









 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
Por décadas la detección y monitoreo de las coberturas de la tierra se ha llevado a cabo por medio de teledetección aerotransportada o de satélites [1]. Los modelos globales de atmósferabiosfera que miden el flujo de carbono, agua y energía [2], la creación de políticas ambientales y áreas de conservación [3] y la caracterización de los bosques secundarios [4], [5], [6] dependen de datos de teledetección.
En una imagen obtenida por un instrumento de teledetección, las respuestas espectrales de la cobertura de la tierra están representadas por una combinación compleja de propiedades de reflexión de un gran número de características tanto a nivel elemental como grupal. Por ejemplo, a nivel individual la respuesta de la vegetación responde a la interacción de la luz y las propiedades de las hojas [7].
Sensores como Landsat 7 ETM+, ASTER, IKONOS, Quickbird, Hyperion y ALI registran una huella del paisaje cuya respuesta espectral depende la distribución espacial, la estructural del paisaje y la diversidad florística [8]. Sin embargo, la habilidad de detectar y cuantificar esos elementos del paisaje representados como coberturas de la tierra depende de las capacidades del sensor y las técnicas de clasificación. En específico, las capacidades del sensor de teledetección dependen directamente de la resolución espacial, espectral, radiométrica y temporal. Por ejemplo, si se compara la resolución espacial o tamaño de píxel de Landsat 8 OLI es 30m mientras tanto la de MODIS es 500m. Además, la resolución temporal o periodo de revisita de MODIS es de un día, mientras que Landsat 8 OLI es 27 días. En cuanto a la resolución espectral, MODIS posee 16 bandas, mientras que Landsat 8 OLI solo posee 10 bandas; no obstante, ambos cuentan con una resolución radiométrica de 16 bits.
Las técnicas clásicas de clasificación basada en píxeles pueden ser supervisada, no supervisada o mixta. El método supervisado a pesar de ser el más preciso al requerir una interpretación por medio de la delimitación de áreas de entrenamiento, lo que implica un arduo trabajo de recolección de muestras en campo [9]. Además, los resultados de una clasificación supervisada dependen no solo de la capacidad del algoritmo utilizado para discriminar las categorías; sino también de supuestos con respecto al comportamiento de las categorías. Por ejemplo, Maximum Likelihood, es un algoritmo que describe las categorías a partir de una función gaussiana (Se asume que los datos poseen una distribución normal), lo que lo hace más complejo que los otros algoritmos como Minimum Distance requiriendo así mayor volumen de cálculo [9].
Algoritmos como Support Vector Machine se caracterizan por separar de forma óptima un hiperplano n-dimensional en cuantos subespacios y clases se requieran [10]. En específico, para cada subespacio si es posible, se otorga un máximo margen de seguridad entendido como la distancia que existe entre la frontera de separación entre clases y el punto de entrenamiento más cercano a la misma [10]. Por otro lado, los algoritmos Neural Network se consideran semiparamétricos al estimar la densidad de probabilidad de una categoría [11].
Por consiguiente, este artículo busca demostrar la viabilidad de un modelo multi-algoritmo y jerárquico de clasificación de coberturas de la tierra, donde los criterios de selección de los mejores resultados se basan en valores de Kappa, precisión del usuario, precisión del productor y precisión general. El impacto potencial de este modelo incluye el reporte de cambios de la cobertura forestal a nivel regional e incluso nacional si se adapta a la diversidad de ecosistemas.
Metodología
Área de estudio
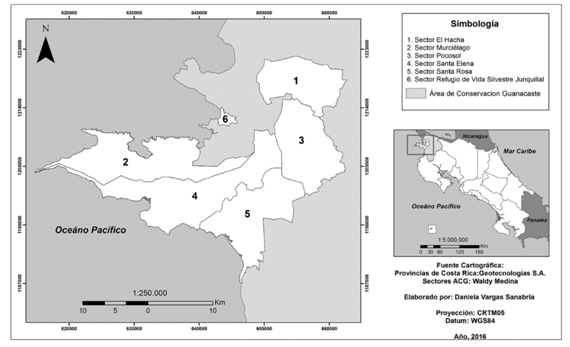
El área analizada en se ubica en bosque seco tropical, abarcando los sectores: Santa Rosa, Murciélago, Santa Elena (Parque Nacional Santa Rosa), Junquillal (Refugio Nacional de Vida Silvestre Bahía Junquillal), El Hacha y Pocosol (Parque Nacional Guanacaste), ubicados dentro del Área de Conservación Guanacaste, distrito de Santa Elena, cantón de La Cruz, en la provincia de Guanacaste, Costa Rica (Figura 1).
El Área de Conservación Guanacaste (ACG) se caracteriza por tener una precipitación anual entre 900 y 2400 mm, con una época seca que se extiende desde diciembre hasta abril [12]. Por lo general, la escala de temperatura varía con rangos nocturnos de 16°C a 23°C, mientras que, en el día son de 26 a 38°C [13]. Existe una gran variedad de vegetación costera, riberas y bosques siempre verdes, tanto dentro del área protegida como a sus alrededores, sin embargo, la mayoría de los hábitats se han transformado, destruido y homogenizados debido a actividades de tala, quema, siembra de pastos y actividades agrícolas [13].
Selección y pre-procesamiento de imágenes satelitales
Para el estudio de la categorización de coberturas de la tierra con imagen satelital se aplicó la metodología descrita a continuación (Figura 2). Se utilizó una imagen multiespectral LANDSAT 8 OLI adquirida en Abril del año 2015, con un nivel de procesamiento L1T (disponible en http:// earthexplorer.usgs.gov/, del Servicio Geológico de los Estados Unidos). La imagen seleccionada contó con una cobertura nubosa de 36.25% localizada fuera del área de estudio.
La calibración radiométrica se realizó para discriminar entre artefactos y la respuesta espectral de los elementos que están siendo monitoreados [14], [15]. Así como, para asegurar una comparación estandarizada de datos entre la imagen utilizada y cualquier otra imagen adquirida en diferentes fechas o por diferentes sensores [14]. En específico, se transformó los valores de pixel de niveles digitales (ND) a unidades físicas de radianza (W m-2 sr-1). Utilizando el software ENVI 5.1 se aplicaron los coeficientes de transformación reportados por Knight y Kvaran [16] y Markham [17] (Cuadro 1); así mismo, la conversión de radianza a reflectancia se realizó mediante la extensión FLAASH (Fast Line-of-sight Atmospheric Analysis of Spectral Hypercubes) del programa ENVI 5.1, eliminando los artefactos o “ruidos” que son causados a la señal que llega al satélite y son reflejados en la imagen.
Procesamiento de imágenes y clasificación
Categorías de estudio
Para la fase de entrenamiento se establecieron 10 categorías de estudio correspondientes a las coberturas de la tierra: bosque tardío, bosque intermedio, bosque temprano, bosque de galería, manglar, bosque seco enano, infraestructura, laguna, sombras o nubes y sabana-pasto (estas dos coberturas se incluyeron en una sola debido a que presentan baja discriminación entre ambas ya que los píxeles y las firmas espectrales eran muy similares).
Selección de áreas de entrenamiento
Para determinar las áreas de entrenamiento se utilizaron como referencia puntos de control de campo (GCP) georeferenciados de las coberturas de la tierra, que fueron colectados mediante equipo de posicionamiento global (GPS) Garmin GPSMAP 64. Un total de 220 GCP fueron colectados; mediante la herramienta puntos aleatorios del programa Quantum GIS 2.12 fueron seleccionados dedonde de forma aleatoria 110 (50%) GCP para ser utilizados como puntos de entrenamiento de los algoritmos de clasificación; los restantes 110 puntos se utilizaron para la validación de la clasificación. Mediante el programa ENVI 5.1, los 110 puntos de entrenamiento se proyectaron sobre la imagen satelital Landsat y alrededor de cada punto se recolectaron los valores de reflectancia en ventanas de 3x3 pixeles, centradas en el punto de entrenamiento (figura 2). Posteriormente, se evaluó la separabilidad de las muestras de entrenamiento mediante el índice Jeffries-Matusita.
Aplicación de algoritmos de clasificación supervisada
En la imagen corregida fueron implementados en ENVI 5.1 los algoritmos de clasificación Minimum Distance, Mahalanobies, Maximum Likelihood, Neural Network, Support Vector Machine y Parallelepiped utilizando como entrenamiento los 110 GCP seleccionados.
Validación de la clasificación
Basado en la precisión de productor, la precisión del usuario y el índice Kappa se validaron las categorías clasificadas mediante una matriz de error utilizando los 110 GCP reservados para la validación. Los valores del índice Kappa representan una medida de concordancia o precisión que toma rangos desde -1 a +1 [18]. Landis y Koch [19] caracterizaron los posibles rangos de precisión en tres grupos: mayor a 0.80 fuerte, 0.40-0.80, moderada y menor a 0.40 pobre.
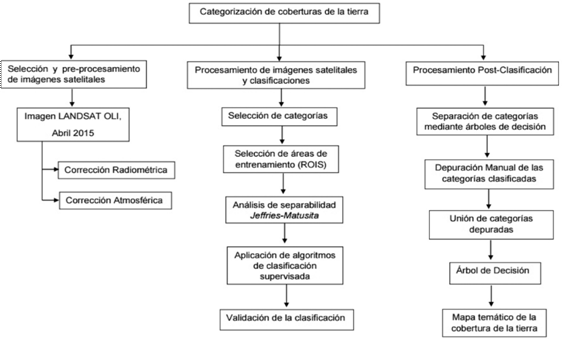
Proceso de post-clasificación
Árboles de Decisión
Se utilizó la técnica de clasificación árbol de decisión (Decision Tree Classifier) para separar todas las categorías clasificadas, a nivel individual (Figura 3a). Posteriormente, se depuró mediante fotointerpretación manual las categorías seleccionadas en el proceso de validación, eliminando las zonas que el algoritmo clasificó incorrectamente. Finalmente, se creó un nuevo árbol de forma jerárquica con todas las categorías depuradas (Figura 3b), dando como resultado un mapa temático final con las coberturas de la tierra del año 2015.
Resultados
Clasificación de cobertura de la tierra
Como resultado se obtuvieron 10 categorías de cobertura de la tierra (Figura 4): bosque de galería, bosque intermedio, bosque seco enano, bosque tardío, bosque temprano, infraestructura, laguna, sabana-pasto y sombras o nubes).
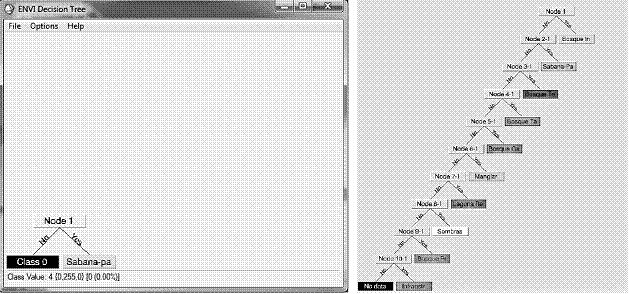
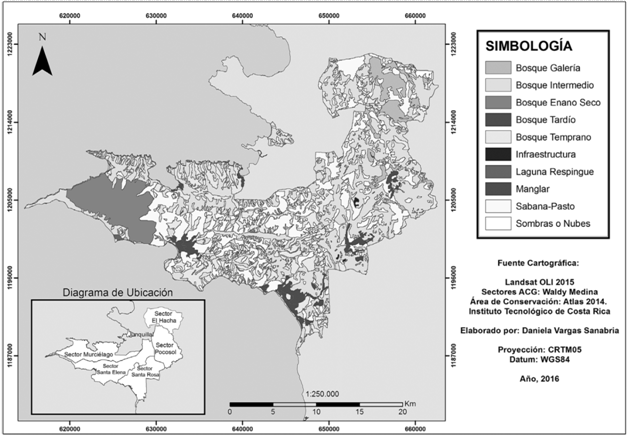
Figura 4 Mapa de cobertura de la tierra 2015 para los sectores del estudio del Área de Conservación Guanacaste.
Evaluación de la exactitud
La exactitud de la clasificación se evaluó de acuerdo al análisis de la matriz de error (Cuadro 2). Para las coberturas de bosque intermedio, bosque temprano, bosque tardío, bosque de galería y sabana-pasto los mejores resultados se obtuvieron con el algoritmo Maximum Likelihood. Por otro lado, la cobertura de manglar tuvo mejores resultados de clasificación con el algoritmo Neural Network. Con respecto a los algoritmos de Minimum Distance,Mahalanobis, Paralelepiped y Support Vector Machine no se obtuvo calidad en la clasificación de las coberturas.
A nivel de cobertura, sabana-pasto y manglar obtuvieron un mayor porcentaje en la exactitud del productor; mientras que las coberturas forestales (bosque tardío, bosque intermedio y bosque temprano) presentaron resultados iguales entre la exactitud del productor. Las coberturas correspondientes a infraestructura, nubes, bosque enano seco y laguna fueron clasificadas de forma manual y su validación se realizó con trabajo de campo y criterio experto, por lo tanto, no se tomaron en cuenta a la hora de realizar la validación por matriz de confusión.
A nivel de rendimiento del algoritmo en el Cuadro 3 se muestran los porcentajes obtenidos de la precisión y el índice kappa de los algoritmos de clasificación como resultado de la matriz de confusión. El algoritmo de Maximum Likelihood fue el que obtuvo mejores resultados en la clasificación de las coberturas con un 81.11% de precisión y un índice kappa de 0.77; mientras que el algoritmo de Neural Network obtuvo una precisión de 60.37% con un índice kappa de 0.54. En último lugar se encuentra el algoritmo Paralelepiped que no mostró buenos resultados en la clasificación de las coberturas obteniendo un 9.37% de precisión y un índice Kappa de 0.009. De acuerdo a la categorización sobre los rangos de precisión del índice Kappa realizada por Landis y Koch [19], los resultados obtenidos en la clasificación con los algoritmos Maximum Likelihood y Neural Network, responden a una precisión moderada.
Cuadro 2 Matriz de Confusión de algoritmos de clasificación supervisada
| Clasificador | Tipo de Cobertura | ||||||
| Exactitud | Bosque Tardío | Bosque Intermedio | Bosque Temprano | SabanaPasto | Bosque de Galería | Manglar | |
| Maximum Likelihood | Productor | 77.78% | 77.78% | 77.78% | 91.11% | 73.33% | 88.89 % |
| Usuario | 83.33% | 70.00% | 67.31% | 95.35% | 82.50% | 93.02 % | |
| Neural Network | Productor | 55.56% | 37.78% | 80.00% | 73.33% | 24.44% | 91.11 % |
| Usuario | 51.02% | 68.00% | 42.86% | 89.19% | 61.11% | 71.93 % | |
| Minimum Distance | Productor | 0.00% | 12.50% | 33.33% | 44.44% | 0.00% | 25.00 % |
| Usuario | 0.00% | 18.18% | 25.00% | 66.67% | 0.00% | 16.67 % | |
| Mahalanobis | Productor | 0.00% | 31.25% | 37.50% | 48.15% | 40.00% | 25.00 % |
| Usuario | 0.00% | 55.56% | 42.86% | 72.22% | 10.53% | 20.00 % | |
| Paralelepiped | Productor | 0.00% | 0.00% | 16.67% | 13.04% | 0.00% | 0.00 % |
| Usuario | 0.00% | 0.00% | 27.27% | 100% | 0.00% | 0.00 % | |
| Support Vector Machine | Productor | 0.00% | 12.50% | 36.00% | 37.71% | 0.00% | 33.33 % |
| Usuario | 0.00% | 28.57% | 27.27% | 66.67% | 0.00% | 40.00 % | |
Discusión
Los algoritmos de clasificación supervisada Maximum Likelihood y Neural Network, presentaron los mejores resultados en la clasificación de coberturas basados en puntos de control de campo. Lo que respalda que Maximum Likelihood sea utilizado de forma frecuente en teledetección [20], [21], [22]; ya que, es fácil de implementar. No obstante, en algunas ocasiones éste método puede fallar al identificar categorías de uso del suelo debido a que este clasificador asume una distribución normal de las categorías, ya que, toma en cuenta información espectral píxel a píxel utilizando solo una parte pequeña de la información contenida en la imagen [23], lo cual no necesariamente representa el comportamiento de las coberturas de la tierra a nivel de paisaje o gran escala [24].
Los resultados de la clasificación de la cobertura de manglar por el algoritmo Neural Network corroboran lo mencionado por Shafri, Suhaili y Mansor [25], que en la utilización de este algoritmo sucede una mayor precisión cuando el límite de decisión de distribución de píxeles de la categoría es menos definido, por lo general, cuando las categorías referentes a especies tienen menos separabilidad de forma espectral. Estudios recientes también plantean que la clasificación de imágenes satelitales con este algoritmo muchas veces presenta más ventajas con respecto a los clasificadores tradicionales, ya que, existe una mayor flexibilidad y adaptabilidad a los resultados debido a que presenta tolerancia ante niveles altos de información [26]. Sin embargo, para el caso de ciertas coberturas la discriminación de las muestras de áreas de entrenamiento se adecuan mejor a los clasificadores convencionales, así mismo influye la cantidad de bandas y categorías analizadas, ya que, si son muchas suelen dar resultados no tan precisos [9].
Los algoritmos basados en Minimum Distance se emplean con frecuencia por ser sencillos y rápidos de ejecutar, logrando asignar pixeles a una categoría cercana que logre minimizar la distancia entre el pixel y el centroide de la clase. No obstante, al existir una clase cercana y no dejar pixeles sin clasificación puede provocar errores de comisión [9]. Wacker y Landgrebe [27] precisan en que los problemas generados en la utilización de Minimum Distance se basan en la distribución de las clases y que en la clasificación de datos multiespectrales es frecuente que surjan dos inconvenientes: que las distribuciones que se encuentran asociadas a cualquier caso sean muy grandes, lo que impide intentar almacenar las distribuciones de subclases posibles y que las distribuciones de las diferentes clases sean a menudo muy similares, por lo que, el número de muestras requeridas para distinguirlas deberían ser muy grandes.
De acuerdo a Moreno [28] estos métodos tienen menos precisión que los métodos de Máximum Likelihood, debido a que Máximum Likelihood no presenta restricciones respecto a la cantidad de muestras utilizadas y suele adaptarse a la disposición original de los datos [9]. Sin embargo, cae en la simplicidad de algoritmos como Paralelepiped, donde el diseño de dominio de áreas de clasificación puede implicar que existan píxeles en zonas comunes a dos categorías o que los pixeles queden sin clasificar así mismo, lo que implica que puedan existir píxeles que se hayan asignado a varias clases [9].
Huang et al[29] reportaron que el algoritmo Support Vector Machine obtuvo valores crecientes en la precisión frente al aumento del tamaño de la muestra, en comparación con otros algoritmos. Sin embargo, este algoritmo no obtuvo mayor precisión en la asignación de píxeles a una categoría en nuestra investigación, pudiendo ser la causa el tamaño de los datos, lo que provocó que fueran insuficientes para la clasificación. Así mismo Plaza et al[30]mencionan que con un conjunto de entrenamiento limitado, la precisión de la clasificación tenderá a disminuir a medida que aumenta el número de características, aunque Argañarez y Entraigas [31] señalan que Support Vector Machine genera buenos resultados en la clasificación, aun cuando se cuenta con volúmenes de datos de entrenamiento pequeños. Foody y Mathur [32] plantean que debido al escaso número de muestras de entrenamiento y el gran número de características de las aplicaciones de teledetección, la estimación confiable de los parámetros de las clases estadísticas se vuelve una meta difícil.
La adaptación de la técnica de clasificación por Árbol de Decisión permitió solucionar algunos problemas obtenidos en la implementación del sistema de clasificación de las coberturas por los algoritmos Maximum Likelihood y Neural Network. Así mismo, se logró incluir otras categorías mediante el árbol las categorías de bosque seco enano, laguna, nubes o sombras e infraestructura que se habían digitalizado y validado de forma manual. Pal y Mather [33] refuerzan esta tendencia de utilizar herramientas alternativas como Árboles de Decisión para solucionar problemas generados por algoritmos a la hora de discriminar clases debido a que clasifican de forma más eficiente los datos. No obstante, el éxito de una clasificación de imágenes satelitales depende de factores como la disponibilidad del número de muestras, la alta calidad de las imágenes, el diseño del sistema de clasificación y las habilidades y experiencia del analista [34 ].
Conclusiones
La clasificación de tipos de cobertura de la tierra por medio de imágenes satelitales en el bosque seco tropical puede presentar limitaciones por factores como la resolución (espacial, espectral, temporal y radiométrica), condiciones atmosféricas, estructura y composición de la vegetación, paisaje y tamaño de la muestra de datos, sin embargo, la metodología aplicada en el estudio de un sistema multi-algoritmo apuntó a una mejora en la clasificación de imágenes de satélite generando información con mayor exactitud y disminuyendo algunos errores que se derivan de la clasificación. El estudio demostró que es posible utilizar un sistema multi-algoritmo para mejorar la clasificación de categorías, logrando identificar y separar de manera más eficiente los tipos de cobertura de la tierra presentes en seis sectores del Área de Conservación Guanacaste.