









 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
Se conoce (Engle & Granger, 1987) que los modelos de corrección de errores (ECM, por sus siglas en inglés) son útiles cuando se tienen datos igual e idénticamente distribuidos (i.i.d.). En el estudio, estas ideas se aplican al problema de pronosticar los precios a los consumidores de un país pequeño con respecto a los precios al consumidor en EE.UU.
El estudio demuestra que los ECM pueden proporcionar pronósticos de alta calidad para los precios al consumidor en Costa Rica después de una regresión con respecto a los precios al consumidor de Estados Unidos. Durante el período de estudio, que va de 1996 a 2011, la evidencia disponible indica que los parámetros de regresión de los precios al consumidor de Costa Rica con respecto a los precios al consumidor de Estados Unidos cambiaron alrededor de octubre de 2008. Esta nota no trata de explicar este giro aparentemente brusco, pero se demostrará que el cambio no tiene que perturbar los pronósticos.
La situación es la siguiente: Hay dos series de tiempo, datos que dependen del tiempo, x y y, y una hipótesis es que para cada t, el valor x t llega antes del valor y t . La hipótesis de regresión es que hay dos constantes c y b tal que la serie y t -(c+bx t ) es estacionaria. Es más común decir que hay una serie {δ t } tal que {δ t } es estacionaria y

Para todo t. Por supuesto, los parámetros c y b indican una relación entre x y y, y tales relaciones pueden cambiar. Un cambio brusco en c y b puede convertir un procedimiento bueno para pronosticar en uno malo. En su origen, los MCE no fueron propuestos específicamente para este problema, pero es posible utilizarlos para pronosticar con exactitud durante el tiempo que los algoritmos de estimación de parámetros se están poniendo al día con los cambios. En ese sentido, en este trabajo se utiliza la naturaleza de corta duración de los MCE para compensar la naturaleza a largo plazo de las interrupciones de regresión.
Modelos de corrección de errores
Un modelo básico para corregir errores mejora la estimación del valor y t basado en los valores de y de tiempo t-1 y antes y, por supuesto, los valores de x de tiempo t y antes. Es posible que haya lectores que no estén familiarizados con este conjunto de ideas, por lo que se hará una breve descripción.
 Supongamos que hemos encontrado, por un procedimiento de mínimos cuadrados, los valores óptimos y para minimizar
Supongamos que hemos encontrado, por un procedimiento de mínimos cuadrados, los valores óptimos y para minimizar

Es decir, estamos estudiando una regresión de y contra x. Nuestras hipótesis dicen que
con la serie {δ t } estacionaria. Ahora, tenemos


Esta última ecuación sugiere que debemos definir nuestro MCE como la resolución de la regresión en dos variables
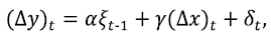
Con 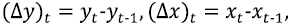 y
y 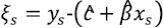 . Después de que se encuentran los
. Después de que se encuentran los 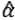 y
y 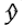 óptimos, podemos pronosticar y
t
en términos den x
t,
x
t-1
, y
t-1
, y ξ
t-1
002E
óptimos, podemos pronosticar y
t
en términos den x
t,
x
t-1
, y
t-1
, y ξ
t-1
002E
Un ejemplo sintético
Para ilustrar mejor este enfoque, consideramos una simple ilustración del problema y nuestros resultados (ver figura 1). Supongamos que 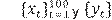 son dos series tal que, para cada
son dos series tal que, para cada 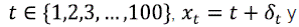
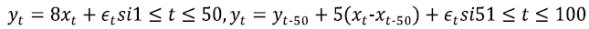
Con {δt} y {εt } resultados de una transformación de tipo MA(3) de N (0,1) (distribución normal, promedio0, varianza1). Por ejemplo, podemos generar 102 muestras de  de N (0,1) y definir
de N (0,1) y definir  . Definimos {εt } en la misma manera. Notamos que las dos series son estacionarias pero NO son independientes.
. Definimos {εt } en la misma manera. Notamos que las dos series son estacionarias pero NO son independientes.
El problema sencillo de pronosticación es predecir el valor yt solamente con los valores 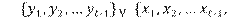 . Si una persona considera la posibilidad de que hay una regresión quebrada, pero no sabe si es la verdad, un procedimiento razonable es hacer, para cada t ≥ 30, una regresión de 30 datos que utilice las 30 muestras antes de t. Es decir, por ejemplo, cuando tenemos
. Si una persona considera la posibilidad de que hay una regresión quebrada, pero no sabe si es la verdad, un procedimiento razonable es hacer, para cada t ≥ 30, una regresión de 30 datos que utilice las 30 muestras antes de t. Es decir, por ejemplo, cuando tenemos 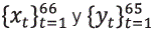 y , y se quiere pronosticar y
66, se hace una regresión básica de
y , y se quiere pronosticar y
66, se hace una regresión básica de 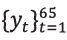 con respecto a
con respecto a 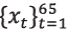 , y obtenemos el intercepto
, y obtenemos el intercepto  y la pendiente
y la pendiente 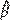 , y pronosticamos
, y pronosticamos 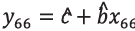 . Esto hicimos, y hubo errores visibles después del punto del cambio estructural (y y ˆy en el dibujo de abajo) con cuadrático medio mínimo de 70 pronósticos de 6.24. Los dos algoritmos que se describen abajo nos dan 1.34 y 1.59.
. Esto hicimos, y hubo errores visibles después del punto del cambio estructural (y y ˆy en el dibujo de abajo) con cuadrático medio mínimo de 70 pronósticos de 6.24. Los dos algoritmos que se describen abajo nos dan 1.34 y 1.59.
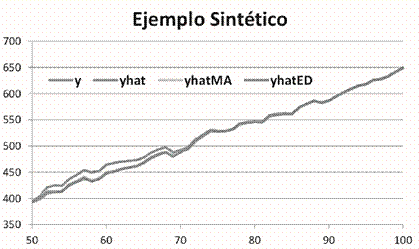
Los algoritmos
Tenemos dos versiones de nuestros algoritmos; una versión con promedios móviles (MA) y otra con disminución exponencial de los pesos (ED). El procedimiento comienza con una regresión básica de y contra x, por 30 muestras. Luego se actualizan los valores ˆc y ˆb muestra por muestra para hacer el primer pronóstico. Calculamos los errores y los ˆα y ˆγ , también muestra por muestra. Luego, mejoramos el pronóstico y hacemos el procedimiento completo para la siguiente muestra. Hay dos maneras de evitar las primeras muestras qué tienen demasiado efecto.
Se pueden calcular las sumas de la regresión con una ventana móvil o con un filtro exponencial con factor 1.
Pronósticos de inflación del país
Aplicamos nuestro procedimiento al problema de pronosticar la inflación de Costa Rica. Separamos los efectos de la inflación en dos partes, efectos exteriores y efectos interiores y modelamos los efectos exteriores de acuerdo con la inflación de Estados Unidos.
Un gráfico de una regresión básica del Índice de Precios al Consumidor (IPC) de Costa Rica con respecto al pci (siglas en inglés de IPC) de Estados Unidos nos da el resultado que se muestra en la figura 2.
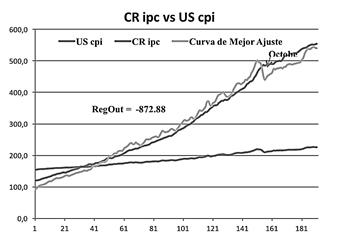
Figura 2 Gráfico de regresión básica del Índice de Precios al Consumidor (IPC) de Costa Rica con respecto al pci de Estados Unidos.
Se puede notar en la figura 2 que en octubre de 2008 se registró una importante ruptura económica.
Luego, aplicamos las ideas de esta nota y se obtiene lo que se muestra en la figura 3.
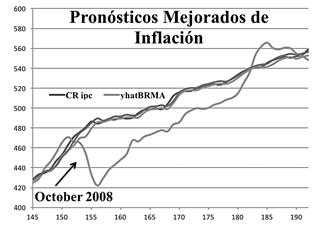
En el gráfico de la figura 3, la curva azul representa el IPC de Costa Rica, la curva roja muestra el resultado de la regresión básica con respecto al pci de Estados Unidos sin corrección. Las curvas verde y marrón corresponden a los dos procedimientos: ventana móvil y filtro exponencial.