










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkActa Médica Costarricense
On-line version ISSN 0001-6002Print version ISSN 0001-6012
Acta méd. costarric vol.50 n.2 San José Jun. 2008
Asociación entre variables cuantitativas: análisis de correlación
Jorge Camacho-Sandoval
Profesor, Maestría en Epidemiología, Postgrado en Ciencias Veterinarias, UNA.
Correspondencia: Correo electrónico: jcamacho@ice.co.cr
En la investigación clínica frecuentemente se miden numerosas variables en los individuos incluidos en el estudio. Muchas veces interesa determinar si existe relación entre algunas de esas variables, o predecir el valor de una de ellas conociendo el valor de otras. En ocasiones interesa determinar si distintos instrumentos, métodos o personas obtienen valores similares cuando se mide una variable en las mismas unidades experimentales. Esos tres objetivos requieren métodos de análisis distintos. La presente nota se refiere al primer objetivo: determinar si existe asociación entre variables.
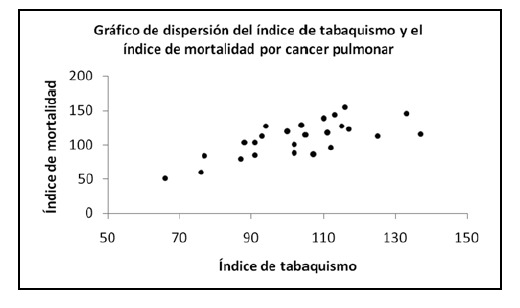
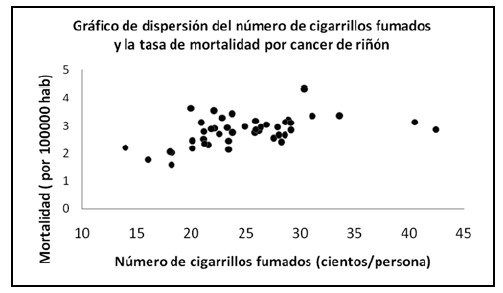
En el gráfico de dispersión del índice de tabaquismo y el índice de mortalidad por cáncer de pulmón adjunto, se puede observar que conforme se incrementa el índice de tabaquismo, se incrementa de forma lineal, el índice de mortalidad. Es decir, se puede representar la asociación entre esas variables, con una línea recta. En el segundo gráfico de dispersión, entre el número de cigarrillos fumados y la mortalidad por cáncer de riñón, se observa una relación que no es lineal, sino curvilínea. En ambos casos las variables están relacionadas, pero la forma de la relación es distinta.
El método más común de determinar si existe asociación lineal entre dos variables cuantitativas continuas es el Análisis de Correlación de Pearson. Con este método se obtiene el Coeficiente de Correlación de Pearson, usualmente representado por la letra R. Como suele utilizarse una muestra, lo que se obtiene en realidad es un estimado del coeficiente de correlación poblacional, r.
Dos aspectos importantes del coeficiente de correlación son su magnitud y su signo. La magnitud refleja la intensidad de la asociación entre las dos variables; el valor absoluto de la magnitud puede variar entre cero y uno. Valores cercanos a cero indican que las variables no están asociadas, es decir, que el valor de una variable es independiente del valor de la otra.
El signo, por su parte, refleja cómo están asociados los valores de ambas variables. Si el signo es positivo indica que a valores altos de una variable corresponden valores altos de la otra, o a valores bajos de una variable corresponden valores bajos de la otra. Si el signo es negativo, indica que a valores altos de una variable corresponden valores bajos de la otra. Es decir, el sigo positivo indica que los valores de ambas variables cambian en el mismo sentido, mientras que el signo negativo indica que cambian en sentido contrario. En la fórmula se observa que las unidades de ambas variables aparecen en el numerador y denominador, por lo tanto, se anulan aritméticamente, por lo que el coeficiente de correlación no tiene unidades de medición.
El cálculo del coeficiente de correlación es muy sencillo. Si se supone que se tienen dos variables cuantitativas continuas, por ejemplo, el número promedio de cigarros consumidos en cientos por persona (X), y la tasa de mortalidad por cáncer de pulmón en 15 localidades, en muertes por cien mil habitantes (Y), como se muestra en el Cuadro 1, una de las formas de cálculo es la siguiente (Zar, 1999):
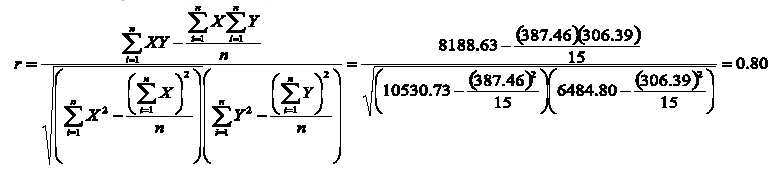
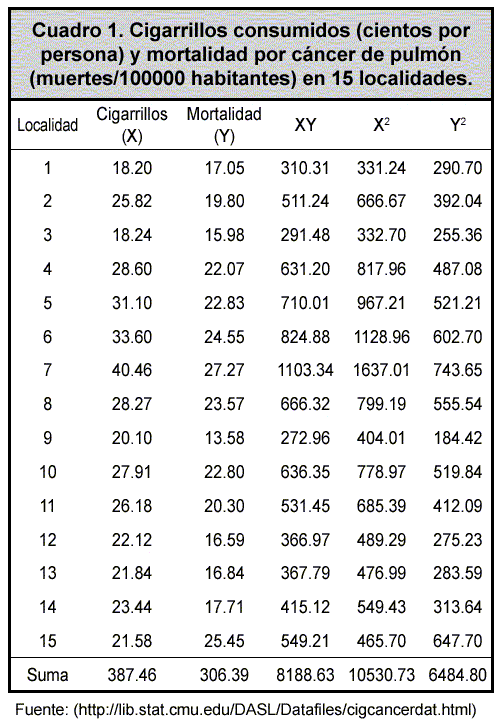
En el ejemplo se encontró una alta correlación positiva entre las variables, con un coeficiente de correlación de 0.80.
Para obtener el estimado del coeficiente de correlación no es necesario conocer la distribución de probabilidad de las variables; sin embargo, como se obtiene a partir de una muestra es preciso obtener indicadores de la variabilidad del estimado, como su error estándar o un intervalo de confianza. También es posible realizar pruebas de hipótesis, por ejemplo, para determinar si el coeficiente es estadísticamente diferente de cero. Para todo ello se requiere que las variables cumplan ciertos supuestos, específicamente, que tengan una distribución normal bivariada.
El error estándar de la correlación se calcula de la siguiente manera (Zar, 1999):
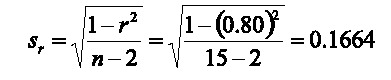
Una prueba de hipótesis sobre el coeficiente de correlación se puede establecer en los términos siguientes: hipótesis nula Ho: r=0; hipótesis alternativa H1: r≠0; estadístico de prueba: 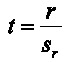 con n-2 grados de libertad y se rechaza la hipótesis nula sí
con n-2 grados de libertad y se rechaza la hipótesis nula sí 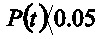 . En el caso del ejemplo
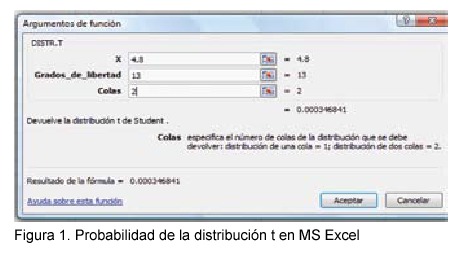
. En el caso del ejemplo 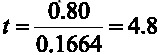 con una probabilidad de 0.0003 (Figura 1), por lo tanto, se rechaza la hipótesis nula y se concluye que el coeficiente de correlación es significativamente distinto de cero.
con una probabilidad de 0.0003 (Figura 1), por lo tanto, se rechaza la hipótesis nula y se concluye que el coeficiente de correlación es significativamente distinto de cero.
Si se prefiere, se puede construir un intervalo de confianza para el coeficiente de correlación. Como este no se distribuye normalmente, se debe realizar una transformación, de manera que el coeficiente de correlación transformado sí lo haga. La transformación se obtiene como:
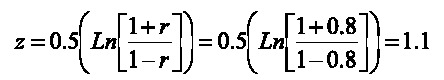
y su error estándar es:
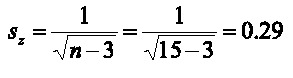
En donde Ln se refiere al logaritmo natural o neperiano. El intervalo de confianza del coeficiente transformado se obtiene de forma convencional (Camacho, 2007). En el presente caso el intervalo de confianza del 95% se consigue de la siguiente manera:
Límite inferior:
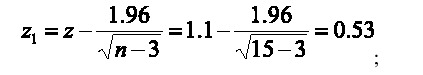
Límite superior:
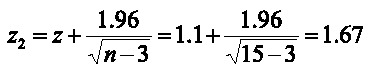
El valor de los límites se refiere al coeficiente de correlación transformado (z), por lo que se debe realizar el proceso inverso para obtener el intervalo de confianza de r.
Los límites inferior y superior se obtienen como:
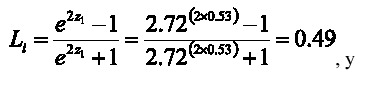
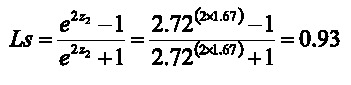
Es decir, se tiene un 95% de confianza de que el coeficiente de correlación en la población esté entre 0.49 y 0.93. La letra e representa la base de los logaritmos neperianos o naturales (2.72).
En una próxima nota se considerará el caso de variables que no cumplen el requisito de tener distribución normal bivariada.
Bibliografía
1. Camacho, J. 2007. ¿Hay diferencias significativas entre tratamientos? Primera parte. Acta Médica Costarricense 49(2): 81-82. [ Links ]
2. Zar, J. 1999. Biostatistical Analysis. 4th Ed. Prentice Hall, New Jersey. 663 pp. [ Links ]

