga factorial es importante, pues indica si el ítem representa o no el constructo. Se considera que una carga factorial es adecuada si supera el 0,30. La dificultad ''es la proporción de personas que responden correctamente un reactivo de una prueba'' (Ortiz-Romero et al., 2015, p. 29). Por su parte, la discriminación brinda información sobre los diferentes niveles de habilidad de las personas candidatas.
Los siete ítems que pertenecen a ella presentaron una carga factorial entre 0,32 y 0,48, lo cual refleja un peso adecuado para el constructo de dominio léxico. El modelo de dos parámetros de TRI muestra dificultades que oscilan entre 1,1829 y -1,9290. En cuanto al valor de la discriminación según TRI, los valores anduvieron entre 0,5626 y 0,3285: dos de los ítems de esta categoría no alcanzaron el mínimo recomendado (0,35).
Relación de sinonimia Relación de sinonimia
Tabla 2 Relación de sinonimia
| Número de ítem | Carga factorial | Dif TRI | Dis TRI |
| 8 | -0,05 | 1,8089 | -0,0472 |
| 9 | 0,43 | -0,8538 | 0,4821 |
| 10 | 0,12 | 1,4597 | 0,1012 |
| 11 | 0,45 | -0,374 | 0,5005 |
| 12 | 0,44 | 0,1871 | 0,4738 |
| 13 | 0,43 | -0,3907 | 0,4504 |
| 14 | -0,14 | -1,7269 | -0,1181 |
Fuente: Elaboración propia (2022).
En las relaciones de sinonimia se buscaba que el estudiantado eligiera la opción que estableciera algún grado de equivalencia entre los términos. Como se observa en el Tabla 2, se realizó un análisis de la estructura interna. Además, para la categoría de sinonimia, tres ítems no tienen cargas factoriales adecuadas para el constructo de dominio léxico: 8 (-0,05), 10 (0,12) y 14 (-0,14). En relación con el análisis de las dificultades, según el modelo de dos parámetros de TRI, el ítem de dificultad más alto fue el 8, con 1,8089. El más fácil fue el 14, con una dificultad negativa de -1,7269. Hubo 3 ítems que no cumplieron con el mínimo de 0,35 de discriminación, es decir, las condiciones de equidad se ven afectadas, pues los ítems podrían favorecer algún sexo o colegio.
Relaciones de temática
Tabla 3 Relación de temática
| Número de ítem | Carga factorial | Dif TRI | Dis TRI |
| 15 | 0,15 | -6,6189 | 0,2651 |
| 16 | 0,00 | 5,8215 | 0,0026 |
| 17 | 0,23 | 0,5600 | 0,2075 |
| 18 | 0,09 | 0,8305 | 0,0706 |
| 19 | 0,19 | 1,9227 | 0,1645 |
| 20 | 0,03 | 30,8796 | 0,0242 |
| 21 | 0,25 | -3,3316 | 0,2877 |
Fuente: Elaboración propia (2022).
En las relaciones de temática, se buscaba que la población participante eligiera la opción que estableciera algún grado de relación. Como se observa en el Tabla 3, según el análisis factorial, los ítems de temática mantuvieron una carga factorial muy baja para el constructo de dominio léxico en todos los 7 ítems. En congruencia con lo anterior, el modelo de dos parámetros de TRI presenta dificultades muy diferenciadas entre sí. De los 7 ítems solo 3 tuvieron dificultades aceptables (0,5601, 0,8305, 1,9228), mientras que los otros 4 tuvieron un comportamiento fuera de los parámetros. Las discriminaciones tampoco alcanzaron un mínimo del 0,35 recomendado.
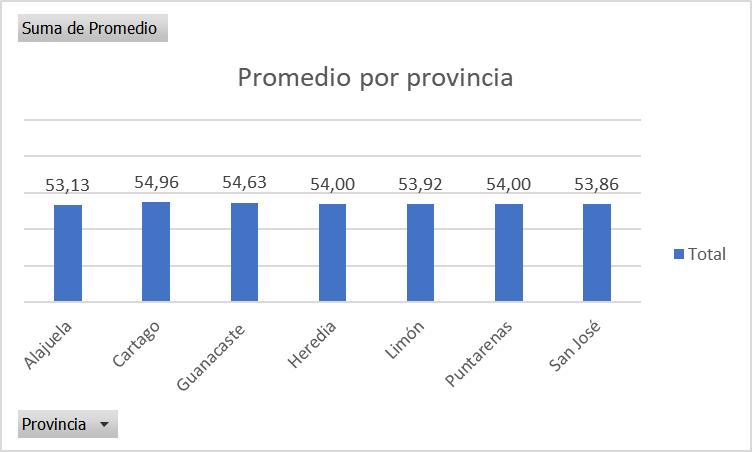
Al contrastar el promedio de aciertos por provincia, como se muestra en el Figura 1, no hubo diferencia significativa entre ellas. Todos los valores oscilan entre 54,96 y 53,13. Además, el promedio por género es de 53,96 para las mujeres y para los hombres 53,97; es decir, tampoco hubo diferencia en este resultado.
En los ítems de las tres relaciones semánticas, las dificultades oscilaron según el diseño inicial del instrumento y las opciones de respuesta permitieron diferenciar a las personas evaluadas de acuerdo con sus habilidades en el dominio léxico. Ahora bien, en los ítems con cargas factoriales bajas, no se definió una tendencia clara en la elección de la respuesta correcta; por ejemplo, en dos ítems de sinonimia, no fue posible determinar cuál de las opciones presenta el sinónimo más próximo de la palabra dada en la pregunta del ítem.
Más aún, en el conjunto de los ítems de la categoría de temática no es posible identificar un único patrón de respuestas por nivel de habilidad de las personas evaluadas o su pertenencia a grupo sociodemográfico en particular: la proximidad entre la palabra de la pregunta y un término específico en las opciones de respuesta depende de la organización o experiencia, de las personas evaluadas, como afirma Entwistle (1978). En este caso, una solución posible, y que debe probarse en estudios futuros, es la medición de las reducciones temáticas mediante la identificación de hipónimos e hiperónimos; así, en lugar de emplear palabras aisladas, se utilizarían conjuntos de términos que se contextualizan mutuamente.
Conclusiones
Como se ha mencionado, el objetivo de este trabajo es generar evidencias sobre el dominio léxico en el contexto de relaciones semánticas de sinonimia, antonimia y temática en personas aspirantes al ingreso a la universidad. A su vez, esta generación de evidencias es un mecanismo para garantizar la validez de los procesos de razonamiento medidos en la Prueba de Aptitud Académica de la Universidad de Costa Rica y lograr una menor incidencia posible de factores socioculturales.
Respecto a este objetivo puede señalarse como principales hallazgos el hecho de que el léxico se puede medir en tres categorías que representan relaciones amplias y comunes en el contexto de la lectura. La antonimia como parte del razonamiento inverso, la sinonimia como parte de una relación de semejanza y la de temática como un vínculo semántico mucho más amplio entre unas palabras con otras.
La habilidad para identificar relaciones semánticas de antonimia, sinonimia y temática incide en el desempeño de las personas evaluadas al resolver ítems de las categorías de oponer, parafrasear y reducir, especialmente si la resolución de estos ítems depende en cierta medida del nivel léxico (Brizuela et al., 2016). Por tanto, es importante comprender el dominio léxico ligado a estas relaciones semánticas en sí, libres del contexto, para tener certeza de que no se afecta la medición de las habilidades generales de razonamiento o para encontrar los mecanismos que eviten factores causantes de varianza irrelevante al constructo.
Ahora bien, pese a que el léxico es medible en estas tres dimensiones, al comparar los datos obtenidos según cada categoría, los resultados apuntan a un desempeño desigual de las categorías en el instrumento. La categoría de antonimia fue la que mantuvo cargas factoriales más estables y con valores más altos. En el caso de la categoría de sinonimia, esta presentó una mayor oscilación: la carga factorial, la dificultad y la discriminación de dos ítems no fueron las deseadas. En el caso de la categoría de temática, ninguno de los ítems presentó una carga factorial adecuada. Lo mismo sucedió con la discriminación: ningún ítem alcanzó el parámetro mínimo adecuado. Por lo tanto, los resultados demuestran que es necesario ajustar la forma de medir el dominio léxico en esta relación semántica.
Concretamente sobre la categoría de temática, se plantean algunas modificaciones para las siguientes aplicaciones del instrumento. En primer lugar, se debe reformular la pregunta planteada para la categoría de temática, pues la actual es muy amplia y no ofrece un contexto particular. En segundo lugar, en los ítems de temática, en diversas ocasiones los distractores y la clave compartían un significado muy cercano entre sí, lo que pudo ocasionar la vacilación en la escogencia de opciones. En tercer lugar, los ítems de temática se colocaron al final del instrumento, posición que favorece que estos ítems fueran dejados en blanco o contestados al azar, debido al cansancio o falta de interés en ese punto por parte de las personas que llenaron el instrumento.
Uno de los principales intereses de la investigación fue analizar si había diferencias en el dominio léxico asociado a las relaciones semánticas estudiadas por parte de los distintos grupos que conforman la población; específicamente, se decidió examinar los resultados por sexo, tipo de colegio y provincia de residencia. En consecuencia, se halló que no existen diferencias en su comportamiento respecto de la exposición léxica: tanto hombres como mujeres, de colegios públicos y privados de diferentes regiones del país tuvieron un comportamiento similar. Esto también evidencia que los instrumentos de dominio léxico y relaciones semánticas pueden utilizarse para validar el vocabulario que se utiliza en las pruebas de habilidades generales de razonamiento.
En relación con las limitaciones vinculadas con el instrumento, habría sido deseable incorporar mayor cantidad de ítems, con el fin de aumentar la confiabilidad del instrumento. Sin embargo, se optó finalmente por un total de 21, dado que las personas participantes brindaron su tiempo sin que mediara recompensa alguna, más allá de la posibilidad de poner en práctica su habilidad léxica. Queda, por lo tanto, pendiente la búsqueda de una población que permita aplicaciones de instrumentos más extensos.
Asimismo, en cuanto a las limitaciones del instrumento para medir dominio léxico y relaciones semánticas, especialmente en relación con los ítems con cargas factoriales bajas, es posible profundizar en las razones de estos resultados. Así, una causa probable está asociada a la validez sociocultural del dominio léxico como constructo: el vocabulario surge de las experiencias comunes en la organización y en la historia, como lo propone Entwistle (1978) ''Aparte del interés teórico del español en América, este constituye un registro, además, de apasionantes experiencias sociales e históricas. En el español se encuentra grabada la experiencia de intercambios…'' (p. 277). En consecuencia, es factible evaluar las relaciones semánticas mediante léxico con un contexto proposicional nulo o muy reducido; sin embargo, también cabe la posibilidad de que esas relaciones concuerden con las experiencias propias de diferentes grupos sociales más complejos que los contemplados inicialmente en el instrumento; por ejemplo, para un grupo de personas específico, el adjetivo orgánico es más próximo al sustantivo fertilizante, mientras que para otro grupo es un calificativo más propio de producto.
Esta limitación está patente al evaluar relaciones de sinonimia, antonimia y temática, y demuestra una diferencia importante entre la medición del dominio léxico y la medición de habilidades generales de razonamiento: los ítems de la primera están enfocados en el contenido lingüístico; en cambio, los ítems de la segunda están claramente focalizados sobre una tarea categorizada y los textos se emplean solamente como contexto. Ahora bien, los instrumentos para la medición del dominio léxico y relaciones semánticas son de suma utilidad para validar el vocabulario empleado en los ítems de las pruebas de razonamiento y, de esta forma, reducir la probabilidad de provocar sesgos asociados a factores sociolingüísticos; especialmente si se toma en cuenta que, por ejemplo, una palabra de uso poco frecuente en una opción de respuesta podría provocar que las personas evaluadas no seleccionen esa opción en concreto (Brizuela y Montero, 2013).

