









 Inglés (pdf)
Inglés (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
En las finanzas, predecir el cambio de precio de los valores es un tema que ha concentrado el interés de muchos actores; analistas, inversionistas individuales e institucionales, académicos, aficionados, entre otros. Sin embargo, hasta hoy se han adoptado distintos modelos o procedimientos que buscan la certeza total en los comportamientos accionarios, difícilmente encontrando una solución para predecir las situaciones futuras e inciertas.
En esta investigación se construye y se aplica un Modelo Autorregresivo Integrado de Promedio Móvil (ARIMA), al cual se agregan variables exógenas y se le adapta un método de fuerza bruta operacional (Parisi, 2015; Parisi, Améstica y Chileno, 2016), que permitirían construir infinitos escenarios aleatorios, encontrando un coeficiente sintético después de alcanzar la máxima capacidad de trabajo de un ordenador en ambiente Excel, con el objetivo de predecir los cambios en los signos del precio de un activo financiero y que, para el caso de este estudio, se circunscribe al comportamiento del precio del petróleo y de las acciones de tres empresas representativas del sector, como son Exxon Mobil, Gazprom y Rosneft, las cuales se tranzan en el mayor mercado de valores del mundo, como es el New York Stock Exchange (NYSE). Es bien sabido que analizar el sector del petróleo es de gran importancia por su contribución a la economía mundial y su carácter estratégico en todo el proceso de globalización (Haro del Rosario, Saraite, Caba y Gálvez, 2016).
Han sido muchos los autores que han realizado una revisión de los métodos para predecir índices bursátiles, que van desde aquellos que logran capturar las características lineales, pasando por los que se enfocan en las características no lineales y, finalmente, métodos híbridos (García, Jalal, Garzón y López, 2013); sin embargo, aquellos menos tradicionales han sido menos citados. Asimismo, cada vez más, hallazgos recientes en finanzas indican la necesidad de una colaboración interdisciplinaria de profesionales de economía, matemáticas, física, econometría, psicología, neurociencia, entre otros (Hernández, 2010), especialmente en las decisiones financieras.
El concepto de técnica de fuerza bruta en mercados financieros fue acuñado hace poco tiempo (Parisi, 2015; Parisi, Améstica y Chileno, 2016) como método predictor, se puede considerar una continuación y desarrollo lógico a partir de investigaciones anteriores basadas en autores como: Arango, Velásquez y Franco (2013), quienes utilizan técnicas de lógica difusa para predecir índices accionarios; Atsalakis (2016), quien innova en un modelo que busca predecir los precios del carbono usando inteligencia computacional; y Fan, Wang y Li (2016), quienes establecen un modelo de red de percepción multicapa para hacer predicciones a corto plazo después de identificar las características caóticas del precio del carbón. Asimismo, encontramos a Pierdzioch, Risse y Rohloff (2015), quienes utilizan métodos artificiales para la predicción en la fluctuación del precio del oro, de manera muy parecida a los investigadores Shafiee y Topal (2010), quienes anteriormente trataron de prever el precio del oro. Según Parisi (2015), las técnicas antes mencionadas cada vez han ido mejorando en su capacidad predictiva gracias a los avances computacionales en velocidad y tratamiento de datos, lo cual no justifica buscar los llamados “atajos” y se hace atingente la no utilización de algoritmos en primera diferencia, sino que es mejor usar directamente fuerza bruta en primera diferencia, es decir, las variables alcanzarían valores cero si es que el coeficiente generado a través de números aleatorios llega a valor del coeficiente cero.
Tal como se señaló anteriormente, los comportamientos en el mercado no son 100% impredecibles, aunque en cierta medida sí lo son, alrededor de un 60% y 70%, en la variación de signo (Fama y French, 1992), y según lo evidenciado en trabajos posteriores para algunos mercados (Parisi, Parisi y Díaz, 2006).
Es en este contexto que este estudio explica, en una primera parte, los modelos actuales según distintos autores contemporáneos, que buscan la mejor predicción de variaciones de precios; luego se establecen los objetivos y alcances metodológicos por uso de la técnica de fuerza bruta de estudio para el caso del sector petrolero; se concluye con los resultados y conclusiones finales.
Revisión de literatura
El estudio se ha limitado a caracterizar los modelos de predicción de precios en base a inteligencia artificial, los cuales tienen adeptos y detractores, y están en constante revisión y desarrollo.
Algoritmos genéticos
Los algoritmos genéticos consisten en una función matemática o una rutina que simula el proceso evolutivo de las especies, teniendo como objetivo encontrar soluciones a problemas específicos de maximización o minimización (Holland, 1975). Así, el algoritmo genético recibe como entrada una generación de posibles soluciones para el problema que se trate, y arroja como salida los especímenes más aptos (es decir, las mejores soluciones) para que se apareen y generen descendientes, los que deberían tener mejores características que las generaciones anteriores.
Los algoritmos genéticos trabajan con códigos que representan a cada una de las posibles soluciones al problema. Por ello, es necesario establecer una codificación para todo el rango de soluciones antes de comenzar a utilizar el algoritmo. Al respecto, Davis (1994) señala que la codificación más utilizada es la representación de las soluciones por medio de cadenas binarias (conjuntos de ceros y unos).
Según Bauer (1994), este método puede ser utilizado fácilmente en aplicaciones financieras. Davis (1994) muestra una aplicación de algoritmos genéticos en la calificación de créditos bancarios que resultan mejor que otros métodos, como las redes neuronales, debido a la transparencia de los resultados obtenidos. Kingdon y Feldman (1995) usaron algoritmos genéticos para hallar reglas que pronosticaran la bancarrota de las empresas, estableciendo relaciones entre las distintas razones financieras. Bauer (1994) utilizó algoritmos genéticos para desarrollar técnicas de transacción que indicaran la asignación mensual de montos de inversión en dólares y marcos; Pereira (1996) los utilizó para encontrar los valores óptimos de los parámetros usados por tres reglas de transacción distintas para el tipo de cambio de dólar estadounidense/dólar australiano; los parámetros obtenidos mostraron resultados intramuestrales positivos, los cuales disminuyeron al aplicar las reglas fuera de la muestra, aun cuando continuaron siendo rentables.
En tanto, Allen y Karjalainen (1999) usaron algoritmos genéticos para aprender reglas de transacción para el índice S&P 500 y emplearlas como un criterio de análisis técnico y, una vez cubiertos los costos de transacción, encontraron que el exceso de rendimiento calculado sobre una estrategia buy and hold durante el periodo de prueba extramuestral no era congruente. Kim y Han (2000) mostraron que los algoritmos genéticos pueden ser usados para reducir la complejidad y eliminar factores irrelevantes, lo que resultó mejor que los métodos tradicionales para predecir un índice de precios accionario. Por otra parte, Feldman y Treleaven (1994) señalaron que la mayor desventaja de los algoritmos genéticos es la dificultad que presentan para escoger una técnica de codificación manejable y para determinar el tipo de selección y las probabilidades de los operadores genéticos, ya que no hay reglas fijas en esta materia. En investigaciones recientes de predicción de precios de granos en China, se ha utilizado un modelo estocástico híbrido optimizado por algoritmo genético con buenos resultados predictivos (Zhao, Zhang, Shi y He, 2017).
Modelos ARIMA
Por sus siglas en inglés Auto Regresive Integrated Moving Average (ARIMA). Es un modelo econométrico propuesto por los investigadores Box y Jenkins en los años 70 para predecir series de tiempo. Popularmente es conocido como metodología Box-Jenkins aunque también es conocido como metodología o modelos ARIMA. Consta de tres componentes:
Proceso Autorregresivo (AR): se define como modelo autorregresivo si la variable endógena de un periodo t es explicada por sí misma en las observaciones o datos pasados, multiplicados por un coeficiente que le da un peso específico a la información pasada.
Proceso Integrado (I): se refiere al estado de la variable, es decir, si se va a trabajar sobre el valor sin modificación sobre su primera o segunda diferencia, entendiendo la primera diferencia simplemente como la primera variación de la serie en estudio. Por ejemplo, una serie de precios se entiende como integración en cero. Es decir, se trabajará con la variable pura, lo cual en términos generales no es recomendable dado que tienen tendencia y no se pueden modelar en esas condiciones. Un grado de integración 2 significa que el modelo se construirá sobre la variación de la serie en estudio, o sea, no se modela el precio sino la variación del precio, pero sí se obtiene un modelo para la variación de precios, se le suma el precio anterior y se obtiene la proyección de precios, es decir, en niveles ARIMA y cero.
Proceso de Media Móvil (MA): Es aquel que explica el valor de una determinada variable en un periodo t en función de un término independiente y una sucesión de errores correspondientes a periodos precedentes, ponderados convenientemente.
A continuación se muestra la simbología y componentes de un modelo ARIMA:
ARIMA (p, d, q)
P = AR () autorregresivo como variable explicativa
D= Integrado
Q= Error como variable explicativa (media móvil de los errores)
Autómatas celulares
Los autómatas celulares son un mecanismo artificial que trata de imitar las propiedades o sistemas similares a la de los seres vivos a través de la interacción entre individuos simples de dichos sistemas. Se basa en un panel con un conjunto finito de células o autómatas simples, donde cada una de ellas puede adoptar un estado posible de un conjunto finito de estados, determinado por su estado anterior y el estado de las células vecinas. Es así, como los estados de las células van evolucionando en tiempo discreto, de acuerdo a una regla local o un conjunto de reglas, las cuales pueden ser basadas en el estado anterior de la célula, o en el de sus vecinos. En cada período, la regla se le aplica al conjunto de células, entregando una nueva generación de autómatas (Malamud y Turcotte, 2000).
Cada autómata simple genera una salida a partir de varias entradas, modificando su estado de acuerdo con una función de transición a través de generaciones. Por lo tanto, en un autómata celular, el estado de una célula en una generación determinada depende únicamente de su propio estado y el de las células vecinas de la generación anterior.
Estos son usados para modelar sistemas complejos de cualquier índole, por lo que no sorprende que en las finanzas y la economía los expertos hayan hecho lo mismo. Varios especialistas han hecho investigaciones y han utilizado a los autómatas celulares para predecir los cambios en los signos de los precios de las acciones y los resultados han sido positivos.
Redes neuronales
De acuerdo con Martin del Brio y Sanz (2001), las redes neuronales artificiales "son sistemas de procesamiento que copian esquemáticamente la estructura neuronal del cerebro para tratar de reproducir sus capacidades" (p. 387). En consecuencia, son una clase de modelos no lineales flexibles, que se caracterizan por ser sistemas paralelos, distribuidos y adaptativos, todo lo cual se traduce en un mejor rendimiento y en una mayor velocidad de procesamiento. Las redes neuronales pueden entenderse como modelos multiecuacionales o multietapas, en que el output de unas constituye el input de otras. En el caso de las redes multicapas, existen etapas en las cuales las ecuaciones operan en forma paralela. Los modelos de redes neuronales, al igual que, por ejemplo, los modelos de suavizamiento exponencial y de análisis de regresión, utilizan inputs para generar un output en la forma de una proyección. La diferencia radica en que las redes neuronales incorporan inteligencia artificial en el proceso que conecta los inputs con los outputs (Kuo y Reitsch, 1995).
Herbrich, Keilbach, Graepel, Bollmann-Sdorra y Obermayer (2000) señalan que la característica más importante de las redes neuronales es su capacidad para aprender dependencias basadas en un número finito de observaciones, donde el término aprendizaje significa que el conocimiento adquirido a partir de la muestra de observaciones históricas puede ser empleado para proporcionar una respuesta correcta ante datos no utilizados en el entrenamiento de la red y, por lo tanto, no conocidos por esta. La literatura sugiere que las redes neuronales poseen varias ventajas potenciales sobre los métodos estadísticos tradicionales, destacándose el que estas pueden ser aproximadoras de funciones universales, aún para funciones no lineales (Homik, Stinchcombe y White, 1989), lo que significa que ellas pueden aproximar automáticamente cualquier forma funcional (lineal o no lineal) que mejor caracterice los datos, permitiéndole a la red extraer más señales a partir de formas funcionales subyacentes complejas (Hill, Marquez, O'Connor y Remus, 1994). Cabe señalar que algunos investigadores han encontrado que, en general, los mercados financieros se comportan de una forma no lineal, cuestión que ha favorecido el empleo de modelos de redes neuronales ya que, como se dijo anteriormente, estas han evidenciado un buen desempeño en modelamientos no lineales.
Es posible distinguir al menos dos importantes aplicaciones de las redes neuronales en las áreas de economía y finanzas: primero, la clasificación de agentes económicos, por ejemplo, para obtener una estimación de la probabilidad de quiebra (Wilson y Sharda, 1994); segundo, la predicción de series de tiempo (Tang, de Almeida y Fishwick, 1991). Cabe destacar que el propósito de un modelo de predicción es capturar patrones de comportamiento en datos multivariados que distingan varios resultados, cosa que es bien realizada por los modelos no paramétricos de redes neuronales, los cuales han sido desarrollados para predecir valores de índices bursátiles y de activos individuales, por lo que se ha situado la mayoría de las primeras investigaciones y aplicaciones en mercados establecidos en Estados Unidos, Gran Bretaña y Japón. Dichos modelos han sido empleados para predecir el nivel o el signo de los retornos de índices bursátiles, entre otras aplicaciones relacionadas a la toma de decisiones en las áreas de finanzas e inversión.
La técnica de la “Fuerza Bruta”
La técnica fuerza bruta (Parisi, 2015; Parisi, Améstica y Chileno, 2016) utiliza la capacidad de las computadoras para poder encontrar la mejor solución a un problema de optimización. Esta técnica aplicada a los modelos ARIMA simula la inteligencia humana, puesto que genera escenarios diferentes en los cuales cada uno de ellos brinda una solución única al problema. La función de este modelo ARIMA con fuerza bruta es comparar los nuevos escenarios generados con los anteriores y elegir el mejor. Dicho de otra manera, recuerda al igual que un humano el comportamiento que tuvo para darle una mejor solución a determinado problema, y si ese comportamiento solucionó el problema, cada vez que suceda un escenario parecido el humano utilizará dicho comportamiento. De la misma manera, ARIMA con fuerza bruta utiliza el mejor modelo.
En los modelos ARIMA, que son modelos de regresión, la técnica fuerza bruta permite generar infinitos coeficientes de un universo establecido, para darle un peso a cada variable establecida y evaluada en el modelo. Incluso se puede afirmar que al usar fuerza bruta se puede contemplar todos los escenarios del universo establecido, lo cual sería una mejora a los algoritmos genéticos, los cuales sólo buscan alrededor de un punto en el universo que ofrece una solución de primera instancia óptima.
Como afirma Durán (2006), la fuerza bruta consiste en enlistar todos los casos y para cada uno calcular la solución, identificando de este modo el caso que ofrezca la mejor solución. Asimismo, Riveros (2015), en un estudio para encontrar la solución óptima al problema del camino más corto para una empresa de logística, comenta que la solución más directa es con fuerza bruta, es decir, evaluar todas las posibles combinaciones (de recorridos) y quedarse con el trayecto que utiliza una menor distancia.
Los métodos mencionados anteriormente sirven para resolver los mismos problemas de optimización simulando la inteligencia humana. Muchos científicos y expertos en ciencias sociales a lo largo de los años han estado tratando de desarrollar cada vez mejores métodos para la solución de problemas. Lo curioso es que el primer método empleado para resolver problemas es el conocido como “fuerza bruta”. Desde tiempos antiguos el hombre utiliza la fuerza bruta para resolver los problemas. Pero ¿por qué se crearon nuevos métodos si con este se podía? Sencillo, los problemas cada vez alcanzaron dimensiones mayores y complejas, lo cual hacía prominente crear métodos que demoraran menos en resolver un problema.
Como se ha dicho, la fuerza bruta lo que hace es probar una a una las diferentes condiciones y características de un sistema para resolver el problema. Una vez que se encuentra la solución, se queda con dicho sistema. Se dejó de usar fuerza bruta puesto que no existía la capacidad para resolver problemas que requerían la evaluación de una cantidad de variables considerada demasiado grande. Sin embargo, hoy en día, la tecnología ha vuelto a superar los problemas, y cualquier persona puede contar con un computador con recursos altamente efectivos capaces de procesar información mucho más rápido que aquellas computadoras diez años atrás. Por lo tanto, ahora es prudente e incluso más eficaz volver a utilizar la técnica fuerza bruta utilizando la capacidad de una computadora de alta tecnología.
Metodología
Tipo de investigación y diseño
Se ha establecido como una investigación de carácter exploratoria que busca validar, a partir de un modelo ARIMA, la incorporación de la técnica de fuerza bruta (Parisi, 2015; Parisi, Améstica y Chileno, 2016) para obtener un porcentaje de predicción de signo significativo respecto a otros modelos en el precio del petróleo, y también es correlacional puesto que utiliza la relación entre el precio pasado como base de proyección del precio futuro de un valor, necesariamente determinando la relación en específico.
La población para este estudio son los precios del petroleofíca y comercialmente como América del Norte y resume el comportamiento del mercado.
Los modelos ARIMA usados para predecir el signo de las fluctuaciones semanales del precio del petróleo y las acciones de las empresas evaluadas se presentan en las ecuaciones 1 a 4 en el siguiente orden: petróleo y los nemotécnicos de Exxon, Gazprom y Rosneft Oil:
∆P = α1 • ∆P t-1 + ... + αAR • ∆Pt-AR + β1 • E t-1 + ... +
βMAEt-MA + θ1 • ∆DJIt-1+ ... +θx • ∆DJIt-x + Et (1)
∆XOM = α1 • ∆XOM t-1 + ... +αAR • ∆XOM t-AR + β 1 • Et-1 + ...
+βMAEt-MA + θ1 • ∆DJI t-1 + ... + θx • ∆DJI t-x +E t (2)
La población para este estudio son los precios del petróleo y de las acciones de empresas petroleras que transan en el New York Stock Exchange (NYSE), a partir de una muestra de precios de cierre semanales1 para el petróleo, obtenido de la base de datos de precios históricos del portal web es.investing.com., y las acciones de las empresas Exxon Mobil, Gazprom y Rosneft Oil Company, obtenidos de la base de datos de precios históricos del portal web yahoo.com, sección finanzas, correspondiente al periodo del 4 de febrero de 2011 al 4 de febrero del 2016. Por la naturaleza de este estudio se utilizó la recopilación documental o datos secundarios, que implica la revisión de documentos, registros públicos y archivos físicos o electrónicos (Hernández, 2010), utilizando el nemotécnico de cada acción: Exxon Mobil (nemotécnico XOM); Gazprom (nemotécnico GAZP.ME) y Rosneft Oil Company (nemotécnico ROSN.ME), que da un total de 262 observaciones por variable (véase ejemplo en Anexo 1, Anexo 2, Anexo 3, Anexo 4 y Anexo 5).
∆GAZP.ME = α1
∆GAZP.ME
t-1
+ ... +αAR
∆GAZP.ME
t-AR +
Análisis estadístico de datos
Para efectos de evaluar el poder predictivo para frecuencias semanales, los modelos ARIMA utilizados son modelos de series de tiempo que expresan el comportamiento de una variable en función de sus valores rezagados, de variables exógenas rezagadas y de los rezagos de los residuos (errores) del modelo. La variable exógena incluida es el DJI2, considerada un indicador líder de lo que ocurre en los mercados bursátiles internacionales, sobre todo en una región integrada geográfica y comercialmente como América del Norte y resume el comportamiento del mercado.
β1 • Et-1 + ... + βMA Et-MA+θ1 • ∆DJIt-1+ ... +θx • ∆DJIt-x+Et (3)
∆ROSN.ME = α1 • ∆ROSN.MEt-1+ ... + αAR • ∆ROSN.MEt-AR +
β1 • Et-1+ ... +βMA Et-MA + θ1 • ∆DJIt-1+ ... + θx • ∆DJIt-x+Et (4)
En los que E t corresponde al término de error del modelo; P, XOM, GAZP.ME y ROSN.ME al precio del petróleo y a los nemotécnicos de las acciones de Exxon Mobil, Gazprom y Rosneft Oil respectivamente, que son las variables de la ecuación; y los subíndices AR, MA y X representan el máximo orden de rezagos de las variables independientes. Los coeficientes α, β y θ son los coeficientes mejor adaptados que, de acuerdo a su valor, le dan un peso determinado, por el modelo, a las variables. Estos últimos indican qué tanto afecta la variable incluida en el precio del valor en estudio.
Evaluación de la predicción
En concordancia con el punto anterior, se evaluó la calidad de cada modelo en función del porcentaje de predicción de signo alcanzado (PPS). La evaluación se realizó sobre la base de un conjunto extramuestral de 262 datos semana les, por medio de un proceso recursivo, correspondiente a la ventana de datos entre el 4 de febrero de 2011 y el 4 de febrero de 2016. Metodológicamente, la recursividad ha sido empleada para medir el desempeño de modelos de redes neuronales que buscan predecir periodos de recesión en los Estados Unidos (Qi, 2001; Estrella y N'lishkin, 1998) y para proyectar el signo de las variaciones de índices bursátiles Internacionales (Parisi, Parisi y Guerrero, 2003; Parisi, Parisi y Díaz, 2006).
Se utilizó la muestra total tanto para estimar los coeficientes α, β y θ de cada modelo por medio de la minimización de la suma del cuadrado de los residuos del modelo, como para evaluar la capacidad predictiva de los modelos. Para realizar esto se comparó el signo de la proyección con el signo de la variación observada en cada i-ésimo periodo, en el que i = 1, 2,…, m. Si los signos entre la proyección y el observado coinciden, entonces se puede señalar que aumenta la efectividad del modelo analizado y, en caso contrario, disminuye su capacidad predictiva.
Una vez proyectado el signo de la variación del precio para el periodo n+1, la variación observada correspondiente se incluye en la muestra de tamaño de n con objeto de reestimar los coeficientes del modelo, contando ahora con una observación más. Así, el mismo modelo pero con sus coeficientes recalculados es utilizado para realizar la proyección correspondiente al periodo n+2. Este procedimiento recursivo se efectuó una y otra vez hasta acabar con las observaciones del conjunto extramuestral. Finalmente, el PPS de cada modelo se calculó de la siguiente forma, según ecuación (5):
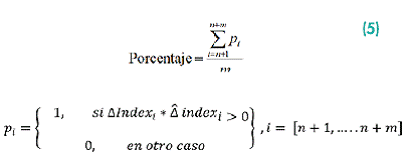
En la que Δ representa la variación observada,  la variación estimada, n=0 y m=262. De esta manera, los modelos ARIMA construidos con la técnica fuerza bruta fueron evaluados en función de su capacidad para predecir el signo de los movimientos de los precios del petróleo y las acciones. Además, en esta etapa se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), con objeto de medir la significancia estadística de la capacidad predictiva de cada uno de los modelos analizados.
la variación estimada, n=0 y m=262. De esta manera, los modelos ARIMA construidos con la técnica fuerza bruta fueron evaluados en función de su capacidad para predecir el signo de los movimientos de los precios del petróleo y las acciones. Además, en esta etapa se aplicó la prueba de acierto direccional de Pesaran y Timmermann (1992), con objeto de medir la significancia estadística de la capacidad predictiva de cada uno de los modelos analizados.
Luego, para analizar si la capacidad predictiva de los modelos se traduce en beneficios económicos, se calculó la rentabilidad acumulada que se habría obtenido si se hubiese comprado o vendido los valores en estudio siguiendo las recomendaciones de compra-venta del modelo de predicción. Para ello, la proyección de una variación positiva de los precios (un alza del mercado) fue interpretada como una señal de compra, mientras que el pronóstico de una variación negativa (una caída del mercado) fue interpretado como una señal de venta. Se supuso una inversión inicial de 100.000 dólares, y la rentabilidad acumulada se calculó sobre un conjunto extramuestral de 262 semanas. Al momento de calcular la rentabilidad, los costos de transacción no fueron considerados.
Por lo demás, con el objetivo de evitar el problema de data snooping3 (White, 2000) y de despejar las dudas respecto a si la capacidad predictiva se debe a la bondad del modelo, a las características de la muestra de observaciones a la que ha sido aplicado o sencillamente al factor suerte, se tomó el mejor modelo de proyección para cada valor (el de mayor PPS) y se lo evaluó sobre un total de 100 conjuntos extramuestrales de 262 datos de cierre semanales cada uno. Estos 100 conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original utilizando un proceso de block bootstrap4.
Resultados
Al desarrollar la estructura para el modelo ARIMA utilizando fuerza bruta, se utilizó la capacidad de un computador para realizar la evaluación de cada valor estudiado (Anexo 6). La función de los modelos ARIMA consistió en evaluar cada coeficiente para cada variable considerada que aumente el PPS, quedándose al final de la evaluación con el mejor modelo.
A continuación se presentan los mejores modelos ARIMA, de acuerdo con el PPS:
∆P=α 1 • ∆P t-1 + ... +α AR • ∆P t-AR +β 1 • E t-1 + ... +β MA E t-MA +θ 1
∆DJI t-1 + ... +θ x • ∆DJI t-x +E t (6)
∆XOM=α 1 • ∆XOM t-1 + ... +α AR • ∆XOM t-AR +β 1 • E t-1 + ...
+β MA E t-MA +θ 1 • ∆DJI t-1 + ... +θ x • ∆DJI t-x +E t (7)
En la Tabla 1 se muestra los mejores coeficientes α, β y θ obtenidos por el modelo que maximicen el PPS para cada valor estudiado.
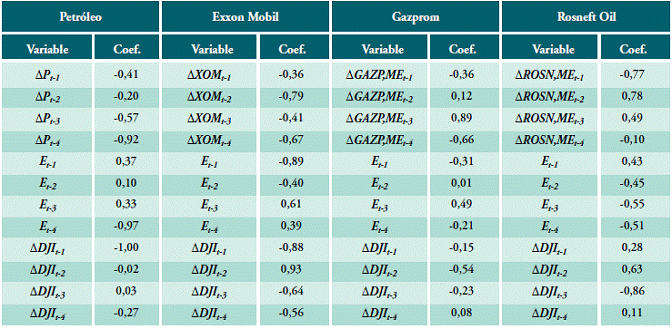
Posteriormente, en la Tabla 2, se muestran los mejores modelos producidos por ARIMA con fuerza bruta, los cuales arrojaron un PPS de un 62,5%, 63,8%, 64,09% y 62,93%, para los valores P, XOM, GAZP.ME Y ROSN.ME, respectivamente, y la rentabilidad acumulada que se obtiene al seguir las recomendaciones de compra y venta del modelo. Esta capacidad predictiva, estimada en un conjunto extramuestral de 262 datos semanales, resultó estadísticamente significativa en cada uno de los valores de acuerdo con la prueba de acierto direccional, comprobándose así la hipótesis de que sí existe capacidad predictiva en los modelos ARIMA con fuerza bruta para el caso del precio del petróleo.
∆GAZP.ME=α 1 • ∆GAZP.ME t-1 + ... +α AR
∆GAZP.ME t-AR + β 1
Tabla 2: Resumen de los resultados (porcentaje)
| Modelo | PPS | Rentabilidad acumulada |
|---|---|---|
| Petróleo | 62,55 | 44,21% |
| Exxon Mobil | 63,85 | 81,03% |
| Gazprom | 64,09 | 425,98% |
| Rosneft Oil | 62,93 | 129,53% |
Fuente: Elaboración propia.
Se pudo observar que la capacidad predictiva de los modelos se tradujó en beneficios económicos. Los modelos ARIMA construidos con fuerza bruta obtuvieron el PPS esperado superior al 60%. Además, independientemente de la significación estadística de la capacidad predictiva de los modelos, estos superaron en rentabilidad a la estrategia de inversión pasiva o buy and hold, la cual evidenció una rentabilidad negativa en cada uno de los valores analizados.
E t-1 + ... +β MA E t-MA +θ 1 • ∆DJI t-1 + ... +θ x • ∆DJI t-x +E t (8)
∆ROSN.ME=α 1 • ∆ROSN.ME t-1 + ... +α AR • ∆ROSN.ME t-AR +β 1
E t-1 + ... + β MA E t-MA +θ 1 • ∆DJI t-1 + ... +θ x • ∆DJI t-x +E t (9)
Se probó la solidez de estos resultados a fin de evitar el problema de data snooping. Para ello se tomó el mejor modelo de proyección para cada valor y se lo evaluó en un total de 100 conjuntos extramuestrales de 262 datos de cierre semanales cada uno. Estos 100 conjuntos extramuestrales fueron generados a partir del conjunto extramuestral original utilizando un proceso de block bootstrap.
Al analizar la rentabilidad acumulada que se habría obtenido siguiendo las recomendaciones de compra-venta de los modelos ARIMA se encontró que, de los 100 conjuntos extramuestrales, estos superaron el rendimiento de una estrategia buy and hold en 86,8%, 464,55%, 135,3% y 106,45% de los casos en los valores Exxon Mobil, Gazprom, Rosneft Oil y Petróleo respectivamente. En Gazprom la magnitud con que el modelo ARIMA superó en rentabilidad a la estrategia pasiva fue más de lo esperado (464,55%).
En este estudio, para la selección del mejor modelo ARIMA del universo infinito de combinaciones, la computadora demoró cerca de dos días en conseguir el mejor resultado. Por lo tanto, se comprueba que utilizar fuerza bruta con un equipo de alta tecnología es un método altamente eficiente.
Conclusiones
La subida o baja del precio del barril de petróleo se le asocia a las condiciones internacionales del mercado y a la especulación, siendo como commoditie un instrumento de inversión altamente atractivo; por ello, encontrar un buen modelo predictivo que permita proyectar el cambio de signo en el precio es un desafío permanente para distintos actores que participan de los mercados. Por tal razón se ha observado una creciente utilización de modelos predictivos, unos más exitosos que otros, y es así como el modelo propuesto de ARIMA con fuerza bruta es una innovación reciente a partir de modelos más tradicionales y que aprovecha las tecnologías existentes. Es en este contexto que los resultados obtenidos en esta investigación permiten inferir que sí es factible construir un modelo predictivo con una capacidad de predicción superior al 60%, tanto para el caso del petróleo como para las acciones de empresas petroleras. Los modelos se construyeron con un millón de iteraciones con fuerza bruta, dado que la optimización por simplex o solver no alcanzó el resultado esperado.
Los modelos ARIMA elaborados a partir de las variables endógenas (precios históricos del valor) y exógenas (variación del valor del DJI) con fuerza bruta obtuvieron una gran capacidad para predecir el signo de las variaciones semanales de los valores del petróleo, Exxon Mobil, Gazprom y Rosneft Oil. Los resultados de la prueba de acierto direccional de Pesaran y Timmermann (1992) indicaron que los modelos ARIMA presentaron una capacidad predictiva estadísticamente significativa. A su vez, estos modelos obtuvieron la mayor rentabilidad acumulada en el periodo extramuestral para Gazprom con un 64,09% de PPS.
Al analizar la rentabilidad acumulada que se habría obtenido siguiendo las recomendaciones de compra-venta de los modelos ARIMA, se encontró que, de los 100 conjuntos extramuestrales, estos superaron el rendimiento de una estrategia buy and hold en 86,8%, 464,55%, 135,3% y 106,45% de los casos en los valores de Exxon Mobil, Gazprom, Rosneft Oil y Petróleo respectivamente. En Gazprom, la magnitud con que el modelo ARIMA superó en rentabilidad a la estrategia pasiva fue más de lo esperado (464,55%). De esta manera, este estudio presenta evidencia de que los modelos ARIMA optimizados con fuerza bruta pueden ser utilizados como otra metodología para mejorar los modelos de proyección de series de tiempo, en función de su capacidad de predicción de signo, siendo un modelo útil para tomadores de decisiones o inversionistas de este sector.
Finalmente, es necesario señalar que el carácter seminal de este estudio obliga a una búsqueda constante de mejoras al modelo, integrando nuevas variables que ayuden a generar una mayor capacidad de predicción. Por otro lado, se recomienda nuevas líneas futuras de investigación en la aplicación del modelo propuesto, ya sea comparándolo con otros modelos predictivos o replicando su aplicación en distintos activos y mercados, commodities transables, opciones financieras y, por ende, en acciones de compañías en diferentes bolsas de valores.