









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
Tradicionalmente, el investigador agropecuario está preocupado por obtener en sus estudios coeficientes de variación bajos, ya que se interpreta como buena precisión experimental. El tema es conflictivo, puesto que algunos investigadores opinan de manera diferente y cuestionan el coeficiente de variación como un indicativo real de precisión experimental ( Barreto y Raun, 1990 ; Bowman y Watson, 1997 ; Taylor et al., 1999 ; Bowman, 2001 ). La precisión experimental se relaciona con la capacidad de encontrar diferencias entre los tratamientos evaluados ( Steel y Torrie, 1980 ).
La repetitividad se define como la fracción de la variancia, total del carácter que se debe a las diferencias permanentes entre los individuos y al igual que la heredabilidad, puede tomar valores entre 0 y 1 ( Boake, 1989 ; Falconer, 1990 ; Holland et al., 2003 ). La heredabilidad o repetitividad H, es un indicativo de la validez o utilidad de las pruebas de evaluación de genotipos, cuando H = 1 significa que las diferencias observadas entre las medias genotípicas del ensayo son debido al efecto genético; mientras que H = 0 indica que las diferencias observadas son debido al error aleatorio o experimental ( Yan y Holland, 2010 ).
La repetitividad difiere de acuerdo con la naturaleza del carácter, de las propiedades genéticas del germoplasma y de las condiciones ambientales bajo los cuales fueron evaluados ( Yan, 2014 ). Esta tiene una interpretación precisa si las diferentes mediciones son del mismo carácter genético, mientras que Gordon-Mendoza y Camargo-Buitrago (2015a) , denotan que la repetitividad puede ser un estadístico robusto para medir la precisión de los experimentos, con menos sesgo que el coeficiente de variación.
En un estudio se determinó que la repetitividad (H) del experimento con relación a la media general fue baja ( Gordon-Mendoza y Camargo-Buitrago, 2015a ), sin embargo, estuvo altamente relacionada a los R2, tanto de los tratamientos como de la fracción no explicada del modelo. Esta relación denota que H puede ser un estadístico robusto para medir la precisión de los experimentos, con menos sesgos que el coeficiente de variación (CV), que depende más de la expresión de la media ambiental. Por otro lado, al relacionar ambos estadísticos (CV y H) con el cociente DMS/rango, se encontró que H estuvo altamente correlacionada, mientras que CV no. En términos generales, los resultados permitieron indicar que la repetitividad fue mejor indicador que CV, como estimador de precisión experimental, ya que se consideró la variabilidad debido a los tratamientos y no al error experimental ( Gordon-Mendoza y Camargo-Buitrago, 2015a ). El objetivo del estudio fue mostrar que la repetitividad es un estadístico que está relacionado con la precisión experimental en el análisis de experimentos.
MATERIALES Y MÉTODOS
Para este trabajo se utilizó la base de datos de los ensayos realizados por el Proyecto de Arroz del Instituto de Investigación Agropecuaria de Panamá (IDIAP). Se seleccionaron los ensayos del período de años comprendido entre 2000 y 2014. Los ensayos consistieron de los experimentos realizados en parcelas de productores colaboradores en las principales zonas de producción de arroz del país (Panamá, Coclé, Los Santos, Veraguas y Chiriquí), desarrollados en un ámbito agroecológico de las tierras bajas de la costa Pacífica del Istmo, con un régimen de humedad ústico y údico, bajo el sistema de producción de secano favorecido. Se incluyeron en la base de datos los ensayos de variedades precoces e intermedias en la primera y segunda fase de experimentación, así como los cultivares élites del proyecto.
Del total de ensayos, un grupo de los mismos fueron sembrados con un diseño de bloques completos al azar, mientras que otros fueron sembrados utilizando el diseño de alfa látice ( Vargas et al., 2013 ). A continuación, se presentan los modelos matemáticos para los ensayos de bloques (ecuaciones 1 y 2) y alfa látice individual y combinado, utilizados en campo (ecuaciones 3 y 4) ( Vargas et al., 2013 ; Yan, 2014 ):
Yijk=µ+Repi+Genk+εik (1)
Yijkl=µ+Loci+Repj(Loci)+Genl+LocixGenl+εijkl (2)
Yijk= µ+Repi+Blockj(Repi)+Genk+εijk (3)
Yijkl= µ+Loci+Repj(Loci)+Blockk(LociRepj)+Genl+
LocixGenl+εijkl (4)
La base de datos que se analizó incluyó 134 ensayos de adaptación de variedades intermedias, 126 ensayos de variedades precoces y 124 ensayos de variedades élites, de los cuales se eliminaron diecisiete ensayos que no mostraron variabilidad para ninguna de las fuentes del diseño experimental, quedando un total de 367 ensayos en el análisis de la investigación. Estos experimentos variaron entre cinco y treinta tratamientos ( Figura 1 ).
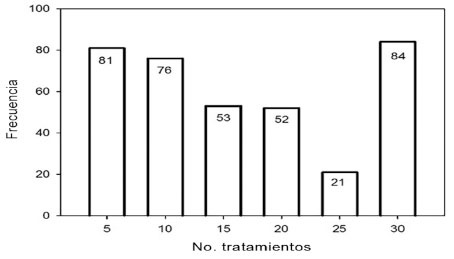
Figura 1 Distribución del número de experimentos de acuerdo con el total de tratamientos por ensayos en la base experimental, realizados por el Proyecto de Arroz del Instituto de Investigación Agropecuaria de Panamá (IDIAP). 2000-2014. Figure 1. Distribution of the number of experiments according to total treatments based experimental trials, conducted by the Rice Project Agricultural Research Institute of Panama (IDIAP). 2000-2014.
Los ensayos analizados tuvieron distinto número de repeticiones. La composición de los ensayos se agrupó de la siguiente manera: 114 ensayos con dos repeticiones, 256 ensayos con tres repeticiones y, los restantes nueve con cuatro repeticiones. Para el trabajo se tomó la variable rendimiento de grano en t/ha de todos los experimentos.
En la primera etapa de la investigación, a cada experimento, se calcularon los distintos componentes de varianza del modelo lineal. Para esto, se utilizó el método REML implementado en el procedimiento MIXED de SAS. Adicional a las varianzas (δ2) o cuadrados medios (CM) del modelo, se calculó el coeficiente de variación (5), repetitividad (6 y 7), rango (8), diferencia mínima significativa (9), coeficiente de determinación de los tratamientos (10) y de la fracción no explicada por el modelo (error experimental) (11) para el rendimiento. También, se calculó el cociente sugerido por Gordon-Mendoza y Camargo-Buitrago (2015a) , entre el DMS y el rango (DMS/rango) (12). Una vez realizados los cálculos de todos los estadísticos por análisis combinado se graficaron y correlacionaron tanto CV como H. Las fórmulas utilizadas para el cálculo de los estadísticos fueron las siguientes:
En la segunda etapa, se procedió a realizar el análisis combinado de cada ensayo, incluyendo todas las localidades sin importar el valor de la repetitividad de cada una (46 ensayos). Luego, se realizaron los análisis combinados por ensayo dependiendo del valor de repetitividad de las localidades. Se realizó el análisis combinado eliminando los ensayos cuyo valor de repetitividad fue cero (veinticinco ensayos). Se eliminaron los ensayos con valores menores de 0,20 (diez ensayos), 0,30 (ocho ensayos), 0,40 (doce ensayos) y 0,50 (veintrés ensayos). Las localidades cuya repetitividad no cumplieron con el requisito se eliminaron de cada análisis. Para cada combinado se calcularon los otros estadísticos en el análisis individual por experimento.
El análisis de los datos en esta etapa, consistió en determinar el efecto sobre la precisión experimental, al eliminar los ensayos con valores de repetitividad mínimos con el resto de los estadísticos calculados:CV, DMS/rango, cuadrados medios del error, tratamiento y la interacción localidad por genotipos. Este concepto de precisión experimental mediante el cociente DMS/rango es explicado por Gordon-Mendoza y Camargo-Buitrago (2015b) , mediante la Figura 2 . Cuando el DMS/rango se acerca a cero, indica la capacidad de señalar diferencias entre los tratamientos, mientras que cuando su valor se acerca a uno, prácticamente no hay diferencias entre los tratamientos evaluados, por ende, se tiene una baja precisión experimental.
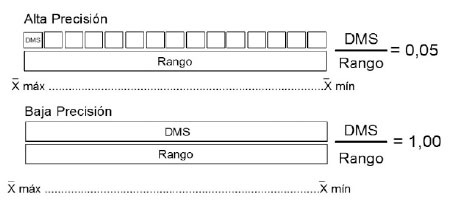
Gordon-Mendoza y Camargo-Buitrago (2015b)
Figura 2 Explicación gráfica del concepto de precisión experimental basado en el cociente DMS/Rango. Figure 2. Graphical explanation of experimental precision concept based on the ratio LSD/Range.
RESULTADOS Y DISCUSIÓN
Estimativa de estadísticos en análisis de experimentos individuales
El análisis de los experimentos individuales de los datos de arroz, permitieron verificar que existió muy baja relación lineal entre CV y H, con un coeficiente de correlación de Pearson de 0,34 ( Figura 3 ). Resultados similares de poca relación entre estos dos estadísticos fueron señalados por Yan y Holland (2010) , Gordon-Mendoza y Camargo-Buitrago (2015a) , lo que permite el uso de la repetitividad para estimar la precisión experimental, sin los sesgos que presenta el coeficiente de variación con relación a su correlación con la media ambiental de los experimentos. También se observó que a mayores valores de repetitividad (>0,80), hubo menor dispersión de los coeficientes de variación, posiblemente la variabilidad experimental se debió a efectos genéticos o a una baja proporción de la variabilidad debido al error experimental, que normalmente aumenta y dispersa el valor del CV ( Gordon-Mendoza y Camargo-Buitrago, 2015a ).
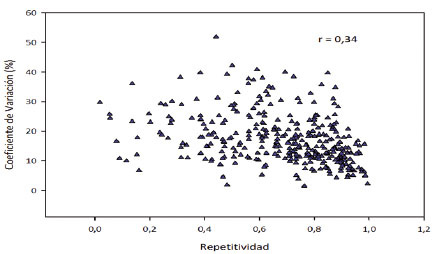
Figura 3 Relación entre el coeficiente de variación y los valores de repetitividad de los experimentos analizados individualmente, indicando independencia entre los dos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 3. Relationship between coefficient of variation and repeatability values of singles analysis of experiments, indicating independence between the two statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
La relación inversa entre H y R2 del error ( Figura 4 ), significa que valores altos de H, cercanos a 1,00, estuvieron relacionados con valores bajos del R2 del error, cuando H=0,00 indica que las diferencias observadas se debieron al error experimental ( Yan y Holland, 2010 ). Además, se destaca que a medida que aumenta el número de repeticiones en los experimentos, el valor de la repetitividad aumenta, permitiendo de este modo, el mejorar la precisión de los experimentos.
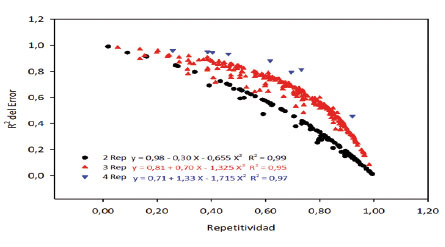
Figura 4 Relación entre R2 del error con la repetitividad, según el número de repeticiones de los experimentos, mostrando una relación inversa entre los dos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 4. Relationship between R2 of error with repeatability, according to trials replicates number, showing an inverse relationship between the two statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
De acuerdo con las ecuaciones para cada tipo de ensayo en función del número de repeticiones, se encontró que cada una explica un alto porcentaje de la relación cuadrática entre las dos variables (R2 de 0,97; 0,97 y 0,98). La relación entre la repetitividad y el R2 de los tratamientos resultó ser positiva ( Figura 5 ), es decir a mayor valor de H se encontró un mayor valor del R2 de los tratamientos en cada experimento. En relación al número de repeticiones, el aumento de dos a cuatro repeticiones favoreció la repetividad, en consecuencia mejoró la precisión experimental. Esto se debe que para un mismo valor del R2 de tratamientos de un ensayo se obtiene un valor más alto de la repetitividad.
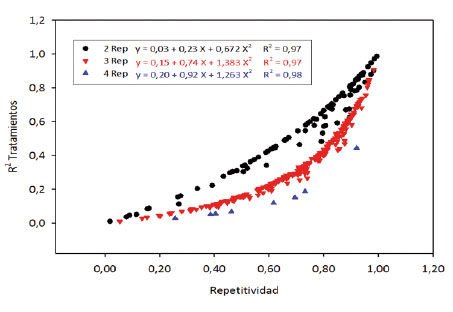
Figura 5 Relación entre el R2 de tratamientos con la repetitividad, según el número de repeticiones de los experimentos, marcando una relación directa entre ambos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 5. Relationship between R2 of treatments with repeatability, according to trials replicates number, making a direct link between both statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
Existió una estrecha relación entre el cociente DMS/rango vs. repetitividad ( Figura 6 ); entre menor fue este cociente, mayor fue la repetitividad; esta relación fue mayor en los ensayos con tres repeticiones que en aquellos que tuvieron dos repeticiones por localidad. Estos resultados coinciden con los obtenidos por Gordon-Mendoza y Camargo-Buitrago (2015a) , lo que sugiere que el valor obtenido de estos dos estadísticos están inversamente correlacionados, indicando buena precisión cuando se obtienen valores de repetitividad altos o que se acerquen a uno (1,0), es decir, valores de repetitividad cercanos a uno corresponden a valores del cociente DMS/rango cercanos a cero, lo que implica alta capacidad de establecer diferencias entre media de los tratamientos del ensayo ( Figura 2 ). Estos estadísticos (DMS/rango y repetitividad) son excelentes indicadores de la precisión experimental, sin tantos sesgos como el coeficiente de variación.
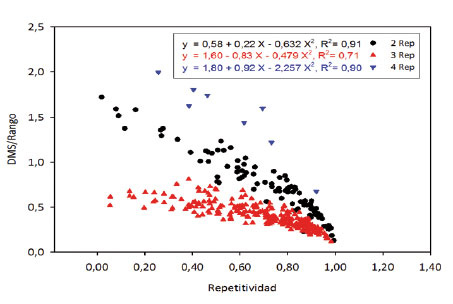
Figura 6 Relación entre el coeficiente DMS/rango y repetitividad según el número de repeticiones de los experimentos, mostrando una relación inversa entre ambos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 6. Relationship between LSD/range ratio and repeatability according to the trials replicates number, showing an inverse relationship between the two statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
Los resultados obtenidos al analizar individualmente los experimentos de arroz, coinciden con los obtenidos con los análisis realizados a los experimentos individuales de maíz ( Gordon-Mendoza y Camargo-Buitrago, 2015a ). Lo que indica que la relación entre el DMS/rango vs. repetitividad están relacionados. Ambos estadísticos son herramientas que se calculan de manera fácil, así que representan una manera robusta para la estimación de la precisión experimental para ensayos individuales o simples. Valores bajos en el cociente DMS/rango implicó mayor precisión experimental, y a la inversa, valores altos del cociente implicaron baja precisión. De igual manera, experimentos con dos repeticiones tendrían menor precisión que uno de tres repeticiones ( Yan, 2014 ).
Estimativa de estadísticos en análisis de experimentos combinados
Los experimentos de evaluación de cultivares se desarrollan en múltiples localidades y años, para tomar la decisión de cuáles recomendar en las regiones de interés. Los efectos genéticos, ambientales y la interacción genotipo por ambiente juegan un papel preponderante en el comportamiento de los materiales genéticos, e influyen en la precisión experimental; con esta premisa se estimaron los estadísticos CV, H, R, DMS, R2, DMS/rango, considerando en esta etapa el análisis combinado de los datos.
La relación entre el coeficiente de variación vs. la repetitividad en los análisis combinados de los experimentos ( Figura 7 ), verificó la tendencia observada en el análisis individual de los experimentos ( Figura 3 ). Es decir, estos estadísticos no guardaron ninguna relación entre sí ( Yan y Holland, 2010 ; Gordon-Mendoza y Camargo-Buitrago, 2015a ), con un coeficiente de correlación de Pearson de 0,10.
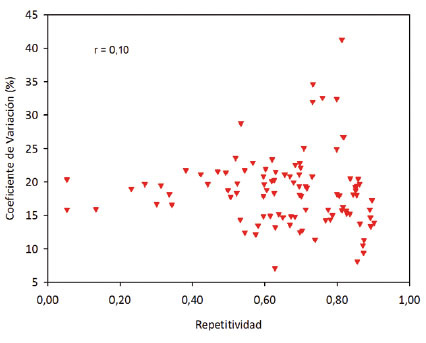
Figura 7 Relación entre el coeficiente de variación y los valores de repetitividad de los experimentos combinados, mostrando una independencia entre los dos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 7. Relationship between coefficient of variation and repeatability values of combined experiments, showing independence between the two statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
La relación matemática entre la repetitividad y el R2 de los tratamientos resultó ser de tipo exponencial. Las ecuaciones encontradas explicaron el 67 y 86% de los modelos ajustados para los ensayos con tres y dos repeticiones, respectivamente. La tendencia observada en los análisis combinados ( Figura 8 ), coincide con la respuesta de los análisis individuales ( Figura 5 ), mostrando la relación directa entre la R2 de tratamientos vs. H, así valores altos de H, cercanos a 1,00, están relacionados con valores altos del R2 de tratamientos.
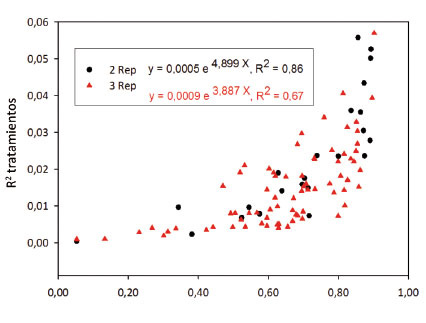
Figura 8 Relación entre el R2 de tratamientos y los valores de repetitividad de los experimentos combinados, señalando una relación directa entre los dos estadísticos. IDIAP, Panamá. 2000-2014. Figure 8. Relationship between R2 of treatments and repeatability values of combined experiments, indicating a direct relationship between the two statistics. IDIAP, Panama. 2000-2014.
La relación entre el cociente DMS/rango vs. repetitividad, observada en los análisis individuales ( Figura 6 ), se mantuvo en los análisis combinados ( Figura 9 ). Entre menor fue este cociente mayor fue la repetitividad, esta relación fue más estrecha en los ensayos con tres repeticiones por localidad. Los resultados coinciden con los de Gordon-Mendoza y Camargo-Buitrago (2015a) , y reiteran que los estadísticos estimados, H y el cociente DMS/rango, son indicadores de la precisión experimental, con menos sesgos que el coeficiente de variación, que es el cociente de una medida de dispersión sobre una tendencia central. La relación del cociente DMS/rango con el estadístico H, en términos generales, se observa en la Figura 9 e indicó que para valores de H entre 0,60 y 0,80, mostró valores del índice DMS/rango entre 0,20 y 0,80, con valores de R2= 0,51. Por otro lado, la relación de estos dos estadísticos en experimentos con dos repeticiones presentó un R2= 0,98; mientras que con tres repeticiones presentó un R2= 0,68, explicando el modelo que entre mayor H menor el cociente DMS/rango.
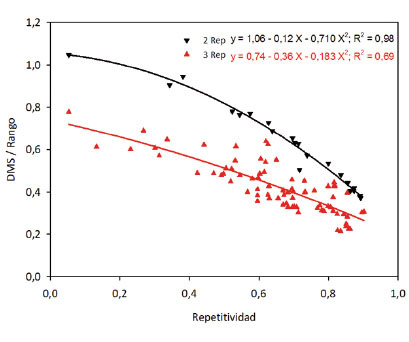
Figura 9 Relación entre el cociente DMS/rango y los valores de repetitividad de los ensayos con dos y tres repeticiones, muestra una relación inversa entre los dos estadísticos. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 9. Relationship between LSD/range ratio and repeatability values of trials with two and three replicates it shows an inverse relationship between the two statistics. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
La relación entre el número de localidades y la repetitividad fue lineal, a medida que aumentaron las localidades aumentó la repetitividad, en consecuencia, hubo mejor precisión experimental ( Figura 10 A). Mientras que la relación número de localidades vs. DMS/rango fue inversa, al aumentar las localidades disminuyó la proporción DMS/rango, lo que mejoró la precisión experimental ( Figura 10 B). Es indudable el efecto de los ambientes a través de los años, sobre la estimación del cociente DMS/rango y sobre la repetitividad, la cual está influenciada por el número de tratamientos y por el número de repeticiones de los experimentos.
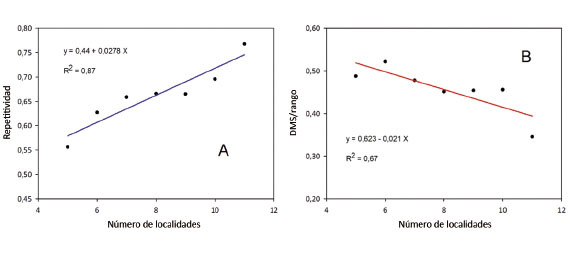
Figura 10 Relación entre número de localidades vs repetitividad muestra una relación directa (A) y el cociente DMS/rango con el número de localidades presenta una relación inversa (B). Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 10. Relationship between locations number vs repeatability shows a direct relationship (A) and LSD/range ratio with the number of locations has an inverse relationship (B). Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
Respuesta en la precisión experimental al descartar localidades con baja repetitividad (H) y su relación con el cociente DMS/rango
De los 42 ensayos combinados analizados, cinco ensayos fueron eliminados por presentar un valor de repetitividad igual a cero, quedando 37 ensayos para la interpretación del efecto de eliminar localidades con un valor específico de repetitividad. De los cinco ensayos eliminados, cuatro ensayos eran de evaluaciones de genotipos élite que constaban de evaluar cinco tratamientos y dos repeticiones por ensayo, estos ensayos se caracterizaron porque la varianza de los tratamientos fue cero. De los 37 ensayos restantes, se eliminó al menos una localidad a veinte de ellos, lo que presentó un valor de H=0,00; a ocho (H<0,20); seis (H<0,30), y nueve (H<0,30); seguidamente a veinte ensayos se les eliminaron localidades con H menos de 0,20; 0,30; 0,40 y 0,50, respectivamente ( Cuadro 1 ).
Cuadro 1 Número de localidades eliminadas (loc), número y porcentaje de ensayos analizados, y valores de la repetitividad antes y después de eliminar localidades que no cumplieron con el valor requerido para determinar el efecto sobre el análisis combinado a través de localidades. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Table 1. Number of eliminated sites (loc), number and percentage of analyzed experiments and repeatability number before and after removing localities that do not meet the required value, to determine the effect on the combined analysis across locations. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
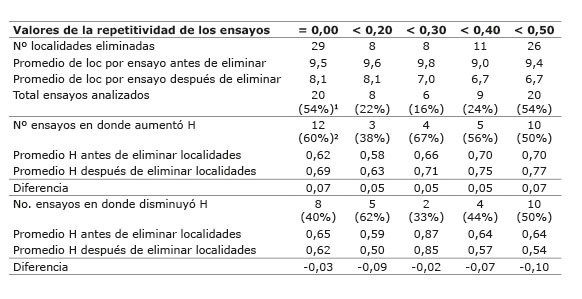
1El valor en paréntesis representa el porcentaje del total de ensayos combinados de la base de datos (37) / The value in parentheses represents the percentage of combined trials database (37).
2El valor en paréntesis representa el porcentaje del total de ensayos en donde se eliminaron las localidades que no cumplieron con el valor mínimo / Value in parentheses represents the percentage of trials where the sites that did not meet the minimum value were eliminated.
Cuando se descartaron o eliminaron los sitios con repetitividad igual a 0,00, la precisión experimental se incrementó en un 60% de las localidades, sin embargo, cuando solo se eliminaron aquellos ensayos con valores menores de 0,20, 0,30, 0,40 y 0,50, los niveles de precisión experimental aumentaron en 38, 67, 56 y 50% de las localidades, respectivamente ( Cuadro 1 ). Cuando se incluyó en el análisis combinado aquellas localidades con H mayores de 0,20 y se descartó aquellas con H iguales a 0,00 y menores de 0,20, para aumentar la eficiencia experimental, se obtuvieron mejores resultados. El valor de la repetitividad en los ensayos que se reportaron con una disminución, fue mayor que el valor de la repetitividad de los ensayos en donde se encontró un aumento de este estadístico, antes de eliminar las localidades con valores de H menores de 0,30; esto sugiere que cuando el valor de la repetitividad fue alto no hubo ganancias por eliminar localidades con bajo valor de H.
Con relación al número de localidades promedio por ensayo, antes y después de eliminar las localidades que no cumplían con el mínimo valor de H requerido para su análisis combinado a través de localidades, se encontró que el número de localidades por ensayo fue similar para las cinco categorías analizadas (con valores superiores a nueve localidades por ensayo). Luego el número de localidades por ensayo se redujo al eliminar las localidades con los valores más bajos de repetitividad. Al aumentar el número de localidades eliminadas en los ensayos combinados, a su vez, explicó por qué aumenta inicialmente la repetitividad y luego se reduce después de eliminar un número mayor de localidades ( Figura 11 ).
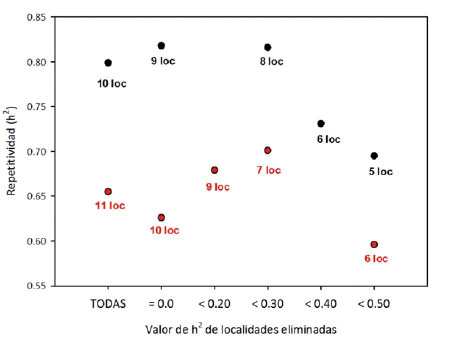
Figura 11 Comportamiento de la repetitividad del análisis combinado al eliminar localidades con valores de H que no cumplían con el requisito establecido en dos ensayos analizados. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Figure 11. Performance of repeatability of combined analysis to remove locations with H values that did not meet the established requirement of two trials analyzed. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
El incremento en la precisión experimental observada en el Cuadro 1 , se explica con la tendencia observada en el Cuadro 2 , la cual sugiere que cuando se eliminan del análisis aquellas localidades con los valores de repetitividad no requeridos, el CM error disminuyó en promedio en el 85% de las localidades mientras que el CM de tratamientos y la interacción localidad x tratamientos (Loc x Trat) aumentaron en un 81% y 86% de las localidades, respectivamente. El CM de localidad aumentó y disminuyó en un igual número de localidades, con relación a los ensayos en donde aumentó y disminuyó el valor de la repetitividad.
Cuadro 2 Porcentaje de localidades en donde se aumentó o redujo los componentes de la varianza al eliminar ensayos con determinado valor de la repetitividad (H), en los ensayos combinados a través de localidades. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Table 2. Percentage of sites where increase or decrease the components of variance when trials were eliminated with determinate value of repeatability, in the combined testing across locations. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
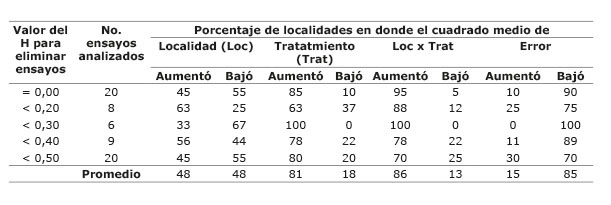
En el grupo de ensayos donde se procedió a eliminar las localidades con H<0,30, el CM residual disminuyó en 100%, mientras el cuadrado medio del tratamiento y la interacción Loc x Trat aumentó en un 100%, respectivamente. La repetitividad difirió de acuerdo con la naturaleza del carácter y a las propiedades genéticas y condiciones ambientales ( Falconer, 1990 ). En el Cuadro 2 , se muestra cómo en la mayoría de las localidades se incrementó el cuadrado medio de los tratamientos y la interacción Loc x Trat, mientras el cuadrado medio del error disminuyó en muchas más localidades, en función de eliminar localidades con las diferentes H planteadas.
Conforme se fueron eliminando las localidades con los diferentes valores de H, se pudo cuantificar el aumento o disminución de los CM ( Cuadro 3 ). Cuando se eliminaron las localidades con H=0,00, los cuadrados medios de localidad, tratamiento y la interacción Loc x Trat aumentaron 0,326; 0,034 y 0,063, respectivamente. Mientras que el único que disminuyó más de lo que aumentó, fue el CM del error. Esta respuesta en el CM del error es la que explica el aumento de la precisión experimental, cuando se elimina del análisis combinado localidades con H=0,00 y H<0,20.
Cuadro 3 Promedio del aumento o disminución de los cuadrados medios (CM) de acuerdo con la eliminación de las localidades (Loc) con valores de repetitividad (H) deseado, en el análisis combinado a través de localidades. Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Table 3. Average of the increase or decrease of the Means Squares (CM) according to removing sites (Loc) with repeatability-desired values, in the combined analysis across locations. Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
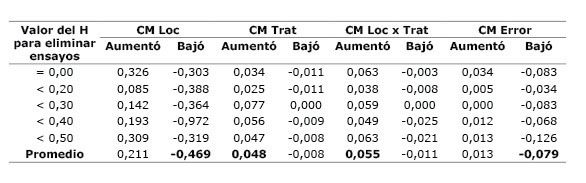
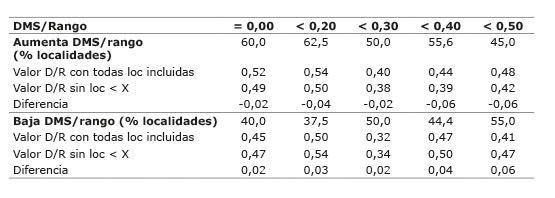
Cuando se eliminaron las localidades con repetitividad igual a cero ( Cuadro 4 ), la relación o índice DMS/rango mejoró su nivel de precisión en 60,0%; de igual manera ocurrió, cuando se eliminaron las localidades con H menor de 0,20, la precisión se incrementó en un 62,5%. Los resultados parecen indicar que con la eliminación de localidades cuyos valores H varían de 0,30 a 0,50, no se gana mayor precisión experimental puesto que el cociente DMS/rango presentó valores de 50,0; 55,8 y 45,0%, respectivamente. Al comparar la respuesta en la precisión experimental que ocurre al descartar localidades con baja repetitividad, respecto a los estadísticos H ( Cuadro 1 ), y el cociente DMS/rango ( Cuadro 4 ), la precisión experimental que se obtuvo fue muy similar cuando se eliminaron las localidades con H=0,00 y H<0,20; no obstante, el cociente DMS/rango pareció más consistente. Esta relación es explicada en la Figura 9 , y coincide con los resultados de Gordon-Mendoza y Camargo-Buitrago (2015a) .
Cuadro 4 Valores del cociente DMS/rango (D/R) en función de los valores de repetitividad eliminados y sin eliminar las localidades (Loc). Instituto de Investigación Agropecuaria de Panamá (IDIAP), Panamá. 2000-2014. Table 4. Values of LSD/Range ratio (D/R) according to repeatability values eliminated and without eliminated sites (Loc). Agricultural Research Institute of Panama (IDIAP), Panama. 2000-2014.
El concepto de precisión experimental está relacionado con la capacidad de encontrar diferencias entre los tratamientos evaluados ( Steel y Torrie, 1980 ). La repetitividad y el cociente DMS/rango son mejores indicadores de la precisión experimental que el coeficiente de variación en experimentos simples ( Gordon-Mendoza y Camargo-Buitrago, 2015a ), resultados que coinciden con los obtenidos en este estudio para los análisis simple y en experimentos combinados. No obstante, para obtener una buena precisión experimental con ambos estadísticos, en los análisis simples y combinados, se requiere aplicar un adecuado número de repeticiones, de tratamientos y de localidades.
Al eliminar localidades con valores de H<0,20 aumentó significativamente el valor de la repetitividad del análisis combinado. De igual manera ocurrió con el cociente DMS/rango, se incrementó su precisión, cuando se descartaron las localidades con H igual a 0,00 y H menor o igual a 0,20; ambos estadísticos estuvieron significativamente correlacionados, siendo su precisión mejor a medida que aumentó el número de localidades y repeticiones. Los resultados también demostraron la robustez de ambos estadísticos y de esta herramienta, para estimar precisión experimental en experimentos simples y combinados, y con menos sesgos que el tradicional coeficiente de variación.